HBase导入数据同时与Phoenix实现同步映射
1.HDFS上数据准备
2019-03-24 09:21:57.347,869454021315519,8,1
2019-03-24 22:07:15.513,867789020387791,8,1
2019-03-24 21:43:34.81,357008082359524,8,1
2019-03-24 16:05:32.227,860201045831206,8,1
2019-03-24 18:11:18.167,866676040163198,8,1
2019-03-24 22:01:24.877,868897026713230,8,1
2019-03-24 12:34:23.377,863119033590062,8,1
2019-03-24 20:16:32.53,862505041870010,8,1
2019-03-24 09:10:55.18,864765037658468,8,1
2019-03-24 16:18:41.503,869609023903469,8,1
2019-03-24 10:44:52.027,869982033593376,8,1
2019-03-24 20:00:08.007,866798025149107,8,1
2019-03-24 10:25:18.1,863291034398181,2,3
2019-03-24 10:33:48.56,867557030361332,8,1
2019-03-24 16:42:15.057,869841022390535,8,1
2019-03-24 10:08:00.277,867574031105048,8,1
注意: 分隔符是‘,’
2. HBase上创建表
create 'ALLUSER','INFO';
3. 在Phoenix中建立相同的表名以实现与hbase表的映射
create table if not exists ALLUSER(
firsttime varchar primary key,
INFO.IMEI varchar,
INFO.COID varchar,
INFO.NCOID varchar
)
注意:
- 除主键外,Phoenix表的表名和字段字段名要和HBase表中相同,包括大小写
- Phoneix中的column必须以HBase的columnFamily开头
4. 通过importtsv.separator指定分隔符,否则默认的分隔符是tab键
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.columns=HBASE_ROW_KEY,INFO:IMEI,INFO:IMEI,INFO:NCOID \
-Dimporttsv.separator=, -Dimporttsv.bulk.output=/warehouse/temp/alluser ALLUSER /user/hive/warehouse/toutiaofeedback.db/newuser/000001_0
5. 将生成的HFlie导入到HBase
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /warehouse/temp/alluser ALLUSER
6. 查看HBase,Phoenix
查看HBase
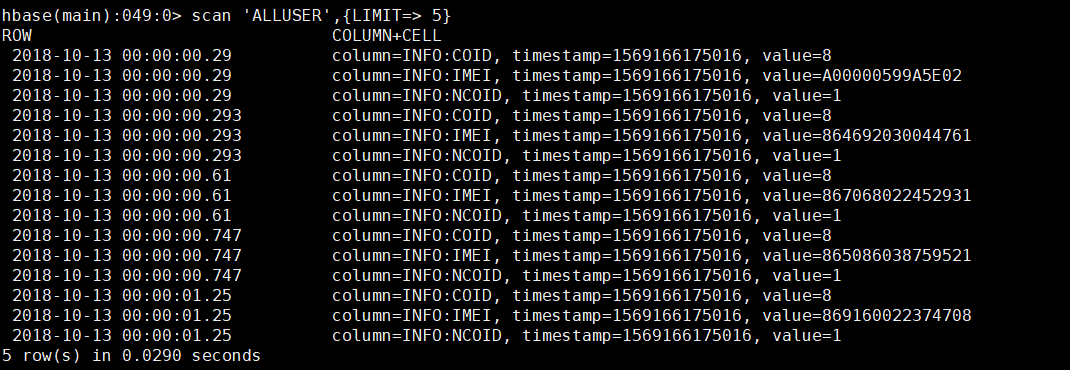
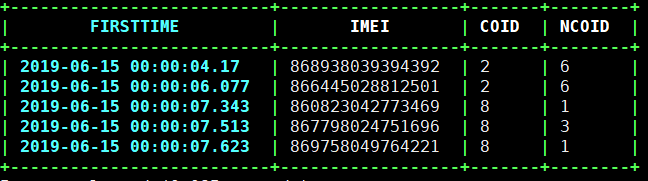
查看Phoenix
HBase导入数据同时与Phoenix实现同步映射的更多相关文章
- Phoneix(四)hbase导入数据同时与phoenix实现映射同步
一.说明 先创建一个hbase表格,能够导入本地数据到hbase中,最后能够通过phoneix进行访问. 1.数据准备(10W条,样例如下),文件test.txt 0,20190520164020,1 ...
- 使用sqoop工具从oracle导入数据
sqoop工具是hadoop下连接关系型数据库和Hadoop的桥梁,支持关系型数据库和hive.hdfs,hbase之间数据的相互导入,可以使用全表导入和增量导入 从RDBMS中抽取出的数据可以被Ma ...
