一文解读ITIL (转)
首先声明自己不是ITIL方面的专家,特别是具体的规范细节,后面论述如有不当,请指正。但我为什么会提起它?主要是因为它和运维(IT服务管理)相关性太大了。早起的运维完全就是以ITIL来蓝本构建的,在当时公司中还有ITIL学习小组/实践活动、ITIL的外部顾问培训等等。后来在YY的时候,当时实践CMDB、事件管理的时候,也是参照了其具体的规范和要求。我建议大家在讲ITIL的时候,一定要把ITSMF授权荷兰人Jan Van Bon写的两本书都看一下,可以迅速扫盲,避免对ITIL的耍流氓式理解。
一、什么是ITIL
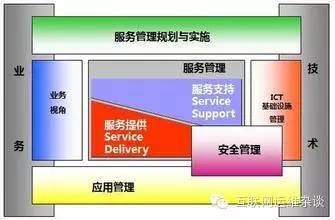
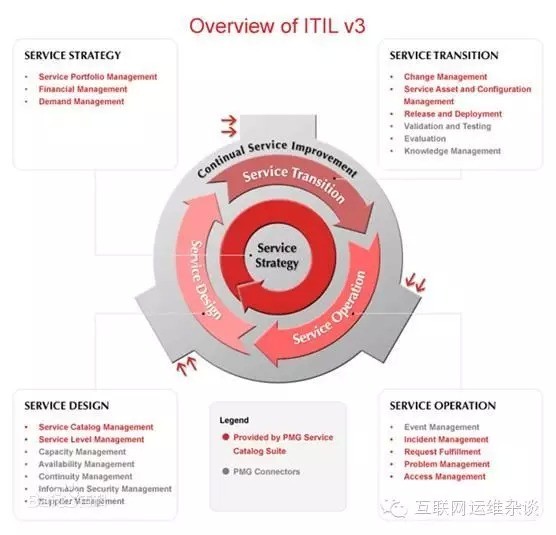
如何实现服务对接?在ITIL中,设计了一些相应的IT服务流程来保证。我们经常接触到的ITIL应该有两个版本,ITIL V2和ITIL V3。早期的V2版本中包含了一个服务台和10大核心流程,在后期ITIL V3版本中吸收了ITIL V2的精华,同时对IT服务提出“生命周期”的概念呢。在ITIL V3中就有了服务设计、服务转换和服务运营的周期性概念。在生命周期的不同阶段,有不同的服务职责和服务流程参照。具体如下:
简要了解之后,我们再来了解下和其他规范的关系。2001年,英国标准协会(BSI)以ITIL为核心发布了国家的标准BSI15000,随后2005年左右,国际标准化组织ISO以英国的标准化和ITIL为基础,又发布了一个IT服务管理规范ISO20000,确保IT服务管理的理念在全球推广。在ISO20000的IT服务管理规范中,同时吸收了ISO9000(质量管理规范)一些质量管理思想的要求。
COBIT是IT治理的框架和体系,我理解IT治理应该是一个全局的IT信息系统战略规划和指引,是一个统领性规范。如果企业完成其IT治理的目标,企业应该参照实施多个规范完善相应的治理,比如说IT服务质量标准化ISO20000、项目管理规范、安全管理规范、软件管理规范CMMI、安全管理规范、质量管理规范等等。
二、ITIL的价值
不得不说,IT服务管理是IT部门的福音。在此之前,IT部门可能都不知道自己要干什么,是不是我就负责做信息系统建设就可以了(以前电信的经历就是如此)。通过ITIL,IT服务部门找到自己部门的业务价值描述。但是单凭一己之力,貌似很难实施起来,都怪体系太庞大,因此市场上出现了一堆的IT服务管理(ITSM)产品,基于这些产品和概念,又出现了一堆的IT服务咨询公司和顾问,可以说目前ITIL的行业和生态还是不错的。
ITIL最大的价值是提供了一套最佳实践的标准和规范。的确对于很多企业来说,特别是一个大型的企业或者组织来说,都可以通过这套实践标准把方向和职责梳理清楚,比如说CMDB、容量管理、事件、连续性管理、成本管理。此时也改变了IT部门的传统定位,你除了写代码开发系统之外,你还有其他方面的工作要做。
