Java 8 Stream实践
【**前面的话**】Java中的Stream于1.8版本析出,平时项目中也有用到,今天就系统的来实践一下。下面借用重庆力帆队伍中我个人比较喜欢的球员来操作一波,队员的年龄为了便于展示某些api做了调整,请不要太认真哦。
***
# 壹. Stream理解
在java中我们称Stream为『**流**』,我们经常会用流去对集合进行一些流水线的操作。stream就像工厂一样,只需要把集合、命令还有一些参数灌输到流水线中去,就可以加工成得出想要的结果。这样的流水线能大大简洁代码,减少操作。给我个人的感觉类似JavaScript中的链式函数。
# 贰. Stream流程
```java
原集合 —> 流 —> 各种操作(过滤、分组、统计) —> 终端操作
```
Stream流的操作流程一般都是这样的,先将集合转为流,然后经过各种操作,比如过滤、筛选、分组、计算。最后的终端操作,就是转化成我们想要的数据,这个数据的形式一般还是集合,有时也会按照需求输出count计数。下文会一一举例。
# 叁. API实践
首先,定义一个用户对象,包含姓名、年龄、id三个成员变量:
```java
package com.eelve.training.entity;
import lombok.*;
import javax.persistence.*;
/**
* @ClassName User
* @Description TDO
* @Author zhao.zhilue
* @Date 2019/6/28 15:21
* @Version 1.0
**/
@Data
@Entity
@Table(name = "user")
@ToString
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode(exclude={"id","name"})
public class User implements Comparable{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Integer id;
/**
* Link name.
*/
@Column(name = "name", columnDefinition = "varchar(255) not null")
private String name;
@Column(name = "age")
private Integer age;
public User(String name, Integer age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(User o) {
return age.compareTo(o.getAge());
}
}
```
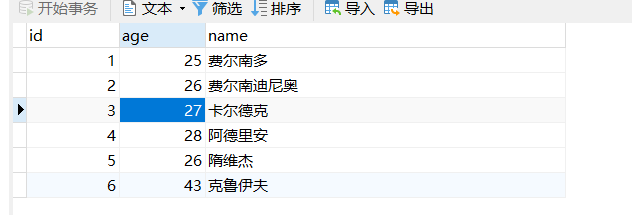
然后在数据库中插入测试数据,见下图:
## 3.1过滤
### 1)filter 过滤(T-> boolean)
假如我们要实现过滤出40岁以下的队员,我们可以这样来实现:
```java
@Test
public void testUserStreamFilter(){
List userList = userMapper.getALL();
List resultList = userList.stream().filter(user -> user.getAge() 箭头后面跟着的是一个**boolean**值,可以写任何的过滤条件,就相当于sql中where后面的东西,换句话说,能用sql实现的功能这里都可以实现
执行结果为:
```java
User(id=1, name=费尔南多, age=25)
User(id=2, name=费尔南迪尼奥, age=26)
User(id=3, name=卡尔德克, age=27)
User(id=4, name=阿德里安, age=28)
User(id=5, name=隋维杰, age=26)
```
### 2)distinct 去重
其用法和sql中的使用类似,假如我们要实现过去除用重复年龄的队员,我们可以这样来实现:
```java
@Test
public void testUserDistinct(){
List userList = userMapper.getALL();
List resultList = userList.stream().distinct().collect(Collectors.toList());
for (User user : resultList){
System.out.println(user.toString());
}
}
```
执行结果为:
```java
User(id=1, name=费尔南多, age=25)
User(id=2, name=费尔南迪尼奥, age=26)
User(id=3, name=卡尔德克, age=27)
User(id=4, name=阿德里安, age=28)
User(id=6, name=克鲁伊夫, age=43)
```
### 3)sorted排序
如果流中的元素的类实现了 Comparable 接口,即有自己的排序规则,那么可以直接调用 sorted() 方法对元素进行排序,如:
```java
@Override
public int compareTo(User o) {
return age.compareTo(o.getAge());
}
```
```java
@Test
public void testUserStreamSorted(){
List userList = userMapper.getALL();
List resultList = userList.stream().sorted().collect(Collectors.toList());
for (User user : resultList){
System.out.println(user.toString());
}
}
```
反之, 需要调用 sorted((T, T) -> int) 实现 Comparator 接口。
```java
@Test
public void testUserStreamSortedWithComparator(){
List userList = userMapper.getALL();
