Kafka面试,看这篇文章就够了
原文链接:https://mp.weixin.qq.com/s/zxPz_aFEMrshApZQ727h4g**
引言
MQ(消息队列)是跨进程通信的方式之一,可理解为异步rpc,上游系统对调用结果的态度往往是重要不紧急。使用消息队列有以下好处:业务解耦、流量削峰、灵活扩展。接下来介绍消息中间件Kafka。
Kafka是什么?
Kafka是一个分布式的消息引擎。具有以下特征
能够发布和订阅消息流(类似于消息队列)
以容错的、持久的方式存储消息流
多分区概念,提高了并行能力
Kafka架构总览
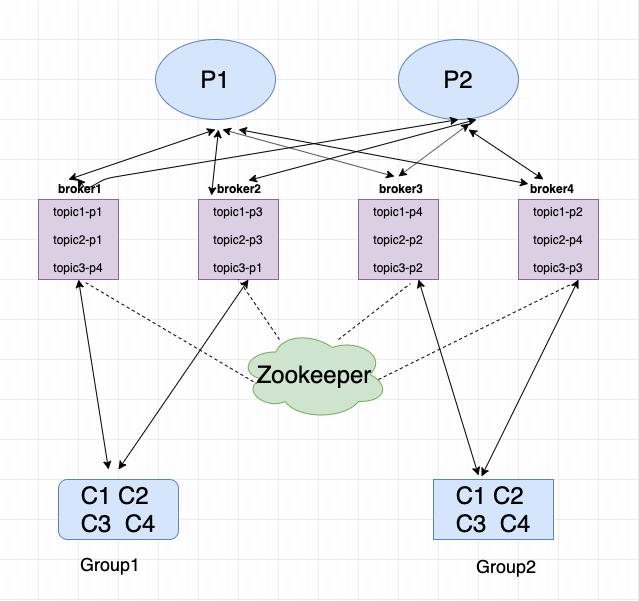
Topic
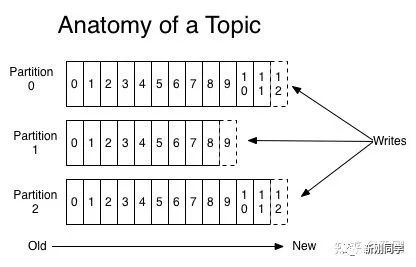
消息的主题、队列,每一个消息都有它的topic,Kafka通过topic对消息进行归类。Kafka中可以将Topic从物理上划分成一个或多个分区(Partition),每个分区在物理上对应一个文件夹,以”topicName_partitionIndex”的命名方式命名,该dir包含了这个分区的所有消息(.log)和索引文件(.index),这使得Kafka的吞吐率可以水平扩展。
Partition
每个分区都是一个 顺序的、不可变的消息队列, 并且可以持续的添加;分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
producer在发布消息的时候,可以为每条消息指定Key,这样消息被发送到broker时,会根据分区算法把消息存储到对应的分区中(一个分区存储多个消息),如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡。
Broker
Kafka server,用来存储消息,Kafka集群中的每一个服务器都是一个Broker,消费者将从broker拉取订阅的消息
Producer
向Kafka发送消息,生产者会根据topic分发消息。生产者也负责把消息关联到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。算法可由开发者定义。
Cousumer
Consermer实例可以是独立的进程,负责订阅和消费消息。消费者用consumerGroup来标识自己。同一个消费组可以并发地消费多个分区的消息,同一个partition也可以由多个consumerGroup并发消费,但是在consumerGroup中一个partition只能由一个consumer消费
CousumerGroup
Consumer Group:同一个Consumer Group中的Consumers,Kafka将相应Topic中的每个消息只发送给其中一个Consumer
Kafka producer 设计原理
发送消息的流程
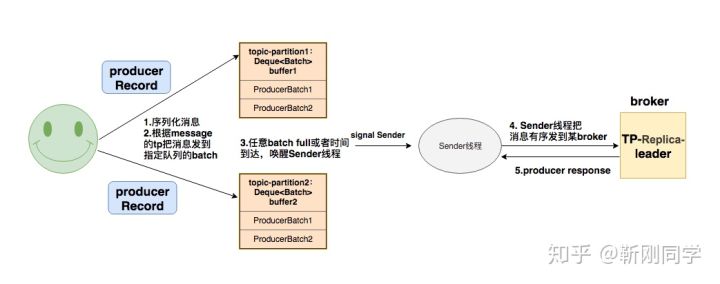
1.序列化消息&&.计算partition
根据key和value的配置对消息进行序列化,然后计算partition:
