Paper | Fast image processing with fully-convolutional networks
发表在2017年ICCV。
核心任务:加速图像处理算子(accelerate image processing operators)。
核心方法:将算子处理前、后的图像,训练一个全卷积CNN网络,从而代替传统算子。
核心贡献:作者选择了一种CNN结构,在10种算子上表现优异。
故事
历史上已经有很多图像处理算子,解决各种各样的图像处理问题。比如双边带滤波器等。但它们的普遍问题是慢,难以实时。
有些人尝试:将图像降采样,再进行处理,最后再升采样。这种办法一是会导致性能下降,因为高频细节在降采样时丢掉了;二是即便这样也很难实时。
本文的方法:将算子处理前、后的图像,用于训练一个全卷积CNN网络。然后我们就用CNN处理图像啦!再也不用降采样啦!
此外,在选择网络结构时,作者综合考虑了它们(1)近似图像处理算子的精度,(2)运行时间,(3)结构复杂性(如参数规模,使得能够存储在移动设备上),并最终选择了一个效果最好的网络结构。作者同时考虑了10种图像处理算子。
最后,作者还提出了一个很有意思的实验:由于CNN将这些算子参数化了,因此我们可以在测试阶段调整这些参数,从而实现交互式图像处理。
方法
直接看原文中比较重要的一段:
We have experimented with a large number of network architectures derived from prior work in high-level vision, specifically on semantic segmentation. We found that when some of these high-level networks are applied to low-level image processing problems, they generally outperform dedicated architectures previously designed for these image processing problems. The key advantage of architectures designed for high-level vision is their large receptive field. Many image processing operators are based on global optimization over the entire image, analysis of global image properties, or nonlocal information aggregation. To model such operators faithfully, the network must collect data from spatially distributed locations, aggregating information at multiple scales that are ultimately large enough to provide a global view of the image.
重点:作者尝试将一些 原本用于high-level任务(如图像分割)的网络 用于图像处理任务,发现性能很好。原因可能是:这些网络的感受野通常比较大,因此在全局特征提取上做得比较好。而传统图像算子也很强调这一点,比如NL方法。
作者最终选择了[78]中提出的网络结构【该文三作也是[78]的作者。[78]谷歌引用2k+】,最初用于语义分割。
首先,输入和输出尺寸相同,都是\(m \times n \times w\)。中间特征的获取流程都是:\(3 \times 3\)空洞卷积(dilated convolution) => 自适应正则化 => LReLU非线性激活。
其中:
空洞卷积的好处是:特征图的尺寸不会随着深度下降而变小,因此我们可以增大深度,从而增大感受野。最后一层不用空洞卷积,而是采用\(1 \times 1\)卷积,并且不使用非线性激活。
自适应正则化先对特征BN,然后再作线性变换。注意有两个分支:一个是恒等分支,还有一个是BN分支。

网络中不含任何短连接,因此最大内存消耗只有前后两个卷积结构。
训练采用的是MSE损失。作者声称:尽管MSE被认为在感知质量方面不够理想,但其PSNR和SSIM精度表现好。作者尝试了其他损失,如对抗损失,结果发现近似精度不高。
实验
首先看拟合精度:

然后看速度和参数规模:
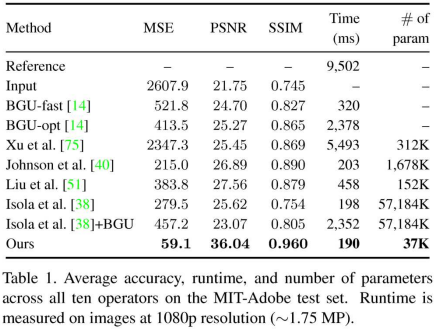
其他的不看了。我们看看如何交互。在本文中,作者是增加了一个可调整的输入通道,来实现交互。
最后最后,作者尝试用一个网络实现10个功能。做法:
增加了10个输入通道。每个通道都是一个二值通道,来指示任务选择。
训练时随机切换任务和训练对象。
效果一般。如论文中表2。
这篇文章怎么能引用近100次的???把一篇2k+引用文章里的网络拿来,也能发一篇ICCV,实在没明白。
Paper | Fast image processing with fully-convolutional networks的更多相关文章
- Fully Convolutional Networks for Semantic Segmentation 译文
Fully Convolutional Networks for Semantic Segmentation 译文 Abstract Convolutional networks are powe ...
