Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求,使得我们的爬虫更强大、更高效。
熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析。同时,使用Weka 3.7工具,对所获取得到的数据进行数据挖掘分析操作。
一、项目分析
本次的实验内容要求使用scrapy框架,爬取腾讯招聘官网中网页(https://hr.tencent.com/position.php?&start=0)上所罗列的招聘信息,如:其中的职位名称、链接、职位类别、人数、地点和发布时间。并且将所爬取的内容保存输出为CSV和JSON格式文件,在python程序代码中要求将所输出显示的内容进行utf-8类型编码。
1. 网页分析
在本例实验开始之前,需要对所要求爬取的腾讯招聘网页进行网页分析,其中(https://hr.tencent.com/position.php?&start=0)的界面布局结构可如图2-1所示:
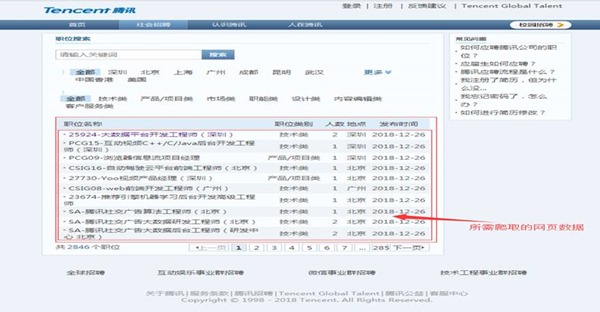
图1-1 所要爬取的信息页面布局
使用xpath_helper_2_0_2辅助工具,对其中招聘信息的职位名称、链接、职位类别、人数、地点和发布时间等信息内容进行xpath语法分析如下:
职位名称: //td[@class='l square']/a/text()
链 接: //td[@class='l square']/a/@href
职位类别://tr[@class='odd']/td[2]/text()|//tr[@class='even']/td[2]/text()
人 数://tr[@class='odd']/td[3]/text()|//tr[@class='even']/td[3]/text()
地 点://tr[@class='odd']/td[4]/text()|//tr[@class='even']/td[4]/text()
发布时间://tr[@class='odd']/td[5]/text()|//tr[@class='even']/td[5]/text()
2. url分析
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。
首先程序将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。在Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares交给Downloader,再向互联网发送请求,并接收下载响应(response)。
最后,将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders的同时。Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存,提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
二、项目工具
实验软件:Python 3.7.1 、 JetBrains PyCharm 2018.3.2 、 其它辅助工具:略
三、项目过程
(一)使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析,绘制如图3-1所示的程序逻辑框架图
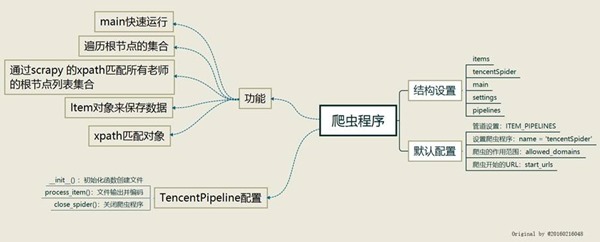
图3-1 程序逻辑框架图
(二)爬虫程序调试过程BUG描述(截图)
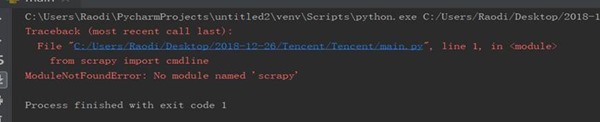
图3-2 爬虫程序BUG描述①

图3-3 爬虫程序BUG描述②
(三)爬虫运行结果
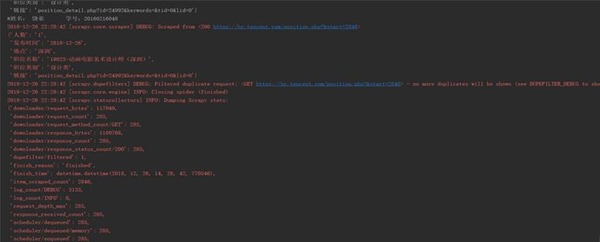
图3-4 爬虫程序输出运行结果1
图3-5 爬虫程序输出文件
四、项目心得
关于本例实验心得可总结如下:
1、 解决图3-4的程序错误,只需在gec.py的文件中进行导入操作:from Tencent.items import TencentItem 即可。对于解决如图4-1所示的内容,请如图5-1所示:
图4-1 程序错误纠正
2、 spider打开某网页,获取到一个或者多个request,经由scrapy engine传送给调度器scheduler request特别多并且速度特别快会在scheduler形成请求队列queue,由scheduler安排执行
3、 schelduler会按照一定的次序取出请求,经由引擎, 下载器中间键,发送给下载器dowmloader 这里的下载器中间键是设定在请求执行前,因此可以设定代理,请求头,cookie等
4、 下载下来的网页数据再次经过下载器中间键,经过引擎,经过爬虫中间键传送给爬虫spiders 这里的下载器中间键是设定在请求执行后,因此可以修改请求的结果 这里的爬虫中间键是设定在数据或者请求到达爬虫之前,与下载器中间键有类似的功能
5、 由爬虫spider对下载下来的数据进行解析,按照item设定的数据结构经由爬虫中间键,引擎发送给项目管道itempipeline 这里的项目管道itempipeline可以对数据进行进一步的清洗,存储等操作 这里爬虫极有可能从数据中解析到进一步的请求request,它会把请求经由引擎重新发送给调度器shelduler,调度器循环执行上述操作
Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计的更多相关文章
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
- Scrapy项目 - 项目源码 - 实现腾讯网站社会招聘信息爬取的爬虫设计
1.tencentSpider.py # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentItem #创建爬虫 ...
- Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等.熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析. 一.项目 ...
- Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 数据简析 - 实现斗鱼直播网站信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 2-3个图,作业文字描述) 本次将所爬取的数据信息,如:房间数,直播类别和人气,导入Weka 3.7工具进行数据分析.有关本次的数据分析详情详见下图所示: ...
- Scrapy项目 - 源码工程 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.项目目录结构 spiders文件夹内包含doubanSpider.py文件,对于项目的构建以及结构逻辑,详见环境搭建篇. 二.项目源码 1.doubanSpider.py # -*- coding ...
- Scrapy项目 - 数据简析 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 ) 本例实验,使用Weka 3.7对豆瓣电影网页上所罗列的上映电影信息,如:标题.主要信息(年份.国家.类型)和评分等的信息进行数据分析,Weka 3.7数据分 ...
- Scrapy案例02-腾讯招聘信息爬取
目录 1. 目标 2. 网站结构分析 3. 编写爬虫程序 3.1. 配置需要爬取的目标变量 3.2. 写爬虫文件scrapy 3.3. 编写yield需要的管道文件 3.4. setting中配置请求 ...
- Scrapy项目 - 实现百度贴吧帖子主题及图片爬取的爬虫设计
要求编写的程序可获取任一贴吧页面中的帖子链接,并爬取贴子中用户发表的图片,在此过程中使用user agent 伪装和轮换,解决爬虫ip被目标网站封禁的问题.熟悉掌握基本的网页和url分析,同时能灵活使 ...
随机推荐
- Java 从入门到进阶之路(四)
之前的文章我们介绍了 Java 的运算符和表达式,本章我们来看一下 Java 的循环结构. 循环是程序设计语言中反复执行某些代码的一种计算机处理过程,是一组相同或相似语句被有规律的重复性进行. 循环的 ...
- Redis学习总结(五)--Redis集群创建
在之前我们讲到了主从,但是对于大数据量的场景下我们就需要用到集群了,让我们来了解下集群吧. 为什么需要集群 单机内存太小 redis最高可以达到10万/s 请求,如果超过该频率呢? 数据分布方式 数据 ...
- js获取Cookie,获取url参数
function getCookie(name) { var strCookie = document.cookie; var arrCookie = strCookie.split("; ...
- javaio字节流复制文件夹
public class Copy1 { public static void main(String[] args) throws IOException { File src=new File(& ...
- 【第一篇】spring boot 快速入门
1.开发环境 开发工具:IDEA2018.2.1 JDK:1.9 Maven : 3.3.9 操作系统:window 7 / window 10 2.项目结构 3.详细步骤 3.1 使用IDEA新建M ...
- C#开发BIMFACE系列3 服务端API之获取应用访问凭证AccessToken
系列目录 [已更新最新开发文章,点击查看详细] BIMFACE 平台为开发者提供了大量的服务器端 API 与 JavaScript API,用于二次开发 BIM 的相关应用. BIMFACE ...
- 简明Python教程-函数联系笔记
1.实参与形参 在定义函数时给定的名称称作"形参",再调用函数时你所提供给函数的值称作“实参” 2.局部变量 所有变量的作用域是它们被定义的块,从定义它们的名字的定义点开始. 3. ...
- Team Train Recorder
2014-2015 Petrozavodsk Winter Training Camp, Contest.58 (Makoto rng_58 Soejima contest) contest link ...
- 2018年全国多校算法寒假训练营练习比赛(第五场)H Tree Recovery
Tree Recovery 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 131072K,其他语言262144K 64bit IO Format: %lld 链接:https://w ...
- Prometheus安装
Prometheus安装 下载地址: https://prometheus.io/download/ 现在时间是: 2019.09.07 安装环境: Linux centos7 minimal 虚拟机 ...