ProducerRecord对象中如果指定了partition,就使用这个partition。否则根据key和topic的partition数目取余,如果key也没有的话就随机生成一个counter,使用这个counter来和partition数目取余。这个counter每次使用的时候递增。
2发送到batch&&唤醒Sender 线程
根据topic-partition获取对应的batchs(Dueue),然后将消息append到batch中.如果有batch满了则唤醒Sender 线程。队列的操作是加锁执行,所以batch内消息时有序的。后续的Sender操作当前方法异步操作。

3.Sender把消息有序发到 broker(tp replia leader)
3.1 确定tp relica leader 所在的broker
Kafka中 每台broker都保存了kafka集群的metadata信息,metadata信息里包括了每个topic的所有partition的信息: leader, leader_epoch, controller_epoch, isr, replicas等;Kafka客户端从任一broker都可以获取到需要的metadata信息;sender线程通过metadata信息可以知道tp leader的brokerId
producer也保存了metada信息,同时根据metadata更新策略(定期更新metadata.max.age.ms、失效检测,强制更新:检查到metadata失效以后,调用metadata.requestUpdate()强制更新
public class PartitionInfo {
private final String topic; private final int partition;
private final Node leader; private final Node[] replicas;
private final Node[] inSyncReplicas; private final Node[] offlineReplicas;
}
3.2 幂等性发送
为实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。对于每个PID,该Producer发送消息的每个<Topic, Partition>都对应一个单调递增的Sequence Number。同样,Broker端也会为每个<PID, Topic, Partition>维护一个序号,并且每Commit一条消息时将其对应序号递增。对于接收的每条消息,如果其序号比Broker维护的序号)大一,则Broker会接受它,否则将其丢弃:
如果消息序号比Broker维护的序号差值比一大,说明中间有数据尚未写入,即乱序,此时Broker拒绝该消息,Producer抛出InvalidSequenceNumber
如果消息序号小于等于Broker维护的序号,说明该消息已被保存,即为重复消息,Broker直接丢弃该消息,Producer抛出DuplicateSequenceNumber
