【学习笔记】第二章 python安全编程基础---python爬虫基础(urllib)
一、爬虫基础
1.爬虫概念
网络爬虫(又称为网页蜘蛛),是一种按照一定的规则,自动地抓取万维网信息的程序或脚本。用爬虫最大的好出是批量且自动化得获取和处理信息。对于宏观或微观的情况都可以多一个侧面去了解;
2.urllib库
urllib是python内置的HTTP请求库,旗下有4个常用的模块库:
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
3.urllib常用函数
接下来我们要具体介绍urllib模块常用的4个函数方法:
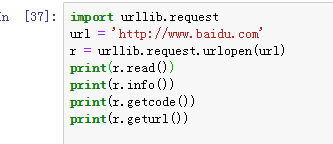
3.1 urllib.request.urlopen(url,data,timeout) 创建一个表示远程URL的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据;
urlopen返回对象提供方法:
read(),readline(),readlines(),fileno(),close():对HTTPResponse类型数据进行操作。
info():返回HTTPResponse对象,表示远程服务器返回的头信息。
getcode():返回http状态码。
geturl():返回请求的url。
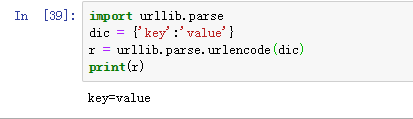
3.2 urllib.parse.urlencode(dict) 将dict或者包含两个元素的元组列表转换成url参数。
例如:字典{'name':'dark-bull','age':200}将被转换为‘name=dark-bull&age=200’

3.3 urllib.request.ProxyHandler(dict) 可以讲dict字典里的ip当作代理进行设置。
网站对某个ip做了限制、封锁时,可以用该方法当成代理去设置

通过代理设置一个http的请求;
3.4 urllib.parse.urlparse(urlstring,scheme='',allow_fragments=True) URL解析函数的重点是将URL字符串拆分为其组件,或者将URL组件合为一个URL字符串。

3.5 urllib.request.urlretrieve(url,filename=None,reporthook=None,data=None)
rulretrieve()方法直接将远程数据下载到本地。
参数url 指定url请求的地址
参数filename指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据)
参数reporthook是一个回调函数,当连接上服务器,以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
参数data指post到服务器的数据,该方法返回一个包含两个元素的(filename,headers)元组,filename表示保存到本地的路径,header表示服务器的响应头。



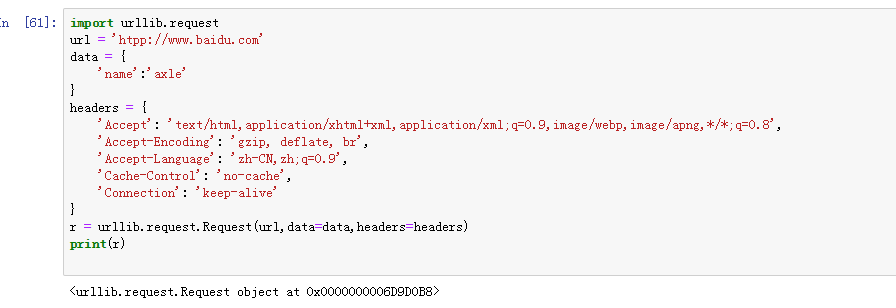
3.6 urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
常用参数:
url:访问的地址
data:此参数为可选字段,其中传递的参数需要转为bytes,如果是字典我们只需要通过urllib.parse.urlencode转换即可:
headers:http相应headers传递的信息,构造方法:headers参数传递,通过调用Request对象的 add_header()方法来添加请求头。
(python3.x爬虫基础---http headers详解,可参考此文章。)
3.7 urllib.request.HTTPCookieProcessor()
网站中通过cookie进行判断权限是很常见的,那么我们可以通过urllib.request.HTTPCookieProcesor(cookie)来操作cookie。使用Cookie和使用代理IP一样,也需要创建一个自己的opener。在HTTP包中,提供了cookiejar模块,用于提供对Cookie的支持。http.cookiejar功能强大,我们可以利用本模块的CookieJar类的对象来捕获cookie并在后续链接请求时重新发送,比如可以实现模拟登陆功能,该模块主要的对象有cookieJar、FileCookieJar、MozillCookieJar、LWOCookieJar。
用该函数模拟用户登录的cookie

二、urllib异常处理
当抓取某个网站,出现超时异常;
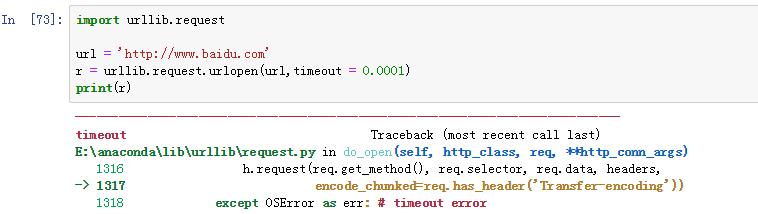
当出现超时脚本结果中不要出现这些错误信息,如何改进呢?我们导入socket包,用try语句捕捉异常数据进行处理;

三、python爬虫之requests库
requests 是python实现的简单易用的HTTP库,使用起来比urllib简洁很多;
1.requests常用函数:
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/head')
requests.options('http://httpbin.org/options')

其他方法同上
2.requests返回对象的属性和函数
response.content 返回二进制内容(比如音频)
response.text 返回文本内容
response.status_code 返回请求的状态码
response.headers 返回请求的头信息
response.cookies 获取cookie信息
response.json() 返回json编码信息

