[整理]Unicode 与 UTF8
目录
先上总结
Unicode 是一个符号集, 规定了所有符号的二进制编号.
UTF8 是unicode的一种编码方式(存储, 传输方式)
参考: http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
ASCII
ascii码范围: 1~128, 只需要1个字节, 最前面的一位固定为 0
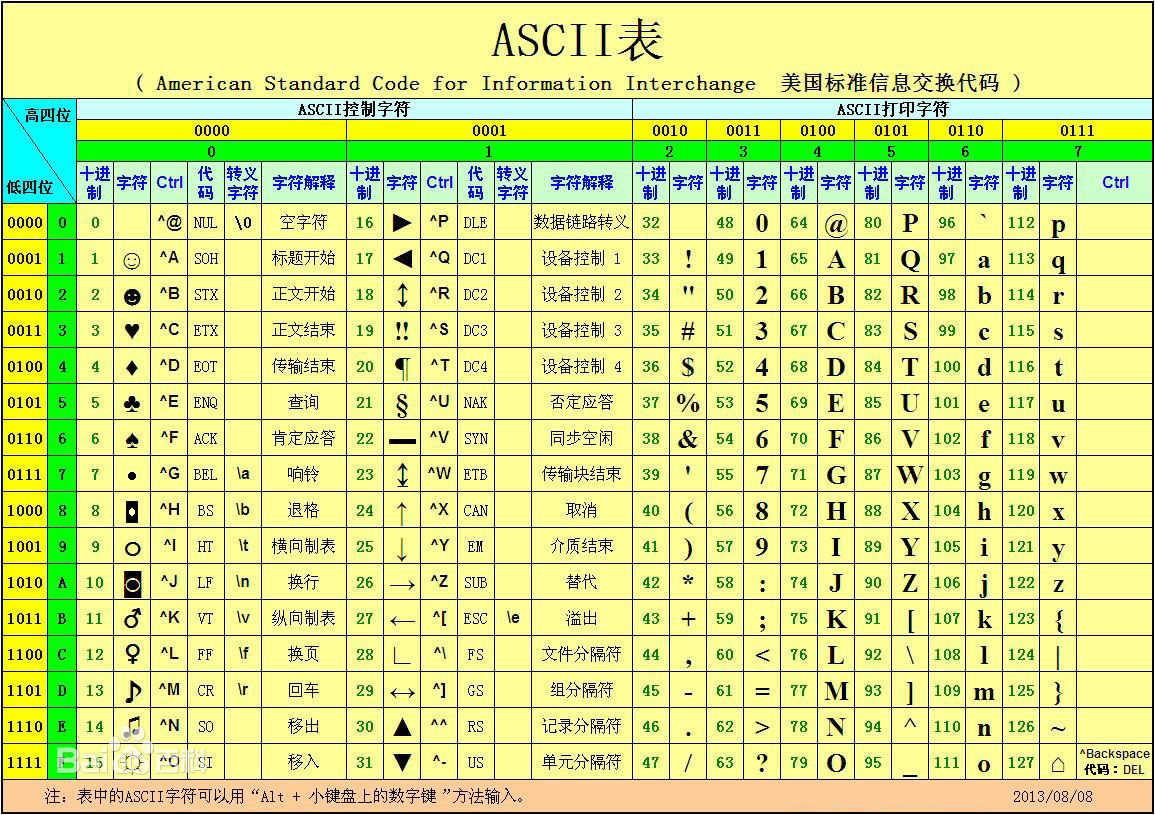
unicode 编码占用3个字节, 它包含了所有的字符
Unicode 只是一个符号集,它只规定了符号的二进制代码,没有规定这个二进制代码如何存储。
存储Unicode的编码方式的常用方式:
utf-8 变长编码, 长度从 1个字节~6个字节不等
utf-16 占用2个字节
utf-32 占用4个字节
utf-8 编码规则
- 对于单字节的符号,字节的第一位设为
0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。 - 对于
n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
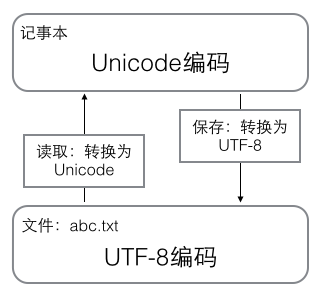
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
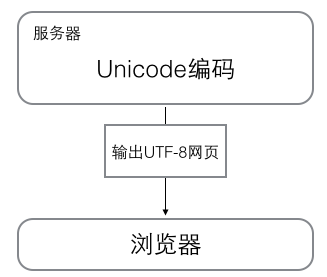
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
作者:Deft_MKJing宓珂璟
来源:CSDN
原文:https://blog.csdn.net/Deft_MKJing/article/details/79460485
版权声明:本文为博主原创文章,转载请附上博文链接!
UTF-16
字节顺序标记(Byte Order Mark, BOM), 位于文档开头的前2个字节, 用于标记存储的字节序, 是按 "大端"还是"小端"顺序存储.