Sender发送失败后会重试,这样可以保证每个消息都被发送到broker
4. Sender处理broker发来的produce response
一旦broker处理完Sender的produce请求,就会发送produce response给Sender,此时producer将执行我们为send()设置的回调函数。至此producer的send执行完毕。
吞吐性&&延时:
buffer.memory:buffer设置大了有助于提升吞吐性,但是batch太大会增大延迟,可搭配linger_ms参数使用
linger_ms:如果batch太大,或者producer qps不高,batch添加的会很慢,我们可以强制在linger_ms时间后发送batch数据
ack:producer收到多少broker的答复才算真的发送成功
0表示producer无需等待leader的确认(吞吐最高、数据可靠性最差)
1代表需要leader确认写入它的本地log并立即确认
-1/all 代表所有的ISR都完成后确认(吞吐最低、数据可靠性最高)
Sender线程和长连接
每初始化一个producer实例,都会初始化一个Sender实例,新增到broker的长连接。
代码角度:每初始化一次KafkaProducer,都赋一个空的client
public KafkaProducer(final Map<String, Object> configs) {
this(configs, null, null, null, null, null, Time.SYSTEM);
}
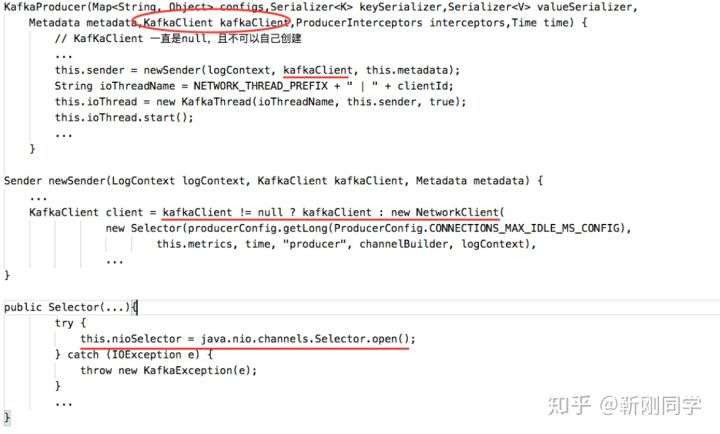
终端查看TCP连接数:
lsof -p portNum -np | grep TCP
Consumer设计原理
poll消息
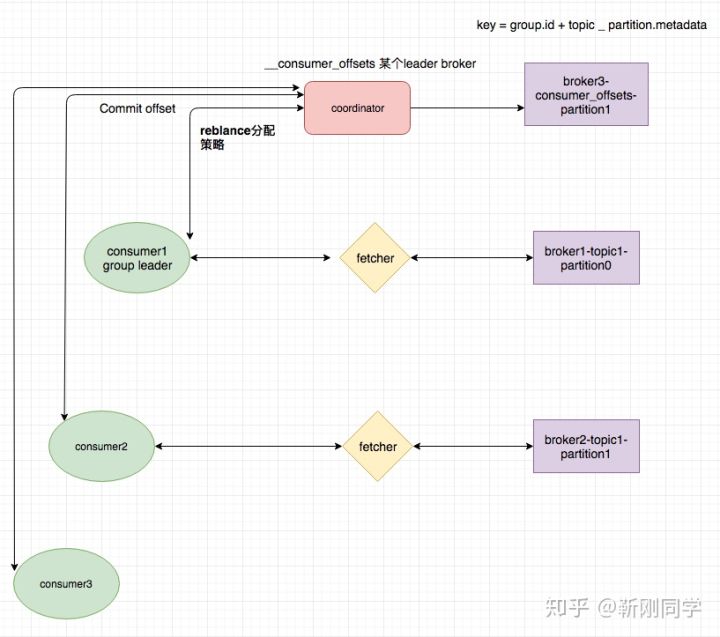
- 消费者通过fetch线程拉消息(单线程)
- 消费者通过心跳线程来与broker发送心跳。超时会认为挂掉
- 每个consumer
group在broker上都有一个coordnator来管理,消费者加入和退出,以及消费消息的位移都由coordnator处理。
位移管理
consumer的消息位移代表了当前group对topic-partition的消费进度,consumer宕机重启后可以继续从该offset开始消费。
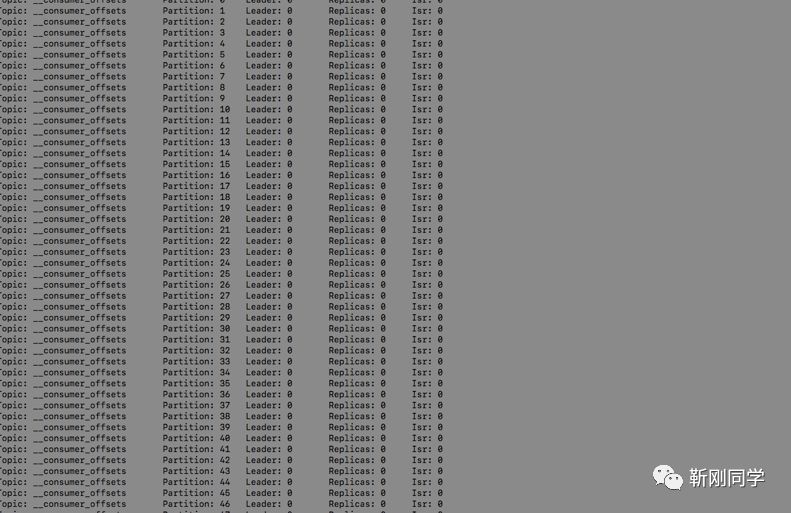
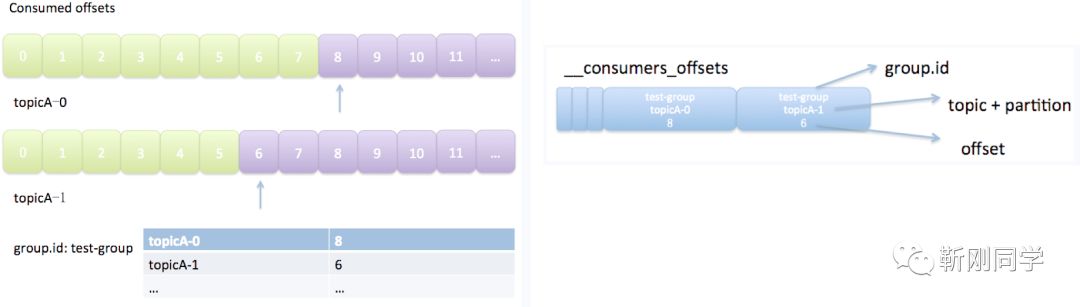
在kafka0.8之前,位移信息存放在zookeeper上,由于zookeeper不适合高并发的读写,新版本Kafka把位移信息当成消息,发往__consumers_offsets 这个topic所在的broker,__consumers_offsets默认有50个分区。
消息的key 是groupId+topic_partition,value 是offset.