List resultList = userList.stream().sorted(Comparator.comparingInt(User::getAge)).collect(Collectors.toList());
for (User user : resultList){
System.out.println(user.toString());
}
}
```
执行结果为:
```java
User(id=1, name=费尔南多, age=25)
User(id=2, name=费尔南迪尼奥, age=26)
User(id=5, name=隋维杰, age=26)
User(id=3, name=卡尔德克, age=27)
User(id=4, name=阿德里安, age=28)
User(id=6, name=克鲁伊夫, age=43)
```
### 4)limit() 返回前n个元素
如果想知道队伍中年龄最小的就可以使用下面来实现:
```java
@Test
public void testUserStreamLimit(){
List userList = userMapper.getALL();
List resultList = userList.stream().limit(2).collect(Collectors.toList());
for (User user : resultList){
System.out.println(user.toString());
}
}
```
执行结果为:
```java
User(id=1, name=费尔南多, age=25)
User(id=2, name=费尔南迪尼奥, age=26)
```
### 5)skip
它的用法和limit正好相反,是去除前面几个元素。
假如我们要去除前面两个元素就可以使用下面的方法来实现:
```java
@Test
public void testUserStreamSkip(){
List userList = userMapper.getALL();
List resultList = userList.stream().skip(2).collect(Collectors.toList());
for (User user : resultList){
System.out.println(user.toString());
}
}
```
执行结果为:
```java
User(id=3, name=卡尔德克, age=27)
User(id=4, name=阿德里安, age=28)
User(id=5, name=隋维杰, age=26)
User(id=6, name=克鲁伊夫, age=43)
```
### 6)组合使用
以上的过滤函数物品们可以组合来使用来实现我们具体的需求,示例代码如下:
```java
@Test
public void testUserStreamSortLimit(){
List userList = userMapper.getALL();
List resultList = userList.stream().sorted().limit(5).collect(Collectors.toList());
for (User user : resultList){
System.out.println(user.toString());
}
}
```
这样我们就可以得到先排序后限制的结果:
```java
User(id=1, name=费尔南多, age=25)
User(id=2, name=费尔南迪尼奥, age=26)
User(id=5, name=隋维杰, age=26)
User(id=3, name=卡尔德克, age=27)
User(id=4, name=阿德里安, age=28)
```
## 3.2 映射
### 1)map(T->R)
map是将T类型的数据转为R类型的数据,比如我们想要设置一个新的list,存储用户所有的城市信息。
```java
@Test
public void testUserStreamMap(){
List userList = userMapper.getALL();
List resultList = userList.stream().map(User::getAge).distinct().collect(Collectors.toList());
System.out.println(resultList.toString());
}
```
这样我们可以得到所有年龄的样本,执行结果为:
```java
[25, 26, 27, 28, 43]
```
### 2)flatMap(T -> Stream)
将流中的每一个元素 T 映射为一个流,再把每一个流连接成为一个流。
```java
@Test
public void testStreamMap(){
List habitsList = new ArrayList();
habitsList.add("唱歌,听歌");
habitsList.add("羽毛球,足球,登山");
habitsList = habitsList.stream().map(s -> s.split(",")).flatMap(Arrays::stream).collect(Collectors.toList());
System.out.println(habitsList);
}
```
执行结果为:
```java
[唱歌, 听歌, 羽毛球, 足球, 登山]
```
这里原集合中的数据由逗号分割,使用split进行拆分后,得到的是Stream,字符串数组组成的流,要使用flatMap的**Arrays::stream**,将Stream转为Stream,然后把流相连接,组成了完整的唱歌, 听歌, 羽毛球, 足球, 登山。
## 3.3 查找
### 1)allMatch(T->boolean)
检测是否全部满足参数行为,假如我们要检测是不是所有队员都是U21的球员:
```java
@Test
public void testUserStreamAllMatch(){
List userList = userMapper.getALL();
boolean isNotU21 = userList.stream().allMatch(user -> user.getAge() >= 21);
System.out.println("是否都不是U21球员:" + isNotU21);
