用Python完成毫秒级抢单,助你秒杀淘宝大单
目录:
- 引言
- 环境
- 需求分析&前期准备
- 淘宝购物流程回顾
- 秒杀的实现
- 代码梳理
- 总结
0 引言
年中购物618大狂欢开始了,各大电商又开始了大力度的折扣促销,我们的小胖又给大家谋了一波福利,淘宝APP直接搜索:小胖发福利,每天领取三次粉丝专属现金大红包。
有了现金大红包,如何做到更省钱的剁手呢?今天给大家提供一种思路,用Python实现秒杀订单,借用自动化方式完成最优解。
1 环境
操作系统:Windows
Python版本:3.7.2
2 需求分析&前期准备
2.0 需求分析
我们的目标是秒杀淘宝的订单,这里面有几个关键点,首先需要登录淘宝,其次你需要准备好订单,最后要在指定时间快速提交订单。
登录淘宝,这里就要用到一个爬虫利器Selenium,它是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等等操作,所见即所得。另外对于一些 JavaScript 渲染的页面来说,此种抓取方式非常有效。
2.1 Selenium的安装
Selenium 的安装很简单,可采用如下方式。
pip install selenium
Selenium安装好之后,并不能直接使用,它需要与浏览器进行对接。这里拿Chrome浏览器为例。若想使用Selenium成功调用Chrome浏览器完成相应的操作,需要通过ChromeDriver来驱动。
2.2 ChromeDriver的安装
这里是ChromeDriver的官方下载地址。
链接:
https://chromedriver.storage.googleapis.com/index.html
我们在下载之前先来确认下我们使用的Chrome浏览器版本。
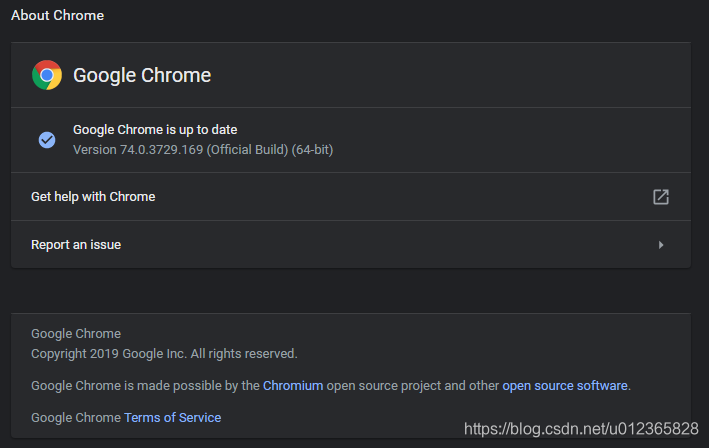
通过ChromeDriver的下载链接,找到与之对应的Chrome浏览器版本,根据你电脑系统的平台类型进行下载。
下载完成之后,解压,将其放置在Python安装路径下Scripts文件夹中即可
上述操作结束后,我们执行如下命令,测试一下
from selenium import webdriver
# 打开Chrome浏览器
browser = webdriver.Chrome()
代码执行后,若成功打开了浏览器,则证明你的ChromeDriver安装的没问题,可以正常愉快地使用Selenium了。
接下来,我们先来回顾下淘宝购物流程。
3 淘宝购物流程回顾
3.1 首先要打开淘宝网站
换作使用Seleuinm方式,代码如下:
browser.get("https://www.taobao.com")
3.2 我们登录淘宝才能进行下一步操作
换成Seleuinm方式,代码:
browser.find_element_by_link_text("亲,请登录").click()
这时我们就要就跳到了一个扫码登录的页面,我们用手机进行扫码,登录成功之后进行下一步。
3.3 登录成功之后,我们来打开购物车,链接如下:
https://cart.taobao.com/cart.htm
换成Seleuinm方式,代码:
browser.get("https://cart.taobao.com/cart.htm")
3.4 我们想要全选购物车中的商品,直接点击全选即可
换成Seleuinm方式,代码:
browser.find_element_by_id("J_SelectAll1").click()
注:若你的购物车商品比较多,又不想全选购买,那就 手动 勾选想要下单的商品。
3.5 勾选好商品后就可以“结算”下单
换成Seleuinm方式,代码即:
browser.find_element_by_link_text("结 算").click()
3.6 等待提交完订单后才算数
换成Seleuinm方式,代码即:
browser.find_element_by_link_text('提交订单').click()
3.7 订单成功秒下之后,接下来的付款,慢慢来就好。
4 秒杀的实现
秒杀的实现,思路也很简单。这里有两个时间点,一是抢购时间,一是当前时间。只需要比较这两个时间点,到了抢购时间立即下单即可。