Kafka Group 状态
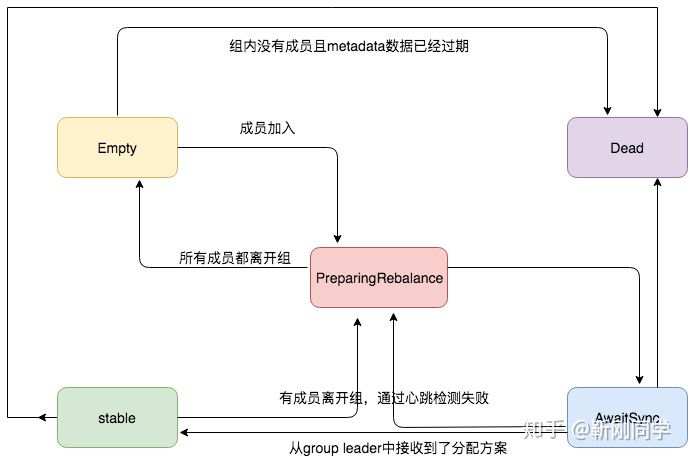
- Empty:初始状态,Group 没有任何成员,如果所有的 offsets 都过期的话就会变成 Dead
- PreparingRebalance:Group 正在准备进行 Rebalance
- AwaitingSync:Group 正在等待来 group leader 的 分配方案
- Stable:稳定的状态(Group is stable);
- Dead:Group 内已经没有成员,并且它的 Metadata 已经被移除
重平衡reblance
当一些原因导致consumer对partition消费不再均匀时,kafka会自动执行reblance,使得consumer对partition的消费再次平衡。
什么时候发生rebalance?:
- 组订阅topic数变更
- topic partition数变更
- consumer成员变更
- consumer 加入群组或者离开群组的时候
- consumer被检测为崩溃的时候
reblance过程
举例1 consumer被检测为崩溃引起的reblance
比如心跳线程在timeout时间内没和broker发送心跳,此时coordnator认为该group应该进行reblance。接下来其他consumer发来fetch请求后,coordnator将回复他们进行reblance通知。当consumer成员收到请求后,只有leader会根据分配策略进行分配,然后把各自的分配结果返回给coordnator。这个时候只有consumer leader返回的是实质数据,其他返回的都为空。收到分配方法后,consumer将会把分配策略同步给各consumer
举例2 consumer加入引起的reblance
使用join协议,表示有consumer 要加入到group中
使用sync 协议,根据分配规则进行分配
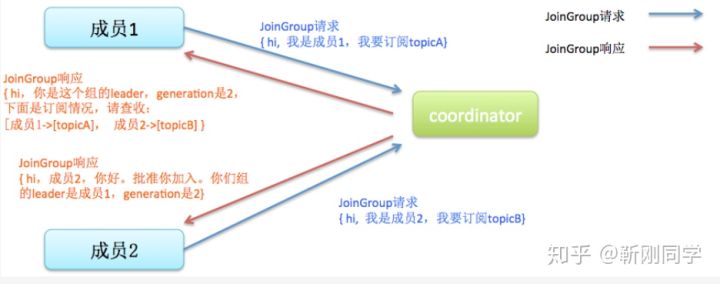

(上图图片摘自网络)
引申:以上reblance机制存在的问题
在大型系统中,一个topic可能对应数百个consumer实例。这些consumer陆续加入到一个空消费组将导致多次的rebalance;此外consumer 实例启动的时间不可控,很有可能超出coordinator确定的rebalance timeout(即max.poll.interval.ms),将会再次触发rebalance,而每次rebalance的代价又相当地大,因为很多状态都需要在rebalance前被持久化,而在rebalance后被重新初始化。
新版本改进
通过延迟进入PreparingRebalance状态减少reblance次数
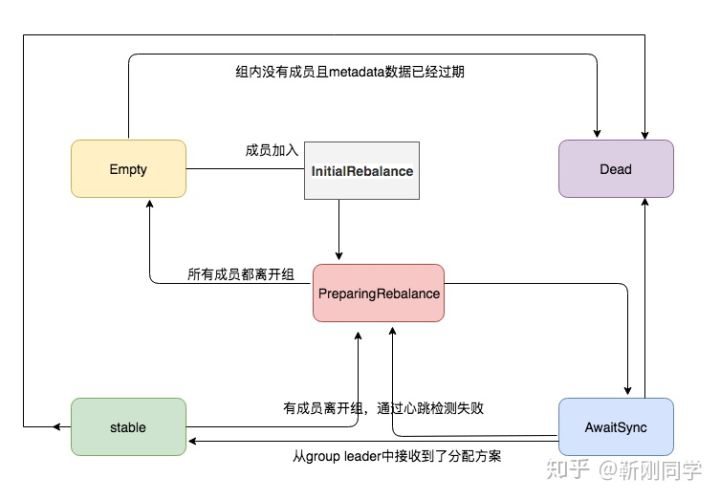