既然ITIL是一套参照的最佳实践和描述,它也只是提出了一个业界通行的标准,因此在结合每个企业实际的过程中,由于每个企业的矛盾点和问题点必有不同,实践的路径和方法论也有不同。特别是传统企业,此时导入ITIL就需要相应的产品支持和咨询支持,而互联网则压根儿就没有完全照搬这套,貌似运行得也还行。
刚刚说互联网企业很少把ITIL体系搬过来,那是为什么呢?我理解是一种【外力】和【内力】的不同导致,这种内外力到底是什么?“外力”是指“面向用户”的程度不同。传统企业(银行、电信或者其他)很多服务的设计和交付还是基于自己的能力来设计的,而非真正的面向用户,因此产生的内部IT服务流也是一种缓慢的流。而互联网的产品从开始设计就考虑用户的参与,后期的用户需求的快速变化和用户价值及时响应产生的内部IT服务流必然是快速而敏捷的,流程性规范显然应对乏力,且服务内涵已经大发生了大大的变化。而“内力”可以转换成“结构决定功能”的描述,技术架构本身也决定了上层IT服务组织的设计,IT服务组织最终影响到IT服务能力的输出。在过去的一份金融工作经历中,采用的是SAN存储+刀片技术结构,这种技术架构带来的就是自身“甲方”化,其次会影响企业自身的IT能力,最后剩下的就是做各种ITIL流程来保证“SAN存储+刀片”高可靠运行。而互联网企业本身就是基于一个不可靠的基础设施来设计自己的IT技术架构和IT运维组织,由此产生的功能输出是不一样的。
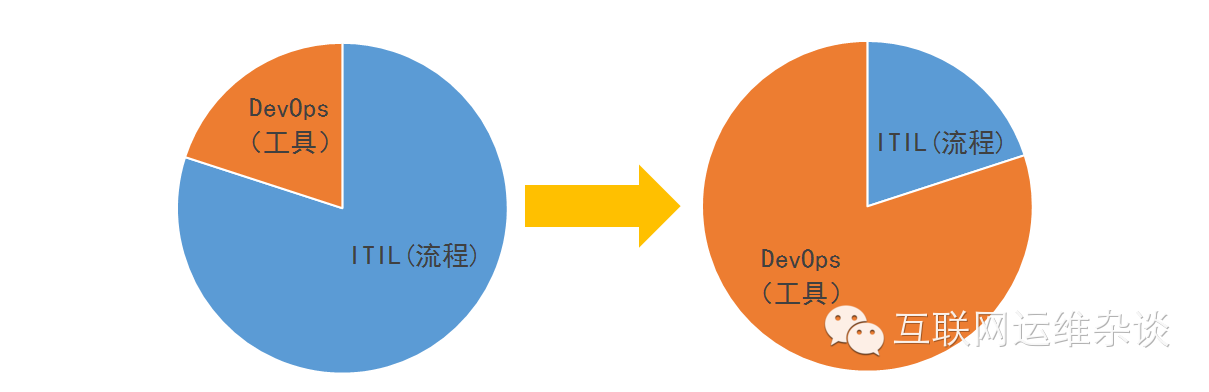
接下来我会重点阐述我在互联网企业中所经历的转变,这种转变是一种逐步“去ITIL”的过程,如下图:
三、运维的关注点转变
之前说了互联网企业为什么会逐步“去ITIL化”,粗略讲了内外的合力催生下的转变,接下来我具体谈谈这种转变的细节。
1、关注“流程”转变为关注“工具”
这是最基本的转变视角,我们一定要把流程藏匿在工具之后,这个工具可以继续上升成一个平台。流程是一种靠人来推动,而工具是靠计算机来推动的,两者在效率和一致性上面完全不同。基于工具自动化的要求,会反向对组织设计提出更敏捷的要求,所有阻碍事务优化的藩篱都需要消除掉,用DevOps最直接的一个价值观要求来说就是“杜绝浪费”,不是么?流程带来的是太多的浪费,为什么服务器申请需要发起流程,而不是“所见己即所得”,我们是资源提供者不就是最大化满足业务需求么?那无规则的使用如何约束呢,这个就是需要技术层面上要解决的,比如是IAAS云服务、弹性应用架构,甚至引入反向的成本机制来约束。如此一来便会不断促使在技术层面上全局的思考,而不会把很多问题交给流程。
再者对于x86大规模的互联网运维基础设施来说,一则流程根本就无济于事,流程是把人的能力过度放大;其次不引入“自动化”和“智能化”的工具,则最终会让运维成为能力瓶颈。个人一直是运维自动化的热衷者,自动化代表着运维的出路和未来,一个关注流程而忽视工具的运维才是真正感到危机的运维。
