Python爬虫实战:批量下载网站图片
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: GitPython
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
1.获取图片的url链接
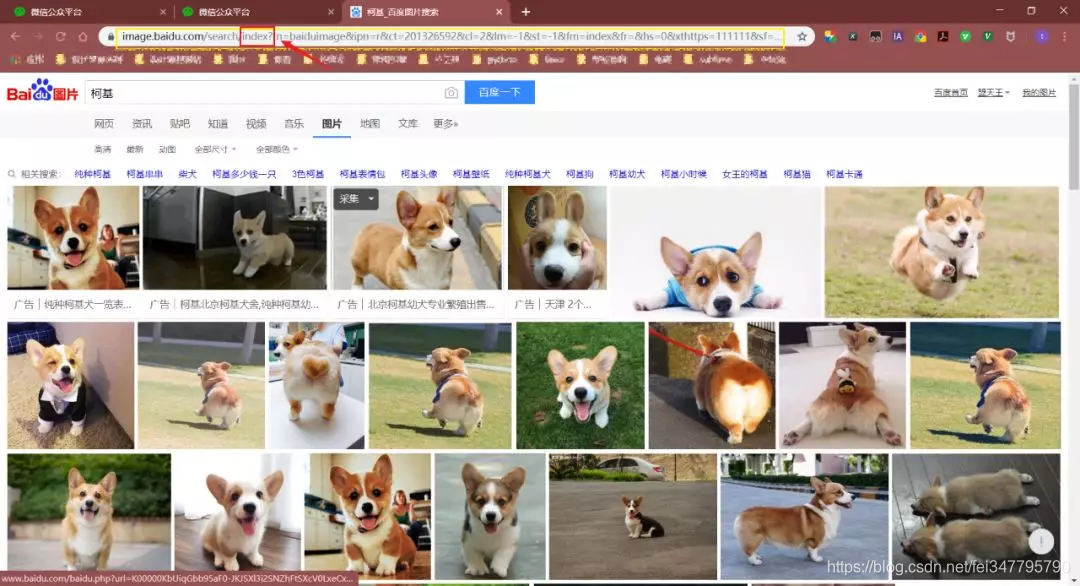
首先,打开百度图片首页,注意下图url中的index
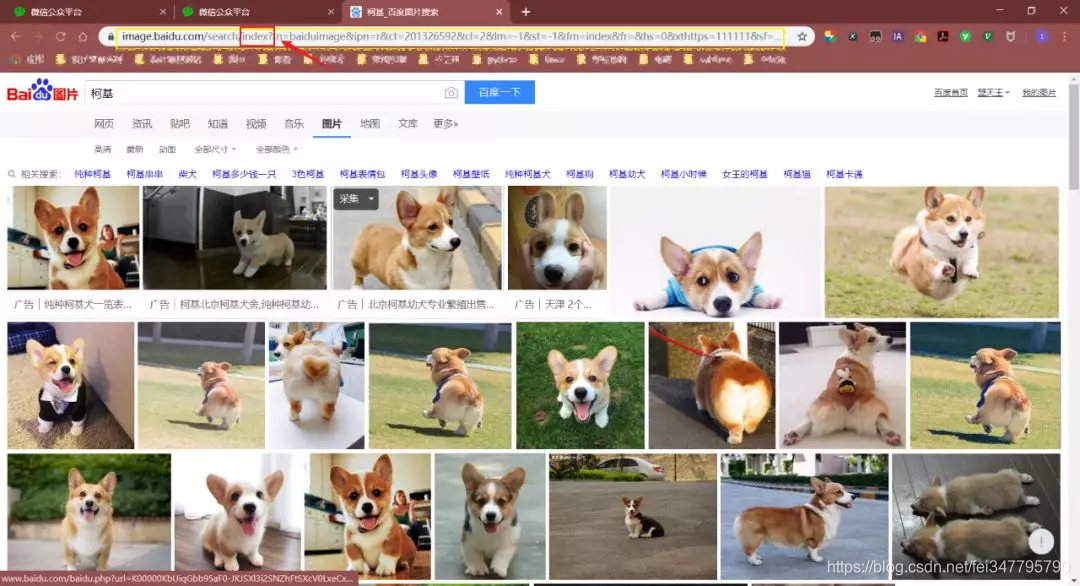
接着,把页面切换成传统翻页版(flip),因为这样有利于我们爬取图片!