新版本新增了group.initial.rebalance.delay.ms参数。空消费组接受到成员加入请求时,不立即转化到PreparingRebalance状态来开启reblance。当时间超过group.initial.rebalance.delay.ms后,再把group状态改为PreparingRebalance(开启reblance)。实现机制是在coordinator底层新增一个group状态:InitialReblance。假设此时有多个consumer陆续启动,那么group状态先转化为InitialReblance,待group.initial.rebalance.delay.ms时间后,再转换为PreparingRebalance(开启reblance)
Broker设计原理
Broker 是Kafka 集群中的节点。负责处理生产者发送过来的消息,消费者消费的请求。以及集群节点的管理等。由于涉及内容较多,先简单介绍,后续专门抽出一篇文章分享
broker zk注册
broker消息存储
Kafka的消息以二进制的方式紧凑地存储,节省了很大空间
此外消息存在ByteBuffer而不是堆,这样broker进程挂掉时,数据不会丢失,同时避免了gc问题
通过零拷贝和顺序寻址,让消息存储和读取速度都非常快
处理fetch请求的时候通过zero-copy 加快速度
broker状态数据
broker设计中,每台机器都保存了相同的状态数据。主要包括以下:
controller所在的broker ID,即保存了当前集群中controller是哪台broker
集群中所有broker的信息:比如每台broker的ID、机架信息以及配置的若干组连接信息
集群中所有节点的信息:严格来说,它和上一个有些重复,不过此项是按照broker ID和***类型进行分组的。对于超大集群来说,使用这一项缓存可以快速地定位和查找给定节点信息,而无需遍历上一项中的内容,算是一个优化吧
集群中所有分区的信息:所谓分区信息指的是分区的leader、ISR和AR信息以及当前处于offline状态的副本集合。这部分数据按照topic-partitionID进行分组,可以快速地查找到每个分区的当前状态。(注:AR表示assigned replicas,即创建topic时为该分区分配的副本集合)
broker负载均衡
分区数量负载:各台broker的partition数量应该均匀
partition Replica分配算法如下:
将所有Broker(假设共n个Broker)和待分配的Partition排序
将第i个Partition分配到第(i mod n)个Broker上
将第i个Partition的第j个Replica分配到第((i + j) mod n)个Broker上
容量大小负载:每台broker的硬盘占用大小应该均匀
在kafka1.1之前,Kafka能够保证各台broker上partition数量均匀,但由于每个partition内的消息数不同,可能存在不同硬盘之间内存占用差异大的情况。在Kafka1.1中增加了副本跨路径迁移功能kafka-reassign-partitions.sh,我们可以结合它和监控系统,实现自动化的负载均衡
Kafka高可用
在介绍kafka高可用之前先介绍几个概念
