yolov3和ssd的区别
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
初步总结的SSD和yolo-v3之间的一些区别。
其中的一些概念还有待充分解释。
| SSD | YOLOv3 | |
|---|---|---|
| Loss | Softmax loss | Logistic loss |
| Feature extractor | VGG19 | Darknet-53 |
| Bounding Box Prediction | direct offset with default box | offset with gird cell by sigmoid activation |
| Anchor box | Different scale and aspect ratio | K-means from coco and VOC |
| Small objects | Semantic value for bottom layer is not high. Worse for small objects. | Higher resolution layers have higher semantic values. Better for small objects. |
| Big objects | Better. Feature map rangers from 38 * 38 to 3 * 3 ,1 * 1. | Worse. 13 * 13 feature map is the most coarse-grained. |
| Data Augmentation | different sample IOU crop on original image | randomly put the scaled original image (from 0.25 to 2) on the gray canvas |
| Input | resize original image to fixed size | Random multi-scale input |
| FPN | no | with FPN |
SSD的loss中,不同类别的分类器是softmax,最终检测目标的类别只能是一类。而在yolo-v3中,例如对于80类的coco数据集,对于类别进行判断是80个logistic分类器,只要输出大于设置的阈值,则都是物体的类别,物体同时可以属于多类,例如一个物体同时是person和woman。
Backbone network。ssd原版的基础网络就是VGG19,也可以用mobile-net、resnet等。yolo-v3的基础网络是作者自己设计的darknet-53(因为具有53个卷积层),借鉴了resnet的shortcut层,根据作者的话,以更少的参数、更少的计算量实现了接近的效果。
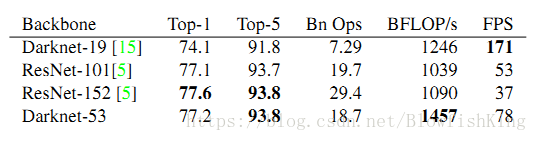
Anchor box。ssd从faster-rcnn中吸收了这一思想,采用的是均匀地将不同尺寸的default box分配到不同尺度的feature map上。例如6个feature map的尺度,default box的大小从20%到90%的占比,同时有aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]] ,最终可以计算出不同default box大小。而yolo-v3延续了yolo-v2的方法:从coco数据集中对bouding box 的(width, height)进行聚类,作者聚出9类,每类中心点取出作为一个box_size, 将每三个box_size划分给一个feature map。例如总共有(10,13), (16,30), (33,23), (30,61), (62,45), (59,119), (116,90), (156,198), (373,326)共9组w,h, 作者将后三个(116,90), (156,198), (373,326)作为13 * 13 的gird cell上的anchor box size。
图片输入。yolo-v3将输入图片映射到第一层feature map的固定比例是32。对于输入为416 * 416的图片,第一层feature map 大小为13 * 13。但是yolo-v3支持从300到600的所有32的倍数的输入。例如输入图片为320 * 320,这样第一层feature map就为10 * 10,在这样的gird cell中同样可以进行predict和match groudtruth。
Bounding Box 的预测方法。在不同的gird cell上,SSD预测出每个box相对于default box的位置偏移和宽高值。yolo-v3的作者觉得这样刚开始训练的时候,预测会很不稳定。因为位置偏移值在float的范围内都有可能,出现一个很大的值的话,位置都超出图片范围了,都是完全无效的预测了。所以yolov3的作者对于这位置偏移值都再做一个sigmoid激活,将范围缩为0-1 。b_x和b_y的值在(cell_x_loc, cell_x_loc+1), (cell_y_loc, cell_y_loc+1)之间波动。
- yolov3为什么比ssd好.
不仅仅因为YOLO V3引入FPN结构,同时它的检测层由三级feature layers融合,而SSD的六个特征金字塔层全部来自于FCN的最后一层,其实也就是一级特征再做细化,明显一级feature map的特征容量肯定要弱于三级,尤其是浅层包含的大量小物体特征。
https://www.zhihu.com/question/269909535/answer/471978963
yolov3和ssd的区别的更多相关文章
- emmc和ssd的区别【转】
本文转载自:https://blog.csdn.net/hawk_lexiang/article/details/78228789 emmc和ssd eMMC和SSD主要是满足不同需求而发展出来的NA ...
- one-stage object detectors(1)
2019/04/08 强烈推荐:深入理解one-stage目标检测算法 yolo系列 one-stage object detectors(YOLO and SSD) 在不专一的模型中,每个检测器应该 ...
