PHP经典面试题:如何保证缓存与数据库的双写一致性?
只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
面试题剖析
一般来说,如果允许缓存可以稍微的跟数据库偶尔有不一致的情况,也就是说如果你的系统不是严格要求 “缓存+数据库” 必须保持一致性的话,最好不要做这个方案,即:读请求和写请求串行化,串到一个内存队列里去。
串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低,用比正常情况下多几倍的机器去支撑线上请求。
Cache Aside Pattern
最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
更新的时候,先更新数据库,然后再删除缓存。
为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低,用到缓存才去算缓存。
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。像 mybatis,hibernate,都有懒加载思想。查询一个部门,部门带了一个员工的 list,没有必要说每次查询部门,都里面的 1000 个员工的数据也同时查出来啊。80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
最初级的缓存不一致问题及解决方案
问题:先修改数据库,再删除缓存。如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据就出现了不一致。
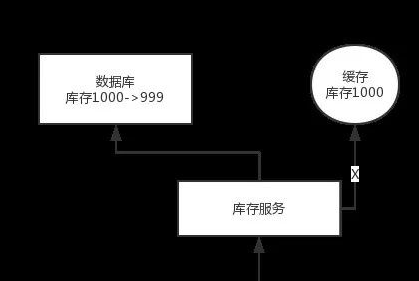
解决思路:先删除缓存,再修改数据库。如果数据库修改失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。因为读的时候缓存没有,则读数据库中旧数据,然后更新到缓存中。
比较复杂的数据不一致问题分析
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改。
完了,数据库和缓存中的数据不一样了。。。
为什么上亿流量高并发场景下,缓存会出现这个问题?
只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。其实如果说你的并发量很低的话,特别是读并发很低,每天访问量就 1 万次,那么很少的情况下,会出现刚才描述的那种不一致的场景。但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况。
解决方案如下:
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个 jvm 内部队列中。读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个 jvm 内部队列中。
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。这样的话,一个数据变更的操作,先删除缓存,然后再去更新数据库,但是还没完成更新。此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。
高并发的场景下,该解决方案要注意的问题:
1、读请求长时阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时时间范围内返回。
该解决方案,最大的风险点在于说,可能数据更新很频繁,导致队列中积压了大量更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库。务必通过一些模拟真实的测试,看看更新数据的频率是怎样的。
另外一点,因为一个队列中,可能会积压针对多个数据项的更新操作,因此需要根据自己的业务情况进行测试,可能需要部署多个服务,每个服务分摊一些数据的更新操作。如果一个内存队列里居然会挤压 100 个商品的库存修改操作,每隔库存修改操作要耗费 10ms 去完成,那么最后一个商品的读请求,可能等待 10 * 100 = 1000ms = 1s 后,才能得到数据,这个时候就导致读请求的长时阻塞。
一定要做根据实际业务系统的运行情况,去进行一些压力测试,和模拟线上环境,去看看最繁忙的时候,内存队列可能会挤压多少更新操作,可能会导致最后一个更新操作对应的读请求,会 hang 多少时间,如果读请求在 200ms 返回,如果你计算过后,哪怕是最繁忙的时候,积压 10 个更新操作,最多等待 200ms,那还可以的。
如果一个内存队列中可能积压的更新操作特别多,那么你就要加机器,让每个机器上部署的服务实例处理更少的数据,那么每个内存队列中积压的更新操作就会越少。
其实根据之前的项目经验,一般来说,数据的写频率是很低的,因此实际上正常来说,在队列中积压的更新操作应该是很少的。像这种针对读高并发、读缓存架构的项目,一般来说写请求是非常少的,每秒的 QPS 能到几百就不错了。
实际粗略测算一下
如果一秒有 500 的写操作,如果分成 5 个时间片,每 200ms 就 100 个写操作,放到 20 个内存队列中,每个内存队列,可能就积压 5 个写操作。每个写操作性能测试后,一般是在 20ms 左右就完成,那么针对每个内存队列的数据的读请求,也就最多 hang 一会儿,200ms 以内肯定能返回了。
经过刚才简单的测算,我们知道,单机支撑的写 QPS 在几百是没问题的,如果写 QPS 扩大了 10 倍,那么就扩容机器,扩容 10 倍的机器,每个机器 20 个队列。
2、读请求并发量过高
这里还必须做好压力测试,确保恰巧碰上上述情况的时候,还有一个风险,就是突然间大量读请求会在几十毫秒的延时 hang 在服务上,看服务能不能扛的住,需要多少机器才能扛住最大的极限情况的峰值。
但是因为并不是所有的数据都在同一时间更新,缓存也不会同一时间失效,所以每次可能也就是少数数据的缓存失效了,然后那些数据对应的读请求过来,并发量应该也不会特别大。
3、多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过 Nginx 服务器路由到相同的服务实例上。
比如说,对同一个商品的读写请求,全部路由到同一台机器上。可以自己去做服务间的按照某个请求参数的 hash 路由,也可以用 Nginx 的 hash 路由功能等等。
4、热点商品的路由问题,导致请求的倾斜
万一某个商品的读写请求特别高,全部打到相同的机器的相同的队列里面去了,可能会造成某台机器的压力过大。就是说,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以其实要根据业务系统去看,如果更新频率不是太高的话,这个问题的影响并不是特别大,但是的确可能某些机器的负载会高一些。
PHP经典面试题:如何保证缓存与数据库的双写一致性?的更多相关文章
- PHP中高级面试题 一个高频面试题:怎么保证缓存与数据库的双写一致性?
分布式缓存是现在很多分布式应用中必不可少的组件,但是用到了分布式缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题? Cache Aside ...