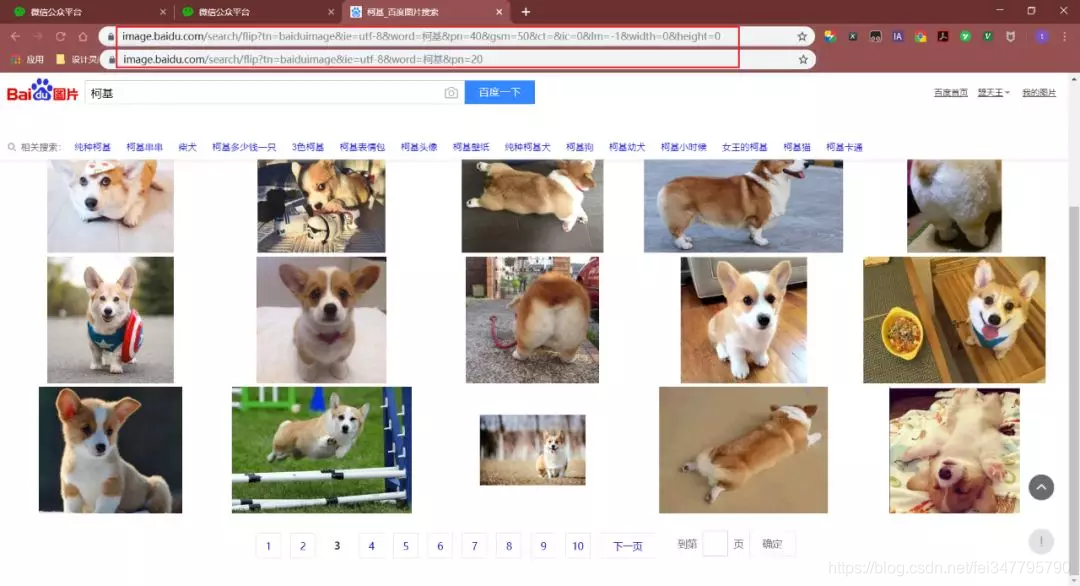
对比了几个url发现,pn参数是请求到的数量。通过修改pn参数,观察返回的数据,发现每页最多只能是60个图片。
注:gsm参数是pn参数的16进制表达,去掉无妨
然后,右键检查网页源代码,直接(ctrl+F)搜索 objURL
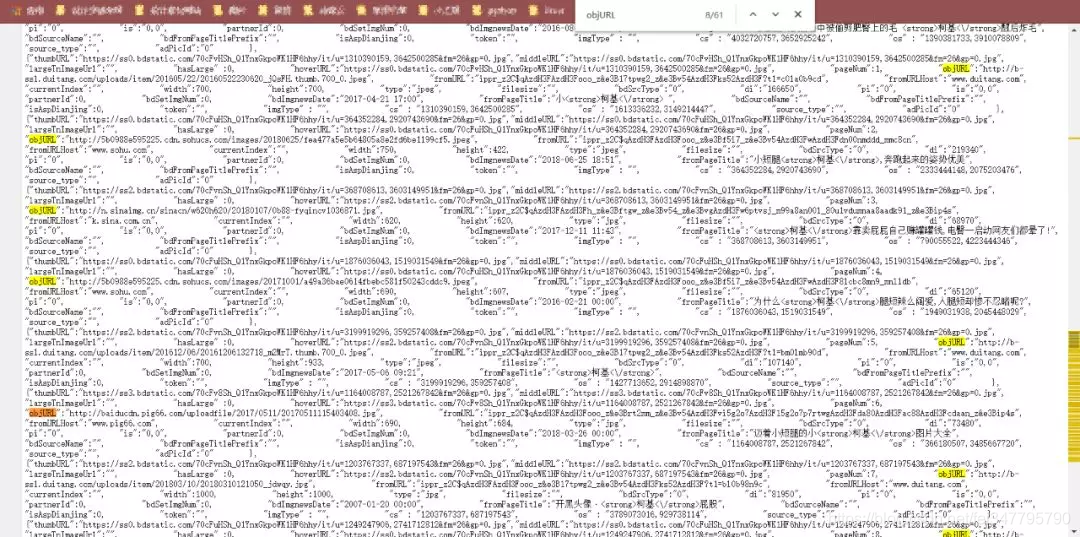
这样,我们发现了需要图片的url了。
2.把图片链接保存到本地
现在,我们要做的就是将这些信息爬取出来。
注:网页中有objURL,hoverURL…但是我们用的是objURL,因为这个是原图
那么,如何获取objURL?用正则表达式!
