Debezium SQL Server Source Connector+Kafka+Spark+MySQL 实时数据处理
写在前面
前段时间在实时获取SQLServer数据库变化时候,整个过程可谓是坎坷。然后就想在这里记录一下。
本文的技术栈: Debezium SQL Server Source Connector+Kafka+Spark+MySQL
ps:后面应该会将数据放到Kudu上。
然后主要记录一下,整个组件使用和组件对接过程中一些注意点和坑。
开始吧
在处理实时数据时,需要即时地获得数据库表中数据的变化,然后将数据变化发送到Kafka中。不同的数据库有不同的组件进行处理。
常见的MySQL数据库,就有比较多的支持 canal ,maxwell等,他们都是类似 MySQL binlog 增量订阅&消费组件这种模式 。那么关于微软的SQLServer数据库,好像整个开源社区 支持就没有那么好了。
1.选择Connector
Debezium的SQL Server连接器是一种源连接器,可以获取SQL Server数据库中现有数据的快照,然后监视和记录对该数据的所有后续行级更改。每个表的所有事件都记录在单独的Kafka Topic中,应用程序和服务可以轻松使用它们。然后本连接器也是基于MSSQL的change data capture实现。
2.安装Connector
我参照官方文档安装是没有问题的。
2.1 Installing Confluent Hub Client
Confluent Hub客户端本地安装为Confluent Platform的一部分,位于/ bin目录中。
Linux
Download and unzip the Confluent Hub tarball.
[root@hadoop001 softs]# ll confluent-hub-client-latest.tar
-rw-r--r--. 1 root root 6909785 9月 24 10:02 confluent-hub-client-latest.tar
[root@hadoop001 softs]# tar confluent-hub-client-latest.tar -C ../app/conn/
[root@hadoop001 softs]# ll ../app/conn/
总用量 6748
drwxr-xr-x. 2 root root 27 9月 24 10:43 bin
-rw-r--r--. 1 root root 6909785 9月 24 10:02 confluent-hub-client-latest.tar
drwxr-xr-x. 3 root root 34 9月 24 10:05 etc
drwxr-xr-x. 2 root root 6 9月 24 10:08 kafka-mssql
drwxr-xr-x. 4 root root 29 9月 24 10:05 share
[root@hadoop001 softs]#
配置bin目录到系统环境变量中
export CONN_HOME=/root/app/conn
export PATH=$CONN_HOME/bin:$PATH
确认是否安装成功
[root@hadoop001 ~]# source /etc/profile
[root@hadoop001 ~]# confluent-hub
usage: confluent-hub <command> [ <args> ]
Commands are:
help Display help information
install install a component from either Confluent Hub or from a local file
See 'confluent-hub help <command>' for more information on a specific command.
[root@hadoop001 ~]#
2.2 Install the SQL Server Connector
使用命令confluent-hub
[root@hadoop001 ~]# confluent-hub install debezium/debezium-connector-sqlserver:0.9.4
The component can be installed in any of the following Confluent Platform installations:
1. / (installed rpm/deb package)
2. /root/app/conn (where this tool is installed)
Choose one of these to continue the installation (1-2): 2
Do you want to install this into /root/app/conn/share/confluent-hub-components? (yN) n
Specify installation directory: /root/app/conn/share/java/confluent-hub-client
Component's license:
Apache 2.0
https://github.com/debezium/debezium/blob/master/LICENSE.txt
I agree to the software license agreement (yN) y
You are about to install 'debezium-connector-sqlserver' from Debezium Community, as published on Confluent Hub.
Do you want to continue? (yN) y
注意:Specify installation directory:这个安装目录最好是你刚才的confluent-hub 目录下的 /share/java/confluent-hub-client 这个目录下。其余的基本操作就好。
3.配置Connector
首先需要对Connector进行配置,配置文件位于 $KAFKA_HOME/config/connect-distributed.properties:
# These are defaults. This file just demonstrates how to override some settings.
# kafka集群地址,我这里是单节点多Broker模式
bootstrap.servers=haoop001:9093,hadoop001:9094,hadoop001:9095
# Connector集群的名称,同一集群内的Connector需要保持此group.id一致
group.id=connect-cluster
# The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will
# need to configure these based on the format they want their data in when loaded from or stored into Kafka
# 存储到kafka的数据格式
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
# The internal converter used for offsets and config data is configurable and must be specified, but most users will
# 内部转换器的格式,针对offsets、config和status,一般不需要修改
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
# Topic to use for storing offsets. This topic should have many partitions and be replicated.
# 用于保存offsets的topic,应该有多个partitions,并且拥有副本(replication),主要根据你的集群实际情况来
# Kafka Connect会自动创建这个topic,但是你可以根据需要自行创建
offset.storage.topic=connect-offsets-2
offset.storage.replication.factor=3
offset.storage.partitions=1
# 保存connector和task的配置,应该只有1个partition,并且有3个副本
config.storage.topic=connect-configs-2
config.storage.replication.factor=3
# 用于保存状态,可以拥有多个partition和replication
# Topic to use for storing statuses. This topic can have multiple partitions and should be replicated.
status.storage.topic=connect-status-2
status.storage.replication.factor=3
status.storage.partitions=1
offset.storage.file.filename=/root/data/kafka-logs/offset-storage-file
# Flush much faster than normal, which is useful for testing/debugging
offset.flush.interval.ms=10000
# REST端口号
rest.port=18083
# 保存connectors的路径
#plugin.path=/root/app/kafka_2.11-0.10.1.1/connectors
plugin.path=/root/app/conn/share/java/confluent-hub-client
4.创建kafka Topic
我这里是单节点多Broker模式的Kafka,那么创建Topic可以如下:
kafka-topics.sh --zookeeper hadoop001:2181 --create --topic connect-offsets-2 --replication-factor 3 --partitions 1
kafka-topics.sh --zookeeper hadoop001:2181 --create --topic connect-configs-2 --replication-factor 3 --partitions 1
kafka-topics.sh --zookeeper hadoop001:2181 --create --topic connect-status-2 --replication-factor 3 --partitions 1
查看状态 <很重要>
[root@hadoop001 ~]# kafka-topics.sh --describe --zookeeper hadoop001:2181 --topic connect-offsets-2
Topic:connect-offsets-2 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: connect-offsets-2 Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
[root@hadoop001 ~]# kafka-topics.sh --describe --zookeeper hadoop001:2181 --topic connect-configs-2
Topic:connect-configs-2 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: connect-configs-2 Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
[root@hadoop001 ~]# kafka-topics.sh --describe --zookeeper hadoop001:2181 --topic connect-status-2
Topic:connect-status-2 PartitionCount:1 ReplicationFactor:3 Configs:
Topic: connect-status-2 Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
[root@hadoop001 ~]#
5.开启SqlServer Change Data Capture(CDC)更改数据捕获
变更数据捕获用于捕获应用到 SQL Server 表中的插入、更新和删除活动,并以易于使用的关系格式提供这些变更的详细信息。变更数据捕获所使用的更改表中包含镜像所跟踪源表列结构的列,同时还包含了解所发生的变更所需的元数据。变更数据捕获提供有关对表和数据库所做的 DML 更改的信息。通过使用变更数据捕获,您无需使用费用高昂的方法,如用户触发器、时间戳列和联接查询等。
数据变更历史表会随着业务的持续,变得很大,所以默认情况下,变更数据历史会在本地数据库保留3天(可以通过视图msdb.dbo.cdc_jobs的字段retention来查询,当然也可以更改对应的表来修改保留时间),每天会通过SqlServer后台代理任务,每天晚上2点定时删除。所以推荐定期的将变更数据转移到数据仓库中。