同步复制:要求所有能工作的Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率
异步复制:Follower异步的从Leader pull数据,data只要被Leader写入log认为已经commit,这种情况下如果Follower落后于Leader的比较多,如果Leader突然宕机,会丢失数据
Isr
Kafka结合同步复制和异步复制,使用ISR(与Partition Leader保持同步的Replica列表)的方式在确保数据不丢失和吞吐率之间做了平衡。Producer只需把消息发送到Partition Leader,Leader将消息写入本地Log。Follower则从Leader pull数据。Follower在收到该消息向Leader发送ACK。一旦Leader收到了ISR中所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。这样如果leader挂了,只要Isr中有一个replica存活,就不会丢数据。
Isr动态更新
Leader会跟踪ISR,如果ISR中一个Follower宕机,或者落后太多,Leader将把它从ISR中移除。这里所描述的“落后太多”指Follower复制的消息落后于Leader后的条数超过预定值(replica.lag.max.messages)或者Follower超过一定时间(replica.lag.time.max.ms)未向Leader发送fetch请求。
broker Nodes In Zookeeper
/brokers/topics/[topic]/partitions/[partition]/state 保存了topic-partition的leader和Isr等信息
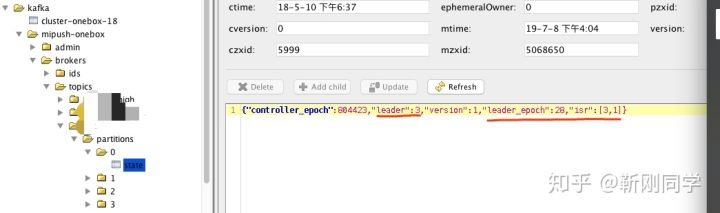
Controller负责broker故障检查&&故障转移(fail/recover)
- Controller在Zookeeper上注册Watch,一旦有Broker宕机,其在Zookeeper对应的znode会自动被删除,Zookeeper会触发
Controller注册的watch,Controller读取最新的Broker信息 - Controller确定set_p,该集合包含了宕机的所有Broker上的所有Partition
- 对set_p中的每一个Partition,选举出新的leader、Isr,并更新结果。
3.1 从/brokers/topics/[topic]/partitions/[partition]/state读取该Partition当前的ISR
3.2 决定该Partition的新Leader和Isr。如果当前ISR中有至少一个Replica还幸存,则选择其中一个作为新Leader,新的ISR则包含当前ISR中所有幸存的Replica。否则选择该Partition中任意一个幸存的Replica作为新的Leader以及ISR(该场景下可能会有潜在的数据丢失)