那我们该如何用正则表达式实现呢?其实只需要一行代码…
results = re.findall('"objURL":"(.*?)",', html)
核心代码:
1.获取图片url代码:
# 获取图片url连接
def get_parse_page(pn,name):
for i in range(int(pn)):
# 1.获取网页
print('正在获取第{}页'.format(i+1))
# 百度图片首页的url
# name是你要搜索的关键词
# pn是你想下载的页数
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s&pn=%d' %(name,i*20)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400'}
# 发送请求,获取相应
response = requests.get(url, headers=headers)
html = response.content.decode()
# print(html)
# 2.正则表达式解析网页
# "objURL":"http://n.sinaimg.cn/sports/transform/20170406/dHEk-fycxmks5842687.jpg"
results = re.findall('"objURL":"(.*?)",', html) # 返回一个列表
# 根据获取到的图片链接,把图片保存到本地
save_to_txt(results, name, i)
2.保存图片到本地代码:
# 保存图片到本地
def save_to_txt(results, name, i):
j = 0
# 在当目录下创建文件夹
if not os.path.exists('./' + name):
os.makedirs('./' + name)
# 下载图片
for result in results:
print('正在保存第{}个'.format(j))
try:
pic = requests.get(result, timeout=10)
time.sleep(1)
except:
print('当前图片无法下载')
j += 1
continue
# 可忽略,这段代码有bug
# file_name = result.split('/')
# file_name = file_name[len(file_name) - 1]
# print(file_name)
#
# end = re.search('(.png|.jpg|.jpeg|.gif)$', file_name)
# if end == None:
# file_name = file_name + '.jpg'
# 把图片保存到文件夹
file_full_name = './' + name + '/' + str(i) + '-' + str(j) + '.jpg'
with open(file_full_name, 'wb') as f:
f.write(pic.content)
j += 1
3.主函数代码:
# 主函数
if __name__ == '__main__':
name = input('请输入你要下载的关键词:')
pn = input('你想下载前几页(1页有60张):')
get_parse_page(pn,
使用说明:
# 配置以下模块
import requests
import re
import os
import time
# 1.运行 py源文件
# 2.输入你想搜索的关键词,比如“柯基”、“泰迪”等
# 3.输入你想下载的页数,比如5,那就是下载 5 x 60=300 张图片
Python爬虫实战:批量下载网站图片的更多相关文章
- Python爬虫实战 批量下载高清美女图片
彼岸图网站里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过python爬虫批量下载网站里的高清美女图片,熟悉python写爬虫的基本方法: ...
- 批量下载网站图片的Python实用小工具(下)
引子 在 批量下载网站图片的Python实用小工具 一文中,讲解了开发一个Python小工具来实现网站图片的并发批量拉取.不过那个工具仅限于特定网站的特定规则,本文将基于其代码实现,开发一个更加通用的 ...
