用Python爬取猫眼上的top100评分电影
代码如下:
# 注意encoding = 'utf-8'和ensure_ascii = False,不写的话不能输出汉字
import requests
from requests.exceptions import RequestException
import re
import json
#from multiprocessing import Pool # 测试了下 这里需要自己添加头部 否则得不到网页
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
# 得到html代码
def get_one_page(url):
try:
response = requests.get(url, headers = headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None # 解析html代码
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a.*?">(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?(/dd)', re.S)
items = re.findall(pattern, html)
for item in items:
# 将元组形式变为字典
yield {
'【排名】': item[0],
'【图片】': item[1],
'【标题】': item[2],
'【主演】': item[3].strip()[3:],
'【上映时间】': item[4].strip()[5:],
'【评分】': item[5] + item[6]
} # 写入文件,写入的是一个json格式的数据
def write_to_file(content):
with open('top100.csv', 'a', encoding = 'utf-8') as f:
f.write(json.dumps(content, ensure_ascii = False) + '\n')
f.close() # 主函数
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item) if __name__ == '__main__':
for i in range(10):
main(i * 10) # 多进程(测试有bug)
# if __name__ == '__main__':
# pool = Pool()
# pool.map(main, [i * 10 for i in range(10)])
# pool.join()
# pool.close()
运行结果如下:
在top100.csv文件中的数据如下:
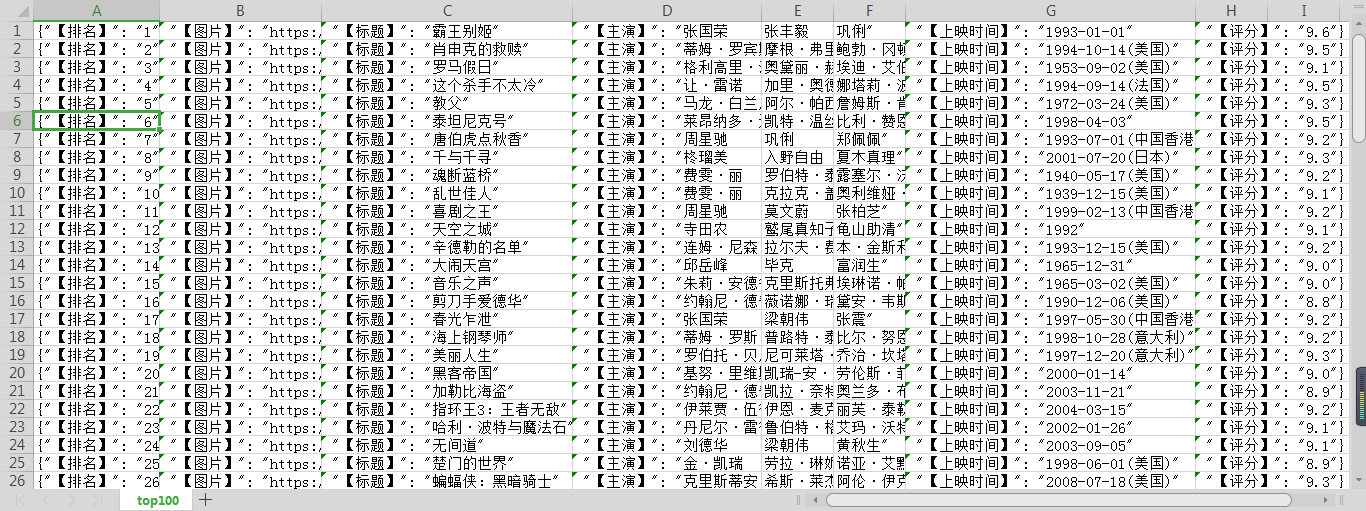
因为没有下载模块所以这里只是显示首页图片的链接,如果想下载首页图片还需再加上下载模块
用Python爬取猫眼上的top100评分电影的更多相关文章
- Python 爬取 猫眼 top100 电影例子
一个Python 爬取猫眼top100的小栗子 import json import requests import re from multiprocessing import Pool #//进程 ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 票房和口碑称霸国庆档,用 Python 爬取猫眼评论区看看电影《我和我的家乡》到底有多牛
今年的国庆档电影市场的表现还是比较强势的,两名主力<我和我的家乡>和<姜子牙>起到了很好的带头作用. <姜子牙>首日破 2 亿,一举刷新由<哪吒之魔童降世&g ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- Python 爬取猫眼电影最受期待榜
主要爬取猫眼电影最受期待榜的电影排名.图片链接.名称.主演.上映时间. 思路:1.定义一个获取网页源代码的函数: 2.定义一个解析网页源代码的函数: 3.定义一个将解析的数据保存为本地文件的函数: ...
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- Python爬取猫眼top100排行榜数据【含多线程】
# -*- coding: utf-8 -*- import requests from multiprocessing import Pool from requests.exceptions im ...
随机推荐
- python爬虫之csv文件
一.二维数据写入csv文件 题目要求: 读入price2016.csv文件,将其中的数据读出,将数字部分计算百分比后输出到price2016out.csv文件中 知识点: 对于列表中存储的二维数据, ...
- WPF 字体设置
原文:WPF 字体设置 WPF 主界面 更换字体 可全局 但是有的时候有的窗体 字体还是没变 可以做全局样式 <Window x:Class="CLeopardTestWpf.Main ...
- Codeforces Round #602 (Div. 2, based on Technocup 2020 Elimination Round 3) F2. Wrong Answer on test 233 (Hard Version) dp 数学
F2. Wrong Answer on test 233 (Hard Version) Your program fails again. This time it gets "Wrong ...
- 2019csp-s
11.17一切尘埃落定 回来之后一直“沉迷”文化课,不想去面对自己,更多的可能是不敢吧 晃晃悠悠一个星期过去了 其实信息学考完就知道成绩了,很垃圾,不想去想,所以沉迷解析几何无法自拔(但好像也做不对几 ...
- selenium爬取NBA并将数据存储到MongoDB
from selenium import webdriver driver = webdriver.Chrome() url = 'https://www.basketball-reference.c ...
- STM32 F4xx Fault 异常错误定位指南
STM32 F407 采用 Cortex-M4 的内核,该内核的 Fault 异常可以捕获非法的内存访问和非法的编程行为.Fault异常能够检测到以下几类非法行为: 总线 Fault: 在取址.数据读 ...
- docker 集群管理gui
k8s: https://www.rancher.cn/ swarm: https://github.com/dockersamples/docker-swarm-visualizer https:/ ...
- KiRaiseException函数逆向
KiRaiseException函数是记录异常的最后一步,在这之后紧接着就调用KiDispatchException分发异常. 我们在逆向前,先看一下书中的介绍: 1. 概念认知: KiRaiseEx ...
- C# consume RestApi
1.RestSharp. Nuget install RestSharp,Newtonsoft.Json. using System; using RestSharp; using Newtonsof ...
- IP地址网段表示法
172.12.34.0/25 子网掩码:用于表示IP地址中的多少位用来做主机号.因为"其中值为1的比特留给网络号和子网号,为0的比特留给主机号"(TCP/IP V1). 172.1 ...