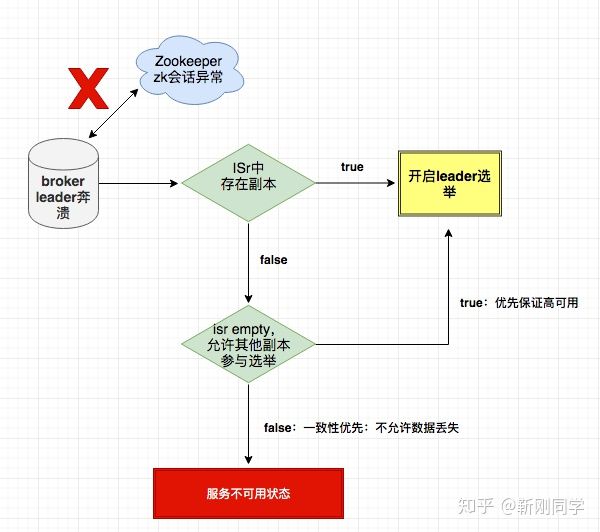
3.3 更新Leader、ISR、leader_epoch、controller_epoch:写入/brokers/topics/[topic]/partitions/[partition]/state
- 直接通过RPC向set_p相关的Broker发送LeaderAndISRRequest命令。Controller可以在一个RPC操作中发送多个命令从而提高效率。
Controller挂掉
每个 broker 都会在 zookeeper 的临时节点 "/controller" 注册 watcher,当 controller 宕机时 "/controller" 会消失,触发broker的watch,每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。
使用Kafka如何保证幂等性
不丢消息
首先kafka保证了对已提交消息的at least保证
Sender有重试机制
producer业务方在使用producer发送消息时,注册回调函数。在onError方法中重发消息
consumer 拉取到消息后,处理完毕再commit,保证commit的消息一定被处理完毕
不重复
consumer拉取到消息先保存,commit成功后删除缓存数据
Kafka高性能
partition提升了并发
zero-copy
顺序写入
消息聚集batch
页缓存
业务方对 Kafka producer的优化
增大producer数量
ack配置
batch
原文链接:https://mp.weixin.qq.com/s/zxPz_aFEMrshApZQ727h4g **
如果喜欢我的文章,欢迎扫码关注

Kafka面试,看这篇文章就够了的更多相关文章
- Vue开发入门看这篇文章就够了
摘要: 很多值得了解的细节. 原文:Vue开发看这篇文章就够了 作者:Random Fundebug经授权转载,版权归原作者所有. 介绍 Vue 中文网 Vue github Vue.js 是一套构建 ...
- 数据可视化之PowerQuery篇(四)二维表转一维表,看这篇文章就够了
https://zhuanlan.zhihu.com/p/69187094 数据分析的源数据应该是规范的,而规范的其中一个标准就是数据源应该是一维表,它会让之后的数据分析工作变得简单高效. 在之前的文 ...
- 还不会Traefik?看这篇文章就够了!
文章转载自:https://mp.weixin.qq.com/s/ImZG0XANFOYsk9InOjQPVA 提到Traefik,有些人可能并不熟悉,但是提到Nginx,应该都耳熟能详. 暂且我们把 ...
- 想让安卓app不再卡顿?看这篇文章就够了
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由likunhuang发表于云+社区专栏 实现背景 应用的使用流畅度,是衡量用户体验的重要标准之一.Android 由于机型配置和系统的 ...