- 批量下载网站图片的Python实用小工具
定位 本文适合于熟悉Python编程且对互联网高清图片饶有兴趣的筒鞋.读完本文后,将学会如何使用Python库批量并发地抓取网页和下载图片资源.只要懂得如何安装Python库以及运行Python程序, ...
- 利用python爬虫关键词批量下载高清大图
前言 在上一篇写文章没高质量配图?python爬虫绕过限制一键搜索下载图虫创意图片!中,我们在未登录的情况下实现了图虫创意无水印高清小图的批量下载.虽然小图能够在一些移动端可能展示的还行,但是放到pc ...
- python爬虫实战(3)--图片下载器
本篇目标 1.输入关键字能够根据关键字爬取百度图片 2.能够将图片保存到本地文件夹 1.URL的格式 进入百度图片搜索apple,这时显示的是瀑布流版本,我们选择传统翻页版本进行爬取.可以看到网址为: ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 制作爬虫的基本步骤 顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤. 一般来说,制作一个爬虫需要分以下几个步骤: 分析需求(对,需求分析非常重要, ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
- python多线程批量下载远程图片
python多线程使用场景:多线程采集, 以及性能测试等 . 数据库驱动类-简单封装下 mysqlDriver.py #!/usr/bin/python3 #-*- coding: utf-8 -*- ...
随机推荐
- https揭秘
首先简要说明一下所谓的https证书是什么东西:打个比方,你第一次去银行办理业务的时候都需要手持本人身份中去办理业务,这个身份证从哪里来呢,没错,是从国家相关机关得来的,在中国内是通用的,类比到htt ...
- Win10无法安装.NET Framework3.5的解决办法
诸位网友如果工作中使用WIN10遇到如图的这种问题,现将解决办法整理如下: 一.第一步就是修复系统:按“Windows+X”点击“Windows PowerShell(管理员)&命令提示符(管 ...
- HTTPS工作流程(入门)
1.CA(为服务器做担保的第三方机构)将包含CA[公钥C]等信息的[证书C]发送给浏览器: 2.服务器将其[公钥S]和网站信息发送给CA: 3.CA用CA[私钥C]将这些信息加密得到了签名后的[服务器 ...
- 高德APP全链路源码依赖分析工程
一.背景 高德 App 经过多年的发展,其代码量已达到数百万行级别,支撑了高德地图复杂的业务功能.但与此同时,随着团队的扩张和业务的复杂化,越来越碎片化的代码以及代码之间复杂的依赖关系带来诸多维护性问 ...
- 《跟唐老师学习云网络》 -第5篇 Ping喂报文
[摘要] 这一章节你的角色是国王,你要派一个小兵去对方打探一下.是站在你的角度看这个小兵.哦,对了,这个小兵的名字叫"喂". 一.Ping命令介绍 ping就是用来检测一下网络能不 ...
- Unknown class XXViewController in Interface Builder file.”问题处理
“Unknown class XXViewController in Interface Builder file.”问题处理 在静态库中写了一个XXViewController类,然后在主工程的 ...
- React-Native项目在Android真机上调试
目录 1.确保你的设备已经成功连接.可以终端输入adb devices来查看: 2.终端运行npm start 开启本地服务,成功后运行react-native run-android来在设备上安装并 ...
- HTML5学习第二天!
学习了一天,然后整理内容到现在,感觉昨天的学习效率有点差,哎! 感受尽在代码中,布局真的脑壳疼,仅仅只整理了CSS中的list: <!DOCTYPE html> <html> ...
- ansible批量管理常见的配置方法
第7章 ansible的管理 7.1 ansible概念的介绍 ansible-playbook –syntax 检查语法 ansible-playbook -C ...
- linux—ln
1. 软连接:不可删除源文件,删除源文件导致链接文件找不到,出现红色闪烁. 2. 硬链接: 源文件删除后,链接文件可以正常打开,链接前后的文件inode号相同,硬链接只能针对文件做链接,,不能针 ...