记录时间,需要使用datetime这个内置模块,代码如下:
import datetime
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
5 代码梳理
首先得登录淘宝,这里我们定义一个login函数
def login():
# 打开淘宝首页,通过扫码登录
browser.get("https://www.taobao.com")
time.sleep(3)
if browser.find_element_by_link_text("亲,请登录"):
browser.find_element_by_link_text("亲,请登录").click()
print(f"请尽快扫码登录")
time.sleep(10)
接下来就是勾选购物车中的商品,这里我们定义一个picking函数
def picking(method):
# 打开购物车列表页面
browser.get("https://cart.taobao.com/cart.htm")
time.sleep(3)
# 是否全选购物车
if method == 0:
while True:
try:
if browser.find_element_by_id("J_SelectAll1"):
browser.find_element_by_id("J_SelectAll1").click()
break
except:
print(f"找不到购买按钮")
else:
print(f"请手动勾选需要购买的商品")
time.sleep(5)
等待抢购时间,定时秒杀,这里我们定义一个buy函数
def buy(times):
while True:
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
# 对比时间,时间到的话就点击结算
if now > times:
# 点击结算按钮
while True:
try:
if browser.find_element_by_link_text("结 算"):
browser.find_element_by_link_text("结 算").click()
print(f"结算成功,准备提交订单")
break
except:
pass
# 点击提交订单按钮
while True:
try:
if browser.find_element_by_link_text('提交订单'):
browser.find_element_by_link_text('提交订单').click()
print(f"抢购成功,请尽快付款")
except:
print(f"再次尝试提交订单")
time.sleep(0.01)
6 总结
短短几十行代码就能秒杀淘宝订单,赶紧行动起来吧!记着,每天在淘宝上搜索小胖发福利,领取粉专属福利哟~
关注公众号「Python专栏」,后台回复「抢单器」获取全套代码!
用Python完成毫秒级抢单,助你秒杀淘宝大单的更多相关文章
- Python 实现毫秒级淘宝、京东、天猫等秒杀抢购脚本
本篇文章主要介绍了Python 通过selenium实现毫秒级自动抢购的示例代码,通过扫码登录即可自动完成一系列操作,抢购时间精确至毫秒,可抢加购物车等待时间结算的,也可以抢聚划算的商品. 该思路可运 ...
- python 获得毫秒级时间戳
import time import datetime t = time.time() print (t) #原始时间数据 print (int(t)) #秒级时间戳 print (int(round ...
- Python网络爬虫(6)--爬取淘宝模特图片
经过前面的一些基础学习,我们大致知道了如何爬取并解析一个网页中的信息,这里我们来做一个更有意思的事情,爬取MM图片并保存.网址为https://mm.taobao.com/json/request_t ...
- python 网路爬虫(二) 爬取淘宝里的手机报价并以价格排序
今天要写的是之前写过的一个程序,然后把它整理下,巩固下知识点,并对之前的代码进行一些改进. 今天要爬取的是淘宝里的关于手机的报价的信息,并按照自己想要价格来筛选. 要是有什么问题希望大佬能指出我的错误 ...