借个图(UTF8你 的utf8编码存储文件内容):

feff 表示内容是按大端序存储: 高位字节放在内存的低地址,低位字节放在内存的高地址
fffe表示内容是按小端序存储:低位字节放在内存的低地址,高位字节放在内存的高地址。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF
U 的UTF16编码是 0055, 但按照小端序存储时是 5500
注意, utf8并没有这个烦恼, 不要搞乱.
在UTF16下,存储的字节值和unicode是一一对应的。但是UTF16显示英文(asni)就浪费一个字节。
其他
英文字符编码 ANSI
简体中文 GB2312
繁体中文 Big5
[整理]Unicode 与 UTF8的更多相关文章
- 字符编码笔记:ASCII,Unicode和UTF-8 转
本文出处 http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html 只是为了记录一下省得要去搜. 今天中午,我突然想搞清楚 ...
- [转]字符编码笔记:ASCII,Unicode和UTF-8
转自:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html 作者: 阮一峰 日期: 2007年10月28日 今天中午, ...
- 字符编码笔记:ASCII,Unicode和UTF-8(转载)
作者: 阮一峰 日期: 2007年10月28日 今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问题比我想象的复杂,从午饭后一直看到晚上9点,才算初步 ...
- 关于几种编码详解(Unicode,UTF-8,GB系列)
最近学Python,老是被编码的问题搞得晕乎乎的,晚上看了好多篇博客,整理出来一个比较清晰的关于几种编码以及字符集的思路. 主要参考:http://blog.sina.com.cn/s/blog_6d ...
- 各种编码UNICODE、UTF-8、ASCII学习笔记
本文转自csdn博客:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html ,感谢作者的分享 作者: 阮一峰 日期: ...
- 字符编码-UNICODE,GBK,UTF-8区别【转转】
字符编码介绍及不同编码区别 今天看到这篇关于字符编码的文章,抑制不住喜悦(总结的好详细)所以转到这里来.转自:祥龙之子http://www.cnblogs.com/cy163/archive/2007 ...
- 字符编码笔记:ASCII,Unicode和UTF-8【转载】
作者: 阮一峰 日期: 2007年10月28日 今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问题比我想象的复杂,从午饭后一直看到晚上9点,才算初步 ...
- ASCII,Unicode和UTF-8
转自:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html 今天中午,我突然想搞清楚Unicode和UTF-8之间的关 ...
- 【转】字符编码笔记:ASCII,Unicode和UTF-8
今天整理笔记,关于NSString转NSData时,什么时候使用NSUTF8StringEncoding,或者NSASCIIStringEncoding,或者 NSUnicodeStringEncod ...
随机推荐
- A simple way to crack VBA password in Excel file
Unbelivibale, but I found a very simple way that really works! Do the follwoing: 1. Create a new sim ...
- 1.oracle dblink(数据库不同实例数据对导)
.创建一个两个数据库之间的dblink,语法如下 create database link to_test connect to scott identified by tiger using '(D ...
- Python中的排序方法sort(),sorted(),argsort()等
python 列表排序方法sort.sorted技巧篇 转自https://www.cnblogs.com/whaben/p/6495702.html,学习参考. Python list内置sort( ...
- ScreenCapture-HDwik5.0整合教程
示例下载:http://yunpan.cn/Q9qzFmf6sF57z 1.上传ScreenCapture文件夹 2.上传upload.php文件 2.1修改upload.php路径 3.修改Scre ...
- pcd转obj
文件转换 从PCD文件写入和读取点云数据:https://www.cnblogs.com/li-yao7758258/p/6435568.html 点云数据格式PCD(Point Cloud Data ...
- FlexBox弹性盒布局
网页布局(layout)是 CSS 的一个重点应用. 布局的传统解决方案,基于盒状模型,依赖 display 属性 + position属性 + float属性.它对于那些特殊布局非常不方便,比如,垂 ...
- How to extract msu/msp/msi/exe files from the command line
http://www.windowswiki.info/2009/02/19/how-to-extract-msumspmsiexe-files-from-the-command-line/ Micr ...
- SSH案例--入门级
1.项目功能展示 (1)注册 (2)修改地址与级别信息,点击修改 (3)再添加一位成员,进行删除 点击第二行的删除 (4)登录模块测试 输入数据库中没有的信息: 输入数据库中存在的信息: 2. W ...
- win10 数字许可证激活被 KMS激活覆盖
打开cmd(管理员身份),依次执行以下命令: slmgr/upk slmgr/ckms slmgr/rearm 重启设备后联网登录Microsoft账号,转设置-激活-疑难解答,windows会找到与 ...
- C语言/C++编程学习:和QT零距离接触的意义
C语言是面向过程的,而C++是面向对象的 C和C++的区别: C是一个结构化语言,它的重点在于算法和数据结构.C程序的设计首要考虑的是如何通过一个过程,对输入(或环境条件)进行运算处理得到输出(或实现 ...