2、关注“规范”转变为关注“效率”
流程型规范带来的就是约束,约束本身是为了确保大家的行为不要偏离方向,看似是一种优势,实则不是。ITIL对变更管理的描述,书里面给了一个复杂的参考流程图,目的就是为了确保变更不出问题,可事实是这样么?我们依然还见到很多发布变更走了流程之后还在出问题。此时我们倒不如转换一个思路,既然引入这么多规则,只会让事情越来越复杂(人和接口多了),倒不如关注效率,如何让效率变得越来越高。基于效率之下,去检视IT团队之间如何更好的合作和发挥自身的能力优势?比如刚刚说的发布问题,效率之下,一定会考虑持续集成、持续的自动化测试、持续部署平台、立体化监控、技术架构优化等多种工具手段,而不是把问题抛给流程及流程之中的人。
3、关注“分工”转变为关注“合作”
ITIL是D/O分离的代名词,强调了彼此的分工,而非合作,D/O分离也是造成运维成就感不强的核心原因,在互联网企业中,必须杜绝。基于这种分离或者分工的模式,会造成组织间的彼此信息不透明,不透明之下就进一步失去对周边团队的未来方向性了解,彼此也就没法向对方提出更高的要求,变成一种简单的结果性要求。所以很多时候对方说我希望是什么样的,而不是考虑【我】还可以做什么,才能达到【我们】希望的样子,我把这种合作推向更本质化的要求上,叫“共享责任”,责任隔离只有【我】存在,责任共享才是【我们】。前几天有个腾讯的运维朋友告诉我,他们现在研发会主动把研发人力投入到和运维相关的研发工作中,我听了之后都有点小感动。
4、关注“服务”转变为关注“价值”
ITIL是把IT看成一个个的服务,运维是IT服务的最直接的提供者,可以说大部分流程服务都和运维相关。“服务”是看我能为你做什么,而“价值”则是看运维和研发一起用户能做什么。运维此时就需要把自己的服务者角色上升到价值者的角色,站在用户的角度去思考问题。“如何让用户使用我们产品更爽”(技术运营)+“如何让用户一直使用我们的产品”(产品运营)都会落到如何为用户提供价值的服务上来,技术运营寻找自己的技术价值点,产品运营是寻找自己的产品价值点。服务者角色,认为产品和功能交付,IT的工作则结束,而面向用户的互联网产品下的技术与产品运营则需要考虑迭代和闭环。
5、关注“业务”转变为关注“用户”
ITIL的整体框架上可以看到,ITIL解决的是IT部门和业务部门如何衔接的问题,面向的是业务需求。ITIL的很多流程都是为部门间的协作设计的,比如说事件流程、问题流程等等。非常重要的ITIL业务连续性管理,是和业务关系非常紧密的一个流程,在我所经历的互联网业务中,都没有为这个流程做过单独的设计,而是用户角度的产品必然性要求。当真正的故障产生的时候,一个敏捷响应的团队更加重要。对于一个时刻变化的IT架构来说,业务连续性管理很难跟上,最后这个问题就交给技术架构本身来解决,减少对人和文档的依赖。