}
```
执行结果为:
```java
是否都不是U21球员:true
```
### 2)anyMatch(T->boolean)
检测是否有任意元素满足给定的条件,比如,想知道是否有26岁的球员:
```java
@Test
public void testUserStreamAnyMatch(){
List userList = userMapper.getALL();
boolean isAgeU26 = userList.stream().anyMatch(user -> user.getAge() == 26);
System.out.println("是否有26岁的球员:" + isAgeU26);
}
```
执行结果为:
```java
是否有26岁的球员:true
```
### 3)noneMatch(T -> boolean)
流中是否有元素匹配给定的 T -> boolean 条件。比如我们要检测是否含有U18的队员:
```java
@Test
public void testUserStreamNoneMatch(){
List userList = userMapper.getALL();
boolean isNotU18 = userList.stream().noneMatch(user -> user.getAge() userList = userMapper.getALL();
Optional firstUser = userList.stream().sorted().findFirst();
System.out.println(firstUser.toString());
}
```
执行结果为:
```java
Optional[User(id=1, name=费尔南多, age=25)]
```
### 5)findAny():找到任意一个元素
```java
@Test
public void testUserFindAny(){
List userList = userMapper.getALL();
Optional anytUser = userList.parallelStream().sorted().findAny();
System.out.println(anytUser.toString());
}
```
执行结果为:
```java
Optional[User(id=2, name=费尔南迪尼奥, age=26)]
```
## 3.4 归纳计算
### 1)求队员的总人数
```java
@Test
public void testUserCount(){
List userList = userMapper.getALL();
long totalAge = userList.stream().collect(Collectors.counting());
System.out.println("队员人数为:" + totalAge);
}
```
执行结果为:
```java
队员人数为:6
```
### 2)得到某一属性的最大最小值
```java
@Test
public void testUserMaxAndMin(){
List userList = userMapper.getALL();
Optional userMaxAge = userList.stream().collect(Collectors.maxBy(Comparator.comparing(User::getAge)));
System.out.println("年龄最大的队员为:" + userMaxAge.toString());
Optional userMinAge = userList.stream().collect(Collectors.minBy(Comparator.comparing(User::getAge)));
System.out.println("年龄最小的队员为:" + userMinAge.toString());
}
```
执行结果为:
```java
年龄最大的队员为:Optional[User(id=6, name=克鲁伊夫, age=43)]
年龄最小的队员为:Optional[User(id=1, name=费尔南多, age=25)]
```
### 3)求年龄总和是多少
```java
@Test
public void testUserSummingInt(){
List userList = userMapper.getALL();
int totalAge = userList.stream().collect(Collectors.summingInt(User::getAge));
System.out.println("年龄总和为:" + totalAge);
}
```
执行结果为:
```java
年龄总和为:175
```
我们经常会用BigDecimal来记录金钱,假设想得到BigDecimal的总和:
// 获得列表对象金额, 使用reduce聚合函数,实现累加器
BigDecimal sum = myList.stream() .map(User::getMoney)
.reduce(BigDecimal.ZERO,BigDecimal::add);
### 4)求年龄平均值
```java
@Test
public void testUserAveragingInt(){
List userList = userMapper.getALL();
Double totalAge = userList.stream().collect(Collectors.averagingInt(User::getAge));
System.out.println("平均年龄为:" + totalAge);
}
```
执行结果为:
```java
平均年龄为:29.166666666666668
```
### 5)一次性得到元素的个数、总和、最大值、最小值
```java
@Test
public void testUserSummarizingInt(){
List userList = userMapper.getALL();
IntSummaryStatistics statistics = userList.stream().collect(Collectors.summarizingInt(User::getAge));