- Redis面试篇 -- 如何保证缓存与数据库的双写一致性?
如果不是严格要求“缓存和数据库”必须保证一致性的话,最好不要做这个方案:即 读请求和写请求串行化,串到一个内存队列里面去.串行化可以保证一定不会出现不一致的情况,但会导致系统吞吐量大幅度降低. 解决这 ...
- 第三节:Redis缓存雪崩、击穿、穿透、双写一致性、并发竞争、热点key重建优化、BigKey的优化 等解决方案
一. 缓存雪崩 1. 含义 同一时刻,大量的缓存同时过期失效. 2. 产生原因和后果 (1). 原因:由于开发人员经验不足或失误,大量热点缓存设置了统一的过期时间. (2). 产生后果:恰逢秒杀高峰, ...
- 【原创】分布式之数据库和缓存双写一致性方案解析(三) 前端面试送命题(二)-callback,promise,generator,async-await JS的进阶技巧 前端面试送命题(一)-JS三座大山 Nodejs的运行原理-科普篇 优化设计提高sql类数据库的性能 简单理解token机制
[原创]分布式之数据库和缓存双写一致性方案解析(三) 正文 博主本来觉得,<分布式之数据库和缓存双写一致性方案解析>,一文已经十分清晰.然而这一两天,有人在微信上私聊我,觉得应该要采用 ...
- Redis双写一致性与缓存更新策略
一.双写一致性 双写一致性,也就是说 Redis 和 mysql 数据同步 双写一致性数据同步的方案有: 1.先更新数据库,再更新缓存 这个方案一般不用: 因为当有两个请求AB先后更新数据库后,A应该 ...
- 并发中如何保证缓存DB双写一致性(JAVA栗子)
并发场景中大部分处理的是先更新DB,再(删缓.更新)缓存的处理方式,但是在实际场景中有可能DB更新成功了,但是缓存设置失败了,就造成了缓存与DB数据不一致的问题,下面就以实际情况说下怎么解决此类问题. ...
- Redis使用总结(二、缓存和数据库双写一致性问题)
首先,缓存由于其高并发和高性能的特性,已经在项目中被广泛使用.在读取缓存方面,大家没啥疑问,都是按照下图的流程来进行业务操作. 但是在更新缓存方面,对于更新完数据库,是更新缓存呢,还是删除缓存.又或者 ...
- K:缓存数据库双写数据一致性方案
对于缓存和数据库双写,其存在着数据一致性的问题.对于数据一致性要求较高的业务场景,我们通常会选择使用分布式事务(2pc.paxos等)来保证缓存与数据库之间的数据强一致性,但分布式事务的复杂性与对资源 ...
- 800+Java后端经典面试题,希望你找到自己理想的Offer呀~
前言 在茫茫的互联网海洋中寻寻觅觅,我收藏了800+道Java经典面试题,分享给你们.建议大家收藏起来,在茶余饭后拿出来读一读,以备未雨绸缪之需.另外,面试题答案的话,我打算后面慢慢完善在github ...
随机推荐
- Java性能优化的小细节
性能优化实现方式(单纯考虑代码层面): 1.减小代码体积 2.提高运行效率 如何做: 1.尽量指定类.方法的final修饰符 带有final修饰的类是不可派生的,该类所有的方法都是final的,jav ...
- PMP 项目管理第六版- 组织治理与项目治理之间的关系
组织治理: 1.组织治理通过制定政策和流程,用结构化方式指明工作方向并进行控制,以便实现战略和运营目标. 2,组织治理通常由董事会执行,以确保对相关方的最终责任得以落实,并保持公平和透明. 项目治理: ...
- 掌握git基本功
前言 最近想把代码传到GitHub上,结果我发现的demo的npm全是本地安装,上穿到GitHub要死要死,几百M,然后我就搜了下怎么不上传node_modules弄了半天也没成功,于是准备静下心学一 ...
- 【Dubbo】Zookeeper+Dubbo项目demo搭建
一.Dubbo的注解配置 在Dubbo 2.6.3及以上版本提供支持. 1.@Service(全路径@org.apache.dubbo.config.annotation.Service) 配置服务提 ...
- API设计中防重放攻击
HTTPS数据加密是否可以防止重放攻击? 否,加密可以有效防止明文数据被监听,但是却防止不了重放攻击. 防重放机制 我们在设计接口的时候,最怕一个接口被用户截取用于重放攻击.重放攻击是什么呢?就是把你 ...
- python编程系列---多个装饰器装饰一个函数的执行流程
首先看一个例子 ''' 多个装饰器装饰一个函数 ''' # 定义第一个装饰器 def set_func1(func): def wrapper1(*args,**kwargs): print('装饰内 ...
- Joomla3.4.6 RCE漏洞深度分析
笔者<Qftm>原文发布:https://www.freebuf.com/vuls/216512.html *严正声明:本文仅限于技术讨论与分享,严禁用于非法途径 0×00 背景 10月9 ...
- springboot security+redis+jwt+验证码 登录验证
概述 基于jwt的token认证方案 验证码 框架的搭建,可以自己根据网上搭建,或者看我博客springboot相关的博客,这边就不做介绍了.验证码生成可以利用Java第三方组件,引入 <dep ...
- gulp 自动化管理工具实现全过程
1.全局安装gulp npm install gulp -g 2.项目内安装gulp npm install gulp -s 3.项目根目录新建gulpfile.js js内代码: //载入gulp核 ...
- The usage of Markdown---标题
更新时间:2019.09.14 目录: 1. 序言 2. 标题 2.1 类Atx形式 2.2 类Setext形式 3. 总结 1. 序言 Markdown是一种纯文本的标记语言,只要熟悉M ...