站在“业务”角度和“用户”角度看IT服务也是完全不同的。“业务”角度是关注的这个业务功能交付过程怎么样?多少用户使用?等等。而站在用户的角度,运维还需要回答“用户”使用这个功能感觉怎么样?需要细化到一些技术指标上去更好的度量。
6、关注“事务”转变为关注“优化”
一个事务性团队在流程中能找到最好的归宿,见过有些运维团队把日常的事务要求作为考核要求,比如说某种服务要支持多少单,失败率多少等等。这种要求不能产生任何输出,只会让一些团队为了流程而流程,这也是一些团队不愿意放弃ITIL的原因。而优化型团队则更多的从用户的角度去寻找优化点,不断的去思考,除了流程,我们还能做什么?甚至去颠覆流程带给自己的束缚。
优化型团队是带着强烈的数据化运维思维的团队,其表现出来的驱动力会更强。在数据中能找到很多优化的方向,在一开始就要抱着“采集一切”和“分析一切”的诉求去对待数据。当早期我所在的腾讯部门把海量服务间的接口调用数据都收集起来,我对“采集一切”和“数据价值”就有了深刻的理解。基于这份数据可以去做真实的业务告警、故障定位,可以做服务容量预测,甚至是自动化变更等等。
7、关注“推动”转变为关注“拉动”
推动和拉动是两种不同的做事方式,带来的组织行为也差别很大。“推动”是静态的,被动改变的,而“拉动”是动态的,自适应的。ITIL的流程观反复天生造就了其中的部门或者人在流程中的分工和责任制衡似的,带来的优化力实在很小。当流程形成之后,团队容易进入惯性,接受一种自然状态,不愿意做出改变,改变就意味着承担更多的责任,而“拉动”是自适应的,用户驱动的,工具驱动的。你能看到很多互联网运维团队都处于一个自我演变的状态,时刻让自己的状态变得更好。
四、几个实例
1、故障报告
大家可以仔细留意一下自己的故障报告,看看解决措施是怎么写的,能看到运维个人或者团队的一些思维和理念。针对故障,很多报告中写到让运维人如何更快的发现故障,如何更快的处理故障甚至如何更快的解决故障等等,然后还写一些流程保证的措施。殊不知人就是最不可靠的哈,因此通常一个线上故障产生的时候,事后的故障回顾首先需要想到的是技术解决方案是什么?而不是靠运维人。
前几天线上服务出现一个故障,进程Tl状态,监控已经探测到服务异常,而这个时候运维的一个忽略,问题持续了一个晚上(告警太多,狼来了的故事上演了)。而这个问题处理特别简单,dump出进程状态信息以及服务重启一下就解决了。最后我们给出故障的解决措施:1)本地服务增加一个通用守护的功能,探测服务异常后,直接服务异常干预;2)其次把带来服务组件更换成另外一个,使之具备对服务的七层检测能力,便于更好的服务容错。以上解决措施就大大减少对人的要求,其实我们都知道,谁会愿意大半夜的起来处理个小故障呢。人是做不到7*24的,如果运维变成7*8,是不是觉得自己不苦逼了?