System.out.println("年龄的统计结果为:" + statistics );
}
```
执行结果为:
```java
年龄的统计结果为:IntSummaryStatistics{count=6, sum=175, min=25, average=29.166667, max=43}
```
### 6)字符串拼接
要将队员的姓名连成一个字符串并用逗号分割。
```java
@Test
public void testUserJoining(){
List userList = userMapper.getALL();
String name = userList.stream().map(User::getName).collect(Collectors.joining(","));
System.out.println("所有的队员名字:" + name );
}
```
执行结果为:
```java
所有的队员名字:费尔南多,费尔南迪尼奥,卡尔德克,阿德里安,隋维杰,克鲁伊夫
```
## 3.5 分组
在数据库操作中,我们经常通过GROUP BY关键字对查询到的数据进行分组,java8的流式处理也提供了分组的功能。使用Collectors.groupingBy来进行分组。
### 1)可以根据队员的年龄进行分组
```java
@Test
public void testUserGroupingBy(){
List userList = userMapper.getALL();
Map> ageMap = userList.stream().collect(Collectors.groupingBy(User::getAge));
for (Map.Entry> entry :ageMap.entrySet()){
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
}
```
执行结果为:
```java
key= 25 and value= [User(id=1, name=费尔南多, age=25)]
key= 26 and value= [User(id=2, name=费尔南迪尼奥, age=26), User(id=5, name=隋维杰, age=26)]
key= 43 and value= [User(id=6, name=克鲁伊夫, age=43)]
key= 27 and value= [User(id=3, name=卡尔德克, age=27)]
key= 28 and value= [User(id=4, name=阿德里安, age=28)]
```
结果是一个map,key为不重复的年龄,value为属于该年龄的队员列表。已经实现了分组。另外我们还可以继续分组得到两次分组的结果。
### 2)如果仅仅想统计各年龄的队员个数是多少,并不需要对应的list
按年龄分组并统计人数:
```java
@Test
public void testUserGroupingByCount(){
List userList = userMapper.getALL();
Map ageMap = userList.stream().collect(Collectors.groupingBy(User::getAge,Collectors.counting()));
for (Map.Entry entry :ageMap.entrySet()){
System.out.println("队员中" + entry.getKey() + "岁的队员人数为:" + entry.getValue());
}
}
```
执行结果为:
```java
队员中25岁的队员人数为:1
队员中26岁的队员人数为:2
队员中43岁的队员人数为:1
队员中27岁的队员人数为:1
队员中28岁的队员人数为:1
```
### 3)partitioningBy 分区
分区与分组的区别在于,分区是按照 true 和 false 来分的,因此partitioningBy 接受的参数的 lambda 也是 T -> boolean
```java
@Test
public void testUserPartitioningBy (){
List userList = userMapper.getALL();
Map> partitioningByMap = userList.stream().collect(partitioningBy(user -> user.getAge() >= 30));
for (Map.Entry> entry :partitioningByMap.entrySet()){
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
}
```
执行结果为:
```java
key= false and value= [User(id=1, name=费尔南多, age=25), User(id=2, name=费尔南迪尼奥, age=26), User(id=3, name=卡尔德克, age=27), User(id=4, name=阿德里安, age=28), User(id=5, name=隋维杰, age=26)]
key= true and value= [User(id=6, name=克鲁伊夫, age=43)]
```
***
【**写在后面的话**】留下stream的类实现的方法和依赖图,前面的实践也只是挑选了几个比较常用的Api。

Java 8 Stream实践的更多相关文章
- Java 8 Stream API的使用示例
前言 Java Stream API借助于Lambda表达式,为Collection操作提供了一个新的选择.如果使用得当,可以极大地提高编程效率和代码可读性. 本文将介绍Stream API包含的方法 ...
- Java 8 Stream API详解--转
原文地址:http://blog.csdn.net/chszs/article/details/47038607 Java 8 Stream API详解 一.Stream API介绍 Java8引入了 ...
- Java 理论与实践: 处理 InterruptedException
捕捉到它,然后怎么处理它? 很多 Java™ 语言方法,例如 Thread.sleep() 和 Object.wait(),都可以抛出InterruptedException.您不能忽略这个异常,因为 ...