以下命令基本就够用了
--查看数据库是否起用CDC
GO
SELECT [name], database_id, is_cdc_enabled
FROM sys.databases
GO
--数据库起用CDC
USE test1
GO
EXEC sys.sp_cdc_enable_db
GO
--关闭数据库CDC
USE test1
go
exec sys.sp_cdc_disable_db
go
--查看表是否启用CDC
USE test1
GO
SELECT [name], is_tracked_by_cdc
FROM sys.tables
GO
--启用表的CDC,前提是数据库启用
USE Demo01
GO
EXEC sys.sp_cdc_enable_table
@source_schema = 'dbo',
@source_name = 'user',
@capture_instance='user',
@role_name = NULL
GO
--关闭表上的CDC功能
USE test1
GO
EXEC sys.sp_cdc_disable_table
@source_schema = 'dbo',
@source_name = 'user',
@capture_instance='user'
GO
--可能不记得或者不知道开启了什么表的捕获,返回所有表的变更捕获配置信息
EXECUTE sys.sp_cdc_help_change_data_capture;
GO
--查看对某个实例(即表)的哪些列做了捕获监控:
EXEC sys.sp_cdc_get_captured_columns
@capture_instance = 'user'
--查找配置信息 -retention 变更数据保留的分钟数
SELECT * FROM test1.dbo.cdc_jobs
--更改数据保留时间为分钟
EXECUTE sys.sp_cdc_change_job
@job_type = N'cleanup',
@retention=1440
GO
--停止捕获作业
exec sys.sp_cdc_stop_job N'capture'
go
--启动捕获作业
exec sys.sp_cdc_start_job N'capture'
go
6.运行Connector
怎么运行呢?参照
[root@hadoop001 bin]# pwd
/root/app/kafka_2.11-1.1.1/bin
[root@hadoop001 bin]# ./connect-distributed.sh
USAGE: ./connect-distributed.sh [-daemon] connect-distributed.properties
[root@hadoop001 bin]#
[root@hadoop001 bin]# ./connect-distributed.sh ../config/connect-distributed.properties
... 这里就会有大量日志输出
验证:
[root@hadoop001 ~]# netstat -tanp |grep 18083
tcp6 0 0 :::18083 :::* LISTEN 29436/java
[root@hadoop001 ~]#
6.1 获取Worker的信息
ps:可能你需要安装jq这个软件: yum -y install jq ,当然可以在浏览器上打开
[root@hadoop001 ~]# curl -s hadoop001:18083 | jq
{
"version": "1.1.1",
"commit": "8e07427ffb493498",
"kafka_cluster_id": "dmUSlNNLQ9OyJiK-bUc6Tw"
}
[root@hadoop001 ~]#
6.2 获取Worker上已经安装的Connector
[root@hadoop001 ~]# curl -s hadoop001:18083/connector-plugins | jq
[
{
"class": "io.debezium.connector.sqlserver.SqlServerConnector",
"type": "source",
"version": "0.9.5.Final"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"type": "sink",
"version": "1.1.1"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"type": "source",
"version": "1.1.1"
}
]
[root@hadoop001 ~]#
可以看见io.debezium.connector.sqlserver.SqlServerConnector 这个是我们自己刚才安装的连接器
6.3 列出当前运行的connector(task)
[root@hadoop001 ~]# curl -s hadoop001:18083/connectors | jq
[]
[root@hadoop001 ~]#
6.4 提交Connector用户配置 《重点》
当提交用户配置时,就会启动一个Connector Task,
Connector Task执行实际的作业。
用户配置是一个Json文件,同样通过REST API提交:
curl -s -X POST -H "Content-Type: application/json" --data '{
"name": "connector-mssql-online-1",
"config": {
"connector.class" : "io.debezium.connector.sqlserver.SqlServerConnector",
"tasks.max" : "1",
"database.server.name" : "test1",
"database.hostname" : "hadoop001",
"database.port" : "1433",
"database.user" : "sa",
"database.password" : "xxx",
"database.dbname" : "test1",
"database.history.kafka.bootstrap.servers" : "hadoop001:9093",
"database.history.kafka.topic": "test1.t201909262.bak"
}
}' http://hadoop001:18083/connectors
马上查看connector当前状态,确保状态是RUNNING
[root@hadoop001 ~]# curl -s hadoop001:18083/connectors/connector-mssql-online-1/status | jq
{
"name": "connector-mssql-online-1",
"connector": {
"state": "RUNNING",
"worker_id": "xxx:18083"
},
"tasks": [
{
"state": "RUNNING",
"id": 0,
"worker_id": "xxx:18083"
}
],
"type": "source"
}
[root@hadoop001 ~]#
此时查看Kafka Topic