- sqoop工具从oracle导入数据2
sqoop工具从oracle导入数据 sqoop工具是hadoop下连接关系型数据库和Hadoop的桥梁,支持关系型数据库和hive.hdfs,hbase之间数据的相互导入,可以使用全表导入和增量导入 ...
- 通过phoenix导入数据到hbase出错记录
解决方法1 错误如下 -- ::, [hconnection-0x7b9e01aa-shared--pool11069-t114734] WARN org.apache.hadoop.hbase.ip ...
- 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟
使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 Sqoop 大数据 Hive HBase ETL 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 基础环境 ...
- hbase批量数据导入报错:NotServingRegionException
批量导入数据到hbase的时候,报错: org.apache.hadoop.hbase.client.RetriesExhaustedWithDetailsException: Failed 1 ac ...
- HBase 实战(1)--HBase的数据导入方式
前言: 作为Hadoop生态系统中重要的一员, HBase作为分布式列式存储, 在线实时处理的特性, 备受瞩目, 将来能在很多应用场景, 取代传统关系型数据库的江湖地位. 本篇博文重点讲解HBase的 ...
- HBase(三): Azure HDInsigt HBase表数据导入本地HBase
目录: hdfs 命令操作本地 hbase Azure HDInsight HBase表数据导入本地 hbase hdfs命令操作本地hbase: 参见 HDP2.4安装(五):集群及组件安装 , ...
- sqoop:mysql和Hbase/Hive/Hdfs之间相互导入数据
1.安装sqoop 请参考http://www.cnblogs.com/Richardzhu/p/3322635.html 增加了SQOOP_HOME相关环境变量:source ~/.bashrc ...
随机推荐
- [HAOI2018]苹果树(组合数学,计数)
[HAOI2018]苹果树 cx巨巨给我的大火题. 感觉这题和上次考试gcz讲的那道有标号树的形态(不记顺序)计数问题很类似. 考虑如果对每个点对它算有贡献的其他点很麻烦,不知怎么下手.这个时候就想到 ...
- web 前端开发学习路线
初级 HTML 5 HTML 5 与 HTML 4 的区别 HTML 5 新增的主体结构元素 HTML 5 新增的非主体结构元素 HTML 5 表单新增元素与属性 HTML 5 表单新增元素与属性(续 ...
- C#高级语法之泛型、泛型约束,类型安全、逆变和协变(思想原理)
一.为什么使用泛型? 泛型其实就是一个不确定的类型,可以用在类和方法上,泛型在声明期间没有明确的定义类型,编译完成之后会生成一个占位符,只有在调用者调用时,传入指定的类型,才会用确切的类型将占位符替换 ...
- Web前端和Web后端的区分
版权声明:本文为CSDN博主「十豆三展」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明.原文链接:https://blog.csdn.net/zz1399590022 ...
- Python-demo(photo)
import osimport urllib import requests#import wximport time from fake_useragent import UserAgentfrom ...
- 开发APP必须知道的API集合,来源http://www.cnblogs.com/wikiki/p/7232388.html
笔记 OneNote - OneNote支持获取,复制,创建,更新,导入与导出笔记,支持为笔记添加多媒体内容,管理权限等.提供SDK和Demo. 为知笔记 - 为知笔记Windows客户端开放了大量的 ...
- js中尺寸类样式
js中尺寸类样式 一:鼠标尺寸类样式 都要事件对象的配合 Tip:注意与浏览器及元素尺寸分开,鼠标类尺寸样式都是X,Y,浏览器及元素的各项尺寸时Height,Width 1:检测相对于浏览器的位置:e ...
- TensorFlow Distribution(分布式中的数据读取和训练)
本文目的 在介绍estimator分布式的时候,官方文档由于版本更新导致与接口不一致.具体是:在estimator分布式当中,使用dataset作为数据输入,在1.12版本中,数据训练只是datase ...
- NLP(四) 正则表达式
* + ? * :0个或多个 + :1个或多个 ? :0个或1个 re.search()函数,将str和re匹配,匹配正确返回True import re # 匹配函数,输入:文本,匹配模式(即re) ...
- Atcoder C - Closed Rooms(思维+bfs)
题目链接:http://agc014.contest.atcoder.jp/tasks/agc014_c 题意:略. 题解:第一遍bfs找到所有可以走的点并标记步数,看一下最少几步到达所有没锁的点,然 ...