Python爬虫的开始——requests库建立请求
接下来我将会用一段时间来更新python爬虫
网络爬虫大体可以分为三个步骤。
首先建立请求,爬取所需元素;
其次解析爬取信息,剔除无效数据;
最后将爬取信息进行保存;
今天就先来讲讲第一步,请求库requests
request库主要有七个常用函数,如下所示
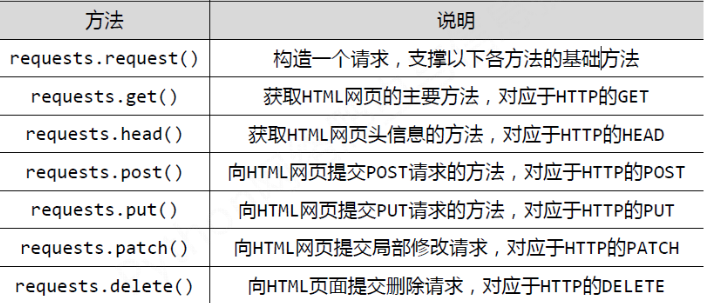
而通过requests创建的数据类型为response
我们以爬取百度网站为例
import requests as r
t=r.get("https://www.baidu.com/")
print(type(t))
运行结果如下所示
<class 'requests.models.Response'>
[Finished in 1.3s]
那么作为请求对象,具有哪些属性呢?
爬取数据第一步要做的事便是确认是否连接成功
status_code()从功能角度考虑,算的上是一种判断函数,调用将会返还结果是否成功
如果返回结果为200,则代表连接成功,如果返回结果为404,则代表连接失败
import requests as r
t=r.get("https://www.baidu.com/")
print(type(t))
print(t.status_code)
如图所示返回结果为200,连接成功

那么下一步便是获得网址代码,不过在获得代码之前,还需要做一件事,得到响应内容的编码方式
不同的编码方式将会影响爬取结果
比如说百度网址:https://www.baidu.com/
采用编码方式为ISO-8859-1
获取编码方式为encoding
如下所示
import requests as r
t=r.get("https://www.baidu.com/")
print(type(t))
print(t.status_code)
print(t.encoding)
结果:
<class 'requests.models.Response'>
200
ISO-8859-1
当然有的网页采用 utf8,也有使用gbk,
不同的编码方式会影响我们获得的源码
也可以通过手动更改来改变获得的编码方式
比如:
import requests as r
t=r.get("https://www.baidu.com/")
print(t.encoding)
t.encoding="utf-8"
print(t.encoding)
结果
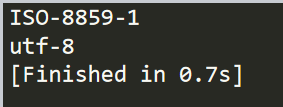
也可以试着备选码方式,apparent_encoding
之后我们就可以获得源代码了,我们需要将源代码以字符串类型输出保存
这就需要用到text
如下所示:
import requests as r
t=r.get("https://www.baidu.com/")
print(t.text)
结果:

这样我们就获得了对应网站的源码,完成了爬虫的第一步
Python爬虫的开始——requests库建立请求的更多相关文章
- python爬虫之一:requests库
目录 安装requtests requests库的连接异常 HTTP协议 HTTP协议对资源的操作 requests库的7个主要方法 request方法 get方法 网络爬虫引发的问题 robots协 ...
- PYTHON 爬虫笔记三:Requests库的基本使用
知识点一:Requests的详解及其基本使用方法 什么是requests库 Requests库是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库,相比u ...
- 芝麻HTTP: Python爬虫利器之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- 【python爬虫】用requests库模拟登陆人人网
说明:以前是selenium登陆取cookie的方法比较复杂,改用这个 """ 用requests库模拟登陆人人网 """ import r ...
- 网络爬虫入门:你的第一个爬虫项目(requests库)
0.采用requests库 虽然urllib库应用也很广泛,而且作为Python自带的库无需安装,但是大部分的现在python爬虫都应用requests库来处理复杂的http请求.requests库语 ...
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- python爬虫之re正则表达式库
python爬虫之re正则表达式库 正则表达式是用来简洁表达一组字符串的表达式. 编译:将符合正则表达式语法的字符串转换成正则表达式特征 操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单 ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
随机推荐
- java web项目下的lib和build path 中jar包问题解惑
一.build path&WEB-INFO/lib介绍 build path:可以说是引用: WEB-INFO/lib:可以说是固定在一个地方: eclipse编译项目的时候是根据build ...
- 玩转OneNET物联网平台之MQTT服务④ —— 远程控制LED(设备自注册)+ Android App控制
授人以鱼不如授人以渔,目的不是为了教会你具体项目开发,而是学会学习的能力.希望大家分享给你周边需要的朋友或者同学,说不定大神成长之路有博哥的奠基石... QQ技术互动交流群:ESP8266&3 ...
- Spring MVC(2)Spring MVC 组件开发
一.控制器接收各类请求参数 代码测试环境: 接收各类参数的控制器--ParamsController package com.ssm.chapter15.controller; @Controller ...
- 使用 Nginx 搭建静态资源 web 服务器
在搭建网站的时候,往往会加载很多的图片,如果都从 Tomcat 服务器来获取静态资源,这样会增加服务器的负载,使得服务器运行 速度非常慢,这时可以使用 Nginx 服务器来加载这些静态资源,这样就可以 ...
- SpringBoot与MybatisPlus整合之SQL分析插件(六)
pom.xml: <dependency> <groupId>p6spy</groupId> <artifactId>p6spy</artifac ...
- WordCloud安装
1,下载 https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud 2,安装 (window环境安装) 找的下载文件的路径 安装 1 pip inst ...
- Linux Capabilities 入门教程:基础实战篇
该系列文章总共分为三篇: Linux Capabilities 入门教程:概念篇 Linux Capabilities 入门教程:基础实战篇 待续... 上篇文章介绍了 Linux capabilit ...
- [翻译]——MySQL 8.0 Histograms
前言: 本文是对这篇博客MySQL 8.0 Histograms的翻译,翻译如有不当的地方,敬请谅解,请尊重原创和翻译劳动成果,转载的时候请注明出处.谢谢! 英文原文地址:https://lefred ...
- 中级前端必备知识点(2.5w+月薪)进阶 (分享知乎 : 平酱的填坑札记 关注专栏 用户:安大虎)
前端已经不再是5年前刚开始火爆时候的那种html+css+js+jquery的趋势了,现在需要你完全了解前端开发的同时,还要具备将上线.持续化.闭环.自动化.语义化.封装......等概念熟练运用到工 ...
- MIT线性代数:12.图和网络