- selenium+python自动化84-chrome手机wap模式(登录淘宝页面)
前言 chrome手机wap模式登录淘宝页面,点击验证码无效问题解决. 切换到wap模式,使用TouchActions模块用tap方法触摸 我的环境 chrome 62 chromedriver 2. ...
- PYTHON 爬虫笔记十:利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB(实战项目三)
利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB 目标站点分析 淘宝页面信息很复杂的,含有各种请求参数和加密参数,如果直接请求或者分析Ajax请求的话会很繁琐.所以我们可 ...
- Python爬虫系列-Selenium+Chrome/PhantomJS爬取淘宝美食
1.搜索关键字 利用Selenium驱动浏览器搜索关键字,得到查询后的商品列表 2.分析页码并翻页 得到商品页码数,模拟翻页,得到后续页面的商品列表 3.分析提取商品内容 利用PyQuery分析源码, ...
- Python开源爬虫项目代码:抓取淘宝、京东、QQ、知网数据--转
数据来源:数据挖掘入门与实战 公众号: datadw scrapy_jingdong[9]- 京东爬虫.基于scrapy的京东网站爬虫,保存格式为csv.[9]: https://github.co ...
- Python 教你识别淘宝刷单,买到称心如意的商品
发际线堪忧的小 Q,为了守住头发最后的尊严,深入分析了几十款防脱洗发水的评价,最后综合选了一款他认为最完美的防脱洗发水. 一星期后,他没察觉到任何变化. 一个月后,他用卷尺量了量,发际线竟然后退了 0 ...
随机推荐
- 死磕 java同步系列之AQS终篇(面试)
问题 (1)AQS的定位? (2)AQS的重要组成部分? (3)AQS运用的设计模式? (4)AQS的总体流程? 简介 AQS的全称是AbstractQueuedSynchronizer,它的定位是为 ...
- Core源码(三) Lazy<T>
Lazy<T>解决什么问题? 1.大对象加载 考虑下面的需求,有个对象很大,创建耗时,并且要在托管堆上分配一大块空间.我们当然希望,用到它的时候再去创建.也就是延迟加载,等到真正需要它的时 ...
- go-控制语句
if else else不能换行 if后最好不加小括号,当然可以加,但建议不加 求平方根 引入math包 调用math.Sqrt(num)函数 switch分支 不用加break来跳出,每一个case ...
- JVM垃圾回收器原理及使用介绍
JVM垃圾回收器原理及使用介绍 垃圾收集基础 引用计数法(Reference Counting) 标记-清除算法(Mark-Sweep) 复制算法(Copying) 标记-压缩算法(Mark-Comp ...
- Junit单元测试数据生成工具类
在Junit单元测试中,经常需要对一些领域模型的属性赋值,以便传递给业务类测试,常见的场景如下: com.enation.javashop.Goods goods = new com.enation. ...
- RPA之AA
RoboticProcessAutomation(即机器人流程自动化),RPA机器人能够模仿大多数人类用户的行为, 比如可以登录应用程序,移动文件和文件夹,复制和粘贴数据,填写表单,从文档中提取结构化 ...
- [转]Spring Cloud在国内中小型公司能用起来吗?
原文地址:http://www.cnblogs.com/ityouknow/p/7508306.html 原文地址:https://www.zhihu.com/question/61403505 今天 ...
- [日常] git版本回退
还没有push到远程的时候,版本回退的测试如下 先克隆一个空的测试仓库,这是我自己在gitlab里创建的空仓库git clone http://192.168.1.114:8090/admintsh/ ...
- LInkHashMap源码分析
说LinkHashMap之前,我们先来谈谈什么是LRU算法? 按照英文的直接原义就是Least Recently Used,最近最久未使用法,它是按照一个非常注明的计算机操作系统基础理论得来的:最近使 ...
- docker使用,包括有nvidia-docker
docker run 命令:https://www.runoob.com/docker/docker-run-command.html docker run -it ubuntu:15.10 /bin ...