- java之stream(jdk8)
一.stream介绍 参考: Java 8 中的 Streams API 详解 Package java.util.stream Java8初体验(二)Stream语法详解 二.例子 im ...
- paip.myeclipse7 java webservice 最佳实践o228
paip.myeclipse7 java webservice 最佳实践o228 java的ws实现方案:jax-ws>>xfire ws的测试工具 webservice测试调用工具W ...
- Java 理论与实践: 非阻塞算法简介——看吧,没有锁定!(转载)
简介: Java™ 5.0 第一次让使用 Java 语言开发非阻塞算法成为可能,java.util.concurrent 包充分地利用了这个功能.非阻塞算法属于并发算法,它们可以安全地派生它们的线程, ...
- Java 理论与实践: 流行的原子——新原子类是 java.util.concurrent 的隐藏精华(转载)
简介: 在 JDK 5.0 之前,如果不使用本机代码,就不能用 Java 语言编写无等待.无锁定的算法.在 java.util.concurrent 中添加原子变量类之后,这种情况发生了变化.请跟随并 ...
- Java 理论和实践: 了解泛型
转载自 : http://www.ibm.com/developerworks/cn/java/j-jtp01255.html 表面上看起来,无论语法还是应用的环境(比如容器类),泛型类型(或者泛型) ...
- Java 8 Stream API Example Tutorial
Stream API Overview Before we look into Java 8 Stream API Examples, let’s see why it was required. S ...
随机推荐
- ZooKeeper入门(三) ZooKeeper数据模型
1 简述 ZooKeeper可以看成一种高可用性的文件系统,但是,它没有文件和目录,而是使用节点,称为znode. znode可以作为保存数据的容器(如同文件),也可以作为保存其他节点的容器(如同目录 ...
- Codeforces 758D:Ability To Convert(思维+模拟)
http://codeforces.com/problemset/problem/758/D 题意:给出一个进制数n,还有一个数k表示在n进制下的值,求将这个数转为十进制最小可以是多少. 思路:模拟着 ...
- 无法启动iis express web服务器解决
VS2013 .VS2015 .VS2017调试出现无法启动iis express web服务器 最近自己老是遇到这个问题,天天如此,烦死人,网上答案繁多,但是都解决不了,也是由于各种环境不同导致的, ...
- C#中产生SQL语句的几种方式
(1)拼接产生SQL语句: string sql = "insert into czyb(yhm,mm,qx) values('" + txtName.Text + "' ...
- kuangbin专题 专题一 简单搜索 非常可乐 HDU - 1495
题目链接:https://vjudge.net/problem/HDU-1495 题意:有两个空杯(分别是N升和M升)和一罐满的可乐S升,S = N + M,三个容器可以互相倾倒,如果A倒入B,只有两 ...
- 走近Java之包装器类Integer
前几天,有个同事问了我一个关于Integer类赋值的问题,很有意思,我们一起来看一下(如果有说的不正确的地方,欢迎大家指正). 如上图,同样是赋值,但是两次比较的结果完全不同.我们走近了解一下. 在I ...
- DataGrid通过DataSet保存为xml文件,并导入
做了个小的DataGrid通过DataSet保存为xml_测试,DataGrid通过DataSet保存为xml_测试,通过dataSet.writeXML()和dataSet.readXML()方法完 ...
- python安装及typora使用
第一章 环境搭建 1.1Python安装 1.1.1python官网www.python.org 1.1.2根据电脑系统选择下载 1.1.3确定电脑系统属性,此处我们以win10的64位操作系统为例 ...
- NOIP2018提高/普及成绩
明天就要出了,不忍看到自己爆零,现在很慌. 大家都考的如何呢?欢迎留言自己的分数或预估分数.
- 网络IP的操作
10.10.10.10/8求解问题:子网掩码 10.255.255.255该IP地址所在网络的网络ID 10.0.0.0该IP地址所在网络的广播地址 10.255.255.255该IP地址所在网络的I ...