- 深度学习笔记(十三)YOLO V3 (Tensorflow)
[代码剖析] 推荐阅读! SSD 学习笔记 之前看了一遍 YOLO V3 的论文,写的挺有意思的,尴尬的是,我这鱼的记忆,看完就忘了 于是只能借助于代码,再看一遍细节了. 源码目录总览 tens ...
- The Accidental DBA
The Accidental DBA (Day 1 of 30): Hardware Selection: CPU and Memory Considerations 本文大意: 全篇主要讲 ...
- (转)Awesome Object Detection
Awesome Object Detection 2018-08-10 09:30:40 This blog is copied from: https://github.com/amusi/awes ...
- TextBoxes 与 TextBoxes ++
TextBoxes 论文关键idea 本文和SegLink一样,也是在SSD的基础上进行改进的.相比SSD做了以下的改进: 修改了default box的apect ratio,分别为[1 2 3 5 ...
- mysql特性及部署规范
--分支版本,mysql对cpu,内存,io子系统资源利用特点--oracle mysql,mariadb,percona server--部署规范建议,系统安装,mysql安装,其他规范互联网业务为 ...
- paper-list
1.yolo-v1,yolo-v2,yolo-v3 2.ssd,focal loss,dssd 3.fast-rcnn,faster-rcnn,r-fcn,Light-Head R-CNN,R-FCN ...
- 目标检测论文解读10——DSSD
背景 SSD算法在检测小目标时精度并不高,本文是在在SSD的基础上做出一些改进,引入卷积层,能综合上下文信息,提高模型性能. 理解 Q1:DSSD和SSD的区别有哪些? (1)SSD是一层一层下采样, ...
随机推荐
- GUI程序分析实例
GUI程序开发概述 GUI程序开发原理 GetMessage(&msg)将消息队列中的消息取出来,在循环中进行处理. GUI程序开发的本质
- 《移动WEB前端高级开发实践@www.java1234.com.pdf》——2
5.3 作用域.闭包和this let 声明的变量只存在于其所在的代码块中 由于 JS 是基于词法(静态)作用域的语言,词法作用域的含义是在函数定义时就确定了作用域,而不是函数执行时再确定 calcu ...
- 痞子衡嵌入式:飞思卡尔i.MX RTyyyy系列MCU特性那些事(2)- RT1052DVL6性能实测(CoreMark)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是飞思卡尔i.MX RTyyyy系列MCU的性能. 在前面的文章 i.MXRTyyyy微控制器概览 里,痞子衡给大家简介过恩智浦半导体在2 ...
- GO-切片拷贝以及赋值
一.拷贝 package main import "fmt" func main(){ //copy函数,把一个切片copy到另一个切片之上 var a [1000]int=[10 ...
- C# 利用itextsharp、Spire配合使用为pdf文档每页添加水印
下载类库: 直接下载 引入类库 功能实现 using iTextSharp.text.pdf; using Spire.Pdf; using Spire.Pdf.Graphics; using Sys ...
- jquery实现get的异步请求
<%@ page contentType="text/html;charset=UTF-8" language="java" %><html& ...
- Cesium区分单击【LEFT_CLICK】和双击事件【LEFT_DOUBLE_CLICK】
问题描述 在cesium中,用户鼠标左键双击视图或Entity时,实际触发的是两次click和一次dbclick事件,非常影响代码设计,本文记录了如何区分单击[LEFT_CLICK]和双击事件[LEF ...
- m3u8视频格式分析
“ 学习m3u8格式.” 一段时间之前,乘着某美女CEO的东风,学习了一个新的数据格式,即m3u8格式. 经过一段时间的沉淀,美女CEO的热潮大概已经褪去,今天才对这个格式进行分析,嘻嘻. 先介绍下来 ...
- SAP SD如何将销售订单其它ITEM加入到一个已创建好的交货单里
SAP SD如何将销售订单其它ITEM加入到一个已创建好的交货单里 如下的销售订单,有多个ITEM, 为其中的第一个ITEM创建了DN 80016362, 如果业务发现需要修改该交货单,将销售订单里的 ...
- 【React Native】在原生和React Native间通信(RN调用原生)
一.从React Native中调用原生方法(原生模块) 原生模块是JS中也可以使用的Objective-C类.一般来说这样的每一个模块的实例都是在每一次通过JS bridge通信时创建的.他们可以导 ...