- 面试官问你MySQL的优化,看这篇文章就够了
作者:zhangqh segmentfault.com/a/1190000012155267 一.EXPLAIN 做MySQL优化,我们要善用 EXPLAIN 查看SQL执行计划. 下面来个简单的示例 ...
- 想要彻底搞懂大厂是如何实现Redis高可用的?看这篇文章就够了!(1.2W字,建议收藏)
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间. 假设系统一直能够提供服务,我们说系统的可用性是100%.如果 ...
- 微信小程序获取手机号码看这篇文章就够了
前言 微信小程序获取手机号码,从官方文档到其他博主的文档 零零散散的 (我就是这样看过来 没有一篇满意的 也许是我搜索姿势不对) 依旧是前人栽树 后人乘凉 系列.保证看完 就可以实现获取手机号码功能 ...
- 关于CompletableFuture的一切,看这篇文章就够了
文章目录 CompletableFuture作为Future使用 异步执行code 组合Futures thenApply() 和 thenCompose()的区别 并行执行任务 异常处理 java中 ...
- 讲真,MySQL索引优化看这篇文章就够了
本文主要讨论MySQL索引的部分知识.将会从MySQL索引基础.索引优化实战和数据库索引背后的数据结构三部分相关内容,下面一一展开. 一.MySQL——索引基础 首先,我们将从索引基础开始介绍一下什么 ...
随机推荐
- scrapy实战2分布式爬取lagou招聘(加入了免费的User-Agent随机动态获取库 fake-useragent 使用方法查看:https://github.com/hellysmile/fake-useragent)
items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentati ...
- 使用java的MultipartFile实现layui官网文件上传实现全部示例,java文件上传
layui(谐音:类UI) 是一款采用自身模块规范编写的前端 UI 框架,遵循原生 HTML/CSS/JS 的书写与组织形式,门槛极低,拿来即用. layui文件上传示例地址:https://www. ...
- ML.NET技术研究系列-2聚类算法KMeans
上一篇博文我们介绍了ML.NET 的入门: ML.NET技术研究系列1-入门篇 本文我们继续,研究分享一下聚类算法k-means. 一.k-means算法简介 k-means算法是一种聚类算法,所谓聚 ...
- 安卓学习资料推荐《深入理解Android:卷2》下载
下载地址:百度云下载地址 编辑推荐 <深入理解Android:卷2>编辑推荐:经典畅销书<深入理解Android:卷I>姊妹篇,51CTO移动开发频道和开源中国社区一致鼎力推荐 ...
- asp.net core系列 68 Filter管道过滤器
一.概述 本篇详细了解一下asp.net core filters,filter叫"筛选器"也叫"过滤器",是请求处理管道中的特定阶段之前或之后运行代码.fil ...
- 提高JavaScript 技能的12个概念
JavaScript 是一种复杂的语言.如果是你是高级或者初级 JavaScript 开发人员,了解它的基本概念非常重要.本文介绍 JavaScript 至关重要的12个概念,但绝对不是说 JavaS ...
- mybatis基础配置
我这个写的比较简略,是自己短时间记录的可能只适合自己看,新手或者不懂的建议看看下面大神这篇: https://www.cnblogs.com/homejim/p/9613205.html 1.MyBa ...
- CAxWindow
AtlAxWinInit(); CAxWindow m_wndFlashPlayer; CComPtr<IShockwaveFlash> m_FlashPtr; CComPtr<IU ...
- win10修改桌面图标之间的距离
操作方法01首先用Win+R组合键打开运行界面,在界面的输入框中输入regedit命令,打开注册表. 02在打开的注册表界面中我们找到HKEY_Current_User下的Control Panel文 ...
- [USACO09FEB]股票市场Stock Market
题意简述: 给定⼀个DDD天的SSS只股票价格矩阵,以及初始资⾦ MMM:每次买股票只能买某个股票价格的整数倍,可以不花钱,约定获利不超过500000500000500000.最⼤化你的 总获利. 题 ...