[root@hadoop001 ~]# kafka-topics.sh --list --zookeeper hadoop001:2181
__consumer_offsets
connect-configs-2
connect-offsets-2
connect-status-2
#自动生成的Topic, 记录表结构的变化,生成规则:你的connect中自定义的
test1.t201909262.bak
[root@hadoop001 ~]#
再次列出运行的connector(task)
[root@hadoop001 ~]# curl -s hadoop001:18083/connectors | jq
[
"connector-mssql-online-1"
]
[root@hadoop001 ~]#
6.5 查看connector的信息
[root@hadoop001 ~]# curl -s hadoop001:18083/connectors/connector-mssql-online-1 | jq
{
"name": "connector-mssql-online-1",
"config": {
"connector.class": "io.debezium.connector.sqlserver.SqlServerConnector",
"database.user": "sa",
"database.dbname": "test1",
"tasks.max": "1",
"database.hostname": "hadoop001",
"database.password": "xxx",
"database.history.kafka.bootstrap.servers": "hadoop001:9093",
"database.history.kafka.topic": "test1.t201909262.bak",
"name": "connector-mssql-online-1",
"database.server.name": "test1",
"database.port": "1433"
},
"tasks": [
{
"connector": "connector-mssql-online-1",
"task": 0
}
],
"type": "source"
}
[root@hadoop001 ~]#
6.6 查看connector下运行的task信息
[root@hadoop001 ~]# curl -s hadoop001:18083/connectors/connector-mssql-online-1/tasks | jq
[
{
"id": {
"connector": "connector-mssql-online-1",
"task": 0
},
"config": {
"connector.class": "io.debezium.connector.sqlserver.SqlServerConnector",
"database.user": "sa",
"database.dbname": "test1",
"task.class": "io.debezium.connector.sqlserver.SqlServerConnectorTask",
"tasks.max": "1",
"database.hostname": "hadoop001",
"database.password": "xxx",
"database.history.kafka.bootstrap.servers": "hadoop001:9093",
"database.history.kafka.topic": "test1.t201909262.bak",
"name": "connector-mssql-online-1",
"database.server.name": "test1",
"database.port": "1433"
}
}
]
[root@hadoop001 ~]#
task的配置信息继承自connector的配置
6.7 暂停/重启/删除 Connector
# curl -s -X PUT hadoop001:18083/connectors/connector-mssql-online-1/pause
# curl -s -X PUT hadoop001:18083/connectors/connector-mssql-online-1/resume
# curl -s -X DELETE hadoop001:18083/connectors/connector-mssql-online-1
7.从Kafka中读取变动数据
# 记录表结构的变化,生成规则:你的connect中自定义的
kafka-console-consumer.sh --bootstrap-server hadoop001:9093 --topic test1.t201909262.bak --from-beginning
# 记录数据的变化,生成规则:test1.dbo.t201909262
kafka-console-consumer.sh --bootstrap-server hadoop001:9093 --topic test1.dbo.t201909262 --from-beginning
这里就是:
kafka-console-consumer.sh --bootstrap-server hadoop001:9093 --topic test1.dbo.t201909262 --from-beginning
kafka-console-consumer.sh --bootstrap-server hadoop001:9093 --topic test1.dbo.t201909262
8. 对表进行 DML语句 操作
新增数据:
然后kafka控制台也就会马上打出日志
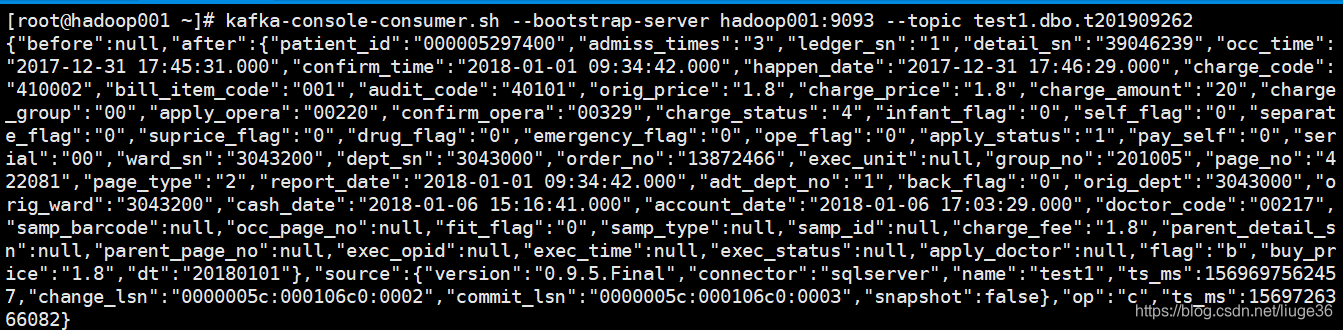
spark 对接kafka 10s一个批次

然后就会将这个新增的数据插入到MySQL中去
具体的处理逻辑后面再花时间来记录一下
修改和删除也是OK的,就不演示了
有任何问题,欢迎留言一起交流~~
更多好文:https://blog.csdn.net/liuge36
参考文章:
https://docs.confluent.io/current/connect/debezium-connect-sqlserver/index.html#sqlserver-source-connector
https://docs.microsoft.com/en-us/sql/relational-databases/track-changes/track-data-changes-sql-server?view=sql-server-2017
https://blog.csdn.net/qq_19518987/article/details/89329464
http://www.tracefact.net/tech/087.html
Debezium SQL Server Source Connector+Kafka+Spark+MySQL 实时数据处理的更多相关文章
- SQL Server CDC配合Kafka Connect监听数据变化
写在前面 好久没更新Blog了,从CRUD Boy转型大数据开发,拉宽了不少的知识面,从今年年初开始筹备.组建.招兵买马,到现在稳定开搞中,期间踏过无数的火坑,也许除了这篇还很写上三四篇. 进入主题, ...