2、应用变更流程
这是腾讯早期部门的发布流程图(有点和ITIL变更流程类似),我记得当时还有一个流程系统,里面有以下很多角色,很多角色和这个发布事务都没有关联关系的,在流程只是点击一个按钮而已。
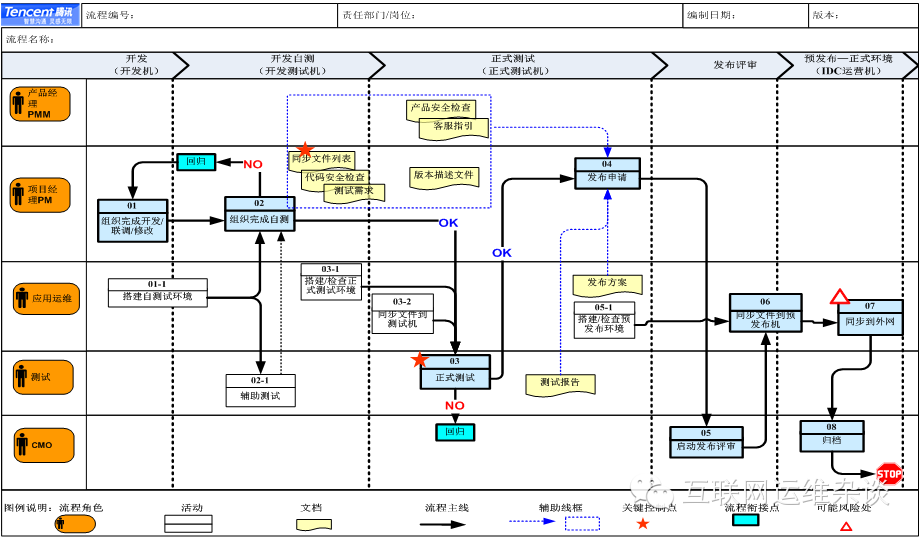
当后续的发布平台建设起来之后,这个流程就没用了。所有的发布都在线上完成,并且运维已经从发布流程中彻底退出。再往后,为了解决发布后的服务检查而不依赖运维,实时的发出发布变更报告,供研发、测试和运维查看发布状态,把发布过程闭环起来。
3、设备维修流程
早期的设备维修流程都是机器负责人(应用运维)发起流程,然后提交服务台,服务台统一派单给设备管理员处理,而云端IAAS服务的出现,则颠覆了这一模式。但服务器出现故障的时候(和应用运维无关),直接把服务器放到故障池中,不需及时维修,因为云平台对硬件的故障的容忍度更高,此时维修人员根据系统设定的派单规则对设备进行批量的维修或者更换,大大减少成本。可以说云技术的出现,无状态技术架构大大降低对人的依赖和对设定流程的依赖。
五、总结
“去ITIL化”更多的是去ITIL流程化和对其的照搬,其实ITIL中的很多服务思想依然值得借鉴和学习,比如说CMDB、能力管理,但最怕是被ITIL框住。不结合自己的实际直接导入一些ITIL流程,如成本管理、业务连续性管理等等,费力不讨好,而更多需要结合实际考虑建设那些为用户带来价值的服务和平台建设。我们一定要“去ITIL”带来的静态流程观,我们需要DevOps动态工具观去提升运维能力。
综上所述,我的观点是把ITIL的部分服务思想和DevOps结合起来,而运维是“去ITIL”的首要角色,如此才能构建真正的面向用户的IT服务能力(不限于ITIL)。其实不是它或者我变了,而是我们服务的用户变了。
一文解读ITIL (转)的更多相关文章
- 一文解读AI芯片之间的战争 (转)
2015年的秋天,北京的雨水比往年要多些,温度却不算太冷.这一年里,年仅23岁的姚颂刚刚拿到清华大学的毕业证书;32岁的陈天石博士毕业后已在中科院计算所待了整整8年;而在芯片界摸爬滚打了14年的老将何 ...
- Programming好文解读系列(—)——代码整洁之道
注:初入职场,作为一个程序员,要融入项目组的编程风格,渐渐地觉得系统地研究下如何写出整洁而高效的代码还是很有必要的.与在学校时写代码的情况不同,实现某个功能是不难的,需要下功夫的地方在于如何做一些防御 ...
- 一文解读RESTful (转)
01 前言 回归正题,看过很多RESTful相关的文章总结,参齐不齐,结合工作中的使用,非常有必要归纳一下关于RESTful架构方式了,RESTful只是一种架构方式的约束,给出一种约定的标准,完全严 ...
- 一文解读Redis (转)
本文由葡萄城技术团队编撰并首发 转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 引言 在Web应用发展的初期,那时关系型数据库受到了较为广泛的关注和应用,原 ...