【学习笔记】第二章 python安全编程基础---python爬虫基础(urllib)的更多相关文章
- The Road to learn React书籍学习笔记(第二章)
The Road to learn React书籍学习笔记(第二章) 组件的内部状态 组件的内部状态也称为局部状态,允许保存.修改和删除在组件内部的属性,使用ES6类组件可以在构造函数中初始化组件的状 ...
- 《DOM Scripting》学习笔记-——第二章 js语法
<Dom Scripting>学习笔记 第二章 Javascript语法 本章内容: 1.语句. 2.变量和数组. 3.运算符. 4.条件语句和循环语句. 5.函数和对象. 语句(stat ...
- [HeadFrist-HTMLCSS学习笔记]第二章深入了解超文本:认识HTML中的“HT”
[HeadFrist-HTMLCSS学习笔记]第二章深入了解超文本:认识HTML中的"HT" 敲黑板!!! 创建HTML超链接 <a>链接文本(此处会有下划线,可以单击 ...
- c#高级编程第七版 学习笔记 第二章 核心c#
第二章 核心C# 本章内容: 声明变量 变量的初始化和作用域 C#的预定义数据类型 在c#程序中使用条件语句.循环和跳转语句执行流 枚举 名称空间 Main()方法 基本的命令行c#编译器选项 使用S ...
- [HeadFirst-JSPServlet学习笔记][第二章:高层概述]
第二章:高层体系结构 容器 1 什么是容器? servelet没有main()方法.它们受控于另一个Java应用,这个Java应用称为容器(Container) Tomcat就是这样一个容器.Web服 ...
- 《Python基础教程(第二版)》学习笔记 -> 第二章 列表和元组
本章将引入一个新的概念:数据结构. 数据结构是通过某种方式阻止在一起的数据元素的集合,这些数据元素可以是数字或者字符,设置可以是其他数据结构. Python中,最基本的数据结构是序列(Sequence ...
- 小甲鱼零基础汇编语言学习笔记第二章之寄存器(CPU工作原理,CPU内部通讯)
这一章主要介绍了CPU中的重要器件——寄存器,整个系列通篇是以8086CPU作为探讨对象,其它更高级的CPU都是在此基础之上进行的升级. 1.一个典型的CPU是由运算器.控制器.寄存器等器件组成, ...
- Python学习笔记 --第二章
Python语法基础 "#"号为注释符,建议缩进四个空格,Python大小写敏感. 数据类型 整数 0,2等等,以0x开头的为十六进制数 浮点数 1.58e9 字符串 用'或"括起来的任意文 ...
- JavaScript DOM编程艺术学习笔记-第二章JavaScript语法
一.JavaScript示例 <!DOCTYPE html> <html lang="en"> <head> <meta charset= ...
- Java 学习笔记 ------第二章 从JDK到IDE
本章学习目标: 了解与设定PATH 了解与指定CLASSPATH 了解与指定SOURCEPATH 使用package与import管理类别 初步认识JDK与IDE的对应关系 一.第一个Java程序 工 ...
随机推荐
- 【KakaJSON手册】02_JSON转Model_02_数据类型
由于JSON格式的能表达的数据类型是比较有限的,所以服务器返回的JSON数据有时无法自动转换成客户端想要的数据类型. 比如服务器返回的时间可能是个毫秒数1565480696,但客户端想要的是Date类 ...
- TP5使用API时不可预知的内部异常
最常见的错误形式例如 controller不存在或者 action不存在之类的 我们第一时间想到的 就是 使用 try{}catch(){} 来捕获 例如: /** * show方法在common里定 ...
- PCA(主成分分析)原理,步骤详解以及应用
主成分分析(PCA, Principal Component Analysis) 一个非监督的机器学习算法 主要用于数据的降维处理 通过降维,可以发现更便于人类理解的特征 其他应用:数据可视化,去噪等 ...
- json操作与使用 小白
json使用广可以和很多语言进行互换,把json序列化成字符串,可以反序列化回去 dumps(传入的类型,'ensure_ascii=False') loads网络传输 dump load文件写读 p ...
- Python 数据科学-Numpy
NumPy Numpy :提供了一个在Python中做科学计算的基础库,重在数值计算,主要用于多维数组(矩阵)处理的库.用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效的多.本身是由C语 ...
- 你是否真的了解全局解析锁(GIL)
关于我 一个有思想的程序猿,终身学习实践者,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. Github:https:/ ...
- php安装mongo扩展(linux)
1.首先下载php的mongodb扩展 从http://pecl.php.net/package/mongodb这个网址下载mongodb的扩展源码包 2.解压安装包 tar zxf mongodb- ...
- python学习之并发编程
目录 一.并发编程之多进程 1.multiprocessing模块介绍 2.Process类的介绍 3.Process类的使用 3.1 创建开启子进程的两种方式 3.2 获取进程pid 3.3验证进程 ...
- 一文搞懂transform: skew
如何理解斜切skew,先看一个demo.在下面的demo中,有4个正方形,分别是 红色:不做skew变换, 绿色:x方向变换, 蓝色:y方向变换, 黑色:两个方向都变换, 拖动下面的滑块可以查看改变s ...
- JS核心之DOM操作 下
目录: 1.节点类型之Document类型 2.节点类型之Element类型 3.节点类型之Text类型 4.综合小示例 -- 动态添加外部样式文件 5.查找元素的扩展方法 接上篇,我们先来看常用的三 ...