- debezium sql server 集成
debezium 是一个方便的cdc connector 可以帮助我们解决好多数据实时变更处理.数据分析.微服务的数据通信 从上次跑简单demo到现在,这个工具是有好多的变更,添加了好多方便的功能,支 ...
- SQL Server 用链接服务器 同步MySQL
--测试环境SQL 2014 在MySql环境: use test ; Create Table Demo(ID int,Name varchar(50)) 在控制面板—管理工具—数据源(ODBC)— ...
- SQL SERVER 创建远程数据库链接 mysql oracle sqlserver
遇到的坑 在连接Oracle时,因为服务器为10g 32位版本,然后在本地安装了32为10g客户端,然后一直报错[7302.7303],后来下载了12c 64位版本,安装成功后,问题解决 原因:mss ...
- 使用 Navicat Premium 将 sql server 的数据库迁移到 mysql 的数据库中
步骤1,打开 Navicat Premium ,创建一个新的 mysql 数据库: 步骤2,选中刚刚创建的新数据库 ,双击选中后点击导入向导,然后选择 "ODBC",并点击下一步 ...
- 将Microsoft SQL Server 2000数据库转换成MySQL数据库
1. 下载并安装MyODBC.(如果是XP请下载5.3的旧版本,8.x的新版本运行有问题) 2. 创建一个空的MySQL数据库. 3. 在Windows >> 控制面板 >> ...
- sql server 数据库 数据DateTime 转mysql
首先将sql server DateTime 转换为varchar(50) 然后更新转换过的 DateTime字段, UPDATE 表名 SET LastUpdateTime=CONVERT(VAR ...
- SQL Server 2008通过LinkServer连接MySQL
链接过程就不过多描述了,搜索下都有一大堆的内容. 链接成功以后,如何调用的问题,通过“编写select脚本”的方式生成的脚本如下: [备注:asset_manager是数据库名,admin是表名] - ...
- SQL Server访问MySql
使用环境:操作系统:window7数据库:SQL Server2005.MySql5.01.在安装了SQL Server的服务器上安装MySql的ODBC驱动:下载链接:http://dev.mysq ...
随机推荐
- Scala 系列(八)—— 类和对象
一.初识类和对象 Scala 的类与 Java 的类具有非常多的相似性,示例如下: // 1. 在 scala 中,类不需要用 public 声明,所有的类都具有公共的可见性 class Person ...
- Python之读取用户指令和格式化打印
Python之读取用户指令和格式化打印 一.读取用户指令 当你的程序要接收用户输入的指令时,可以用input函数: name = input("请输入你的名字:") print(& ...
- .gitignore不起作用,过滤规则
git 通过配置.gitignore文件忽略掉的文件或目录,在.gitignore文件中的每一行保存一个匹配的规则 # 此为注释 – 将被 Git 忽略 *.a :忽略所有 .a 结尾的文件 !lib ...
- Nacos整合Spring Cloud Gateway组件
一.什么是Spring Cloud Gateway Spring Cloud Gateway是Spring Cloud官方推出的网关框架,网关作为流量入口有着非常大的作用,常见的功能有路由转发.权限校 ...
- 【欧拉降幂】Super_log
In Complexity theory, some functions are nearly O(1)O(1), but it is greater then O(1)O(1). For examp ...
- asp net core mvc 跨域ajax解决方案
1.配置服务端 在Startup文件中国配置Cors策略: IEnumerable<Client> clients= Configuration.GetSection("Clie ...
- 【Spring】 AOP Base
1. AOP概述 2. AOP的术语: 3. AOP底层原理 4. Spring 中的AOP 4.1 概述 4.2 分类 4.3 Spring的传统AOP 针对所有方法的增强:(不带有切点的切面) 带 ...
- 【LeetCode】116#填充同一层的兄弟节点
题目描述 给定一个二叉树 struct TreeLinkNode { TreeLinkNode *left; TreeLinkNode *right; TreeLinkNode *next; } 填充 ...
- 获取mysql自主生成的主键
一.sql语句 CREATE TABLE `testgeneratedkeys` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) ...
- Android 开发系列教程之(一)Android基础知识
什么是Android Android一词最早是出现在法国作家维里耶德利尔·亚当1986年发表的<未来夏娃>这部科幻小说中,作者利尔·亚当将外表像人类的机器起名为Android,这就是And ...