- 一文解读MPA/SPA(转)
应用模式 模式示意图 多页面应用 每一次页面跳转的时候,后台服务器都会返回一个新的html文档,这种类型的网站也就是多页网站,也叫多页应用. 页面跳转: 返回HTML优点: 首屏时间快,SEO效果好缺 ...
- 一文解读HTTP2 (转)
作为一个经常和web打交道的程序员,了解这些协议是必须的,本文就向大家介绍一下这些协议的区别和基本概念,文中可能不局限于前端知识,还包括一些运维,协议方面的知识,希望能给读者带来一些收获,如有不对之处 ...
- 一文解读HTTP (转)
先扒一扒HTTP协议背景? HTTP(HyperText Transfer Protocol) 即超文本传输协议,现在基本上所有web项目都遵从HTTP协议(协议就是一种人为的规范). 目前绝大部分使 ...
- 一文解读MVC/MVP/MVVM (转)
这篇文章对目前 GUI 应用中的 MVC.MVP 和 MVVM 架构模式进行详细地介绍. MVC 在整个 GUI 编程领域,MVC 已经拥有将近 50 年的历史了.早在几十年前,Smalltalk-7 ...
- 一文解读CQRS (转)
先从CQRS说起,CQRS的全称是Command Query Responsibility Segregation,翻译成中文叫作命令查询职责分离.从字面上就能看出,这个模式要求开发者按照方法的职责是 ...
随机推荐
- javaWeb核心技术第十一篇之Listener
监听器:所谓的监听器是指对整个WEB环境的监听,当被监视的对象发生改变时,立即调用相应的方法进行处理. 监听术语: 事件源:被监听的对象. 监听器对象:监听事件源的对象 注册或绑定:1和2结合的过程 ...
- Add a Parametrized Action 添加带参数的按钮
In this lesson, you will learn how to add a Parametrized Action. These types of Actions are slightly ...
- 机器学习pipeline总结
# -*- coding: utf-8 -*- """scikit-learn introduction Automatically generated by Colab ...
- cmdb项目-2
1.命令插件异常处理 + 日志采集 1)为了更清楚发送客户端收集信息的状态 ,优化返回api的数据 ,变为字典存储 {状态 错误信息 数据} ,因为每个插件的每种系统下都要这个返回值我们将他单独做成类 ...
- LayUi 树形组件tree 实现懒加载模式,展开父节点时异步加载子节点数据
LayUi框架中树形组件tree官方还在持续完善中,目前最新版本为v2.5.5 官方树形组件目前还不支持懒加载方式,之前我修改一版是通过reload重载实例方法填充子节点数据方式,因为递归页面元素时存 ...
- 解决element-ui的表格设置固定栏后,边框线消失的bug
如上图所示,边框线消失了,解决方法如下 添加css代码,如果是修改全局,则到全局样式文件添加 .el-table__row{ td:not(.is-hidden):last-child{ right: ...
- Bazel 编译工具; tensorflow 编译
什么是bazel https://docs.bazel.build/versions/master/bazel-overview.html 使用 bazel 构建 c++ 工程 https://git ...
- Python迭代器的用法,next()方法的调用
迭代器的用法: 首先说两个概念,一个是可迭代的对象,一个是迭代器对象,两个不同 可迭代的(Iterable):就是可以for循环取数据的,比如字典.列表.元组.字符串等,不可使用next()方法. 迭 ...
- optix之纹理使用
1.在OpenGL中生成纹理texture optix中的纹理直接使用OpenGL纹理的id,不能跨越OpenGL纹理,所以我们先在OpenGL环境下生成一张纹理. 这个过程就很熟悉了: void W ...
- Leetcode 216. 组合总和 III
地址 https://leetcode-cn.com/problems/combination-sum-iii/ 找出所有相加之和为 n 的 k 个数的组合.组合中只允许含有 1 - 9 的正整数,并 ...