- 【Detection】R-FCN: Object Detection via Region-based Fully Convolutional Networks论文分析
目录 0. Paper link 1. Overview 2. position-sensitive score maps 2.1 Background 2.2 position-sensitive ...
- 中文版 R-FCN: Object Detection via Region-based Fully Convolutional Networks
R-FCN: Object Detection via Region-based Fully Convolutional Networks 摘要 我们提出了基于区域的全卷积网络,以实现准确和高效的目标 ...
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
Xiang Bai--[CVPR2016]Multi-Oriented Text Detection with Fully Convolutional Networks 目录 作者和相关链接 方法概括 ...
- 【Semantic Segmentation】 Instance-sensitive Fully Convolutional Networks论文解析(转)
这篇文章比较简单,但还是不想写overview,转自: https://blog.csdn.net/zimenglan_sysu/article/details/52451098 另外,读这篇pape ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- 『计算机视觉』R-FCN:Object Detection via Region-based Fully Convolutional Networks
一.网络介绍 参考文章:R-FCN详解 论文地址:Object Detection via Region-based Fully Convolutional Networks R-FCN是Faster ...
- 全卷积网络Fully Convolutional Networks (FCN)实战
全卷积网络Fully Convolutional Networks (FCN)实战 使用图像中的每个像素进行类别预测的语义分割.全卷积网络(FCN)使用卷积神经网络将图像像素转换为像素类别.与之前介绍 ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
随机推荐
- npm 命令 --save 和 --save-dev 的区别
回顾 npm install 命令 我们在使用 npm install 安装模块的模块的时候 ,一般会使用下面这几种命令形式: 1 2 3 4 5 6 7 npm install moduleName ...
- centos安装mongodb 4.x及配置用户名密码(官方推荐的方式)
安装mongodb 先在本地用记事本做一个这样的文件(命名为:mongodb-org-4.0.repo): [mongodb-org-4.0] name=MongoDB Repository base ...
- SqlServer PIVOT行转列
PIVOT通过将表达式某一列中的唯一值转换为输出中的多个列来旋转表值表达式,并在必要时对最终输出中所需的任何其余列值执行聚合. 测试数据 INSERT INTO [TestRows2Columns] ...
- 《细说PHP》第四版 样章 第23章 自定义PHP接口规范 5
23.3 接口的安全控制规范 23.2节的示例实现了一个简单接口,但是这个接口此时是在“裸奔”的.因为这个接口所有人都可以请求,不仅我们的客户端可以正常访问数据,如果有人使用如fiddler.wir ...
- 记录使用echarts的graph类型绘制流程图全过程(二)- 多层关系和圆形图片的设置
本文主要记录在使用echarts的graph类型绘制流程图时候遇到的2个问题:对于圆形图片的剪切和多层关系的设置 图片的设置 如果用echarts默认的symbol参数来显示图片,会显示图片的原始状态 ...
- 用户和登录的ID、Name和SID
SQL Server的安全主体主要分为Login.User和Role,不仅有ID属性,还有Name属性和SID属性,SID是指Security ID.在查看用户和登录的时候,受到模拟上下文的影响.当执 ...
- 手写SpringMVC实现过程
1. Spring Boot,Spring MVC的底层实现都是Servlet的调用. 2. Servlet的生命周期里面首先是类的初始化,然后是类的方法的调用,再次是类的销毁. 3. 创建一个spr ...
- C# Task ContinueWith
static void Main(string[] args) { Task firstTask = Task.Run(() => { PrintPlus(); }); Task secondT ...
- Web前端基础(6):CSS(三)
1. 定位 定位有三种:相对定位.绝对定位.固定定位 1.1 相对定位 现象和使用: 1.如果对当前元素仅仅设置了相对定位,那么与标准流的盒子什么区别. 2.设置相对定位之后,我们才可以使用四个方向的 ...
- python基础(34):线程(二)
1. python线程 1.1 全局解释器锁GIL Python代码的执行由Python虚拟机(也叫解释器主循环)来控制.Python在设计之初就考虑到要在主循环中,同时只有一个线程在执行.虽然 Py ...