乘积量化(Product Quantization)
乘积量化
1。简介
乘积量化(PQ)算法是和VLAD算法是由法国INRIA实验室一同提出来的,为的是加快图像的检索速度,所以它是一种检索算法,在矢量量化(Vector Quantization,VQ)的基础上发展而来,虽然PQ不算是新算法,但是这种思想还是挺有用处的,本文没有添加公式。
它原文中是接在VLAD算法后面,假设我们使用VLAD算法获得了1M的图像表达向量,向量的维度为D=128,则对于一幅查询图像来说,我们需要计算1M个余弦距离,这样实时性就比较差。所以如何加快这种距离的计算速度就是PQ算法所要完成的任务。当然为了解决这个问题,已经有很多算法被提出了,如KDTree,LSH,ITQ等都是为解决这个问题而提出的,属于KNN或ANN范畴。
2。空间切分
首先,PQ先将D维空间切分成M份:即将128维空间切分成M个D/M维的子空间,如下图所示M=8(在原文中,作者由于是在PCA之后进行的PQ检索,所以进行了一个随机旋转,因为PCA之后特征值的顺序是按照从大到小排列的)
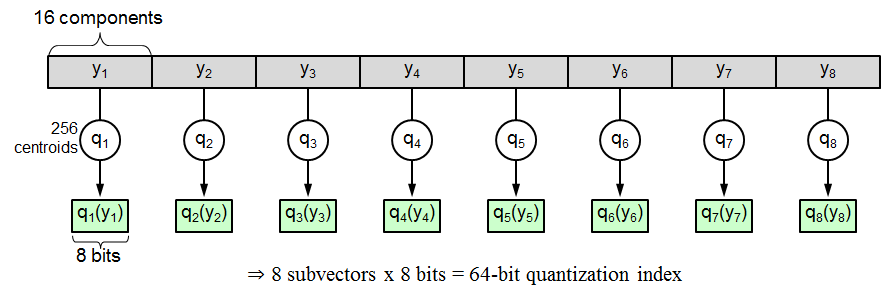
用代码表示就是把向量维度切分:
- int ds= d / nsq;
- for ( int i = ; i < nsq; i ++ )
- {
- for ( int j = ; j < ds; j ++ )
- {
- vs.push_back( vtrain.row( i*ds + j ) );
- }
- }
- //vtrain的转置是原始128维向量,vs是其中的一个子向量
3。量化
这样就可以在每个子空间内都会有1M个短向量,我们为每个子空间单独训练一本码书,图中码书规模为k=256,维度d=D/M=128/8=16,代码只要在上面的外循环中添加k-means聚类即可:
- kmeans( vs, ks, labelssub, TermCriteria( CV_TERMCRIT_EPS+CV_TERMCRIT_ITER, , 0.001 ),
- , KMEANS_PP_CENTERS, centers );
到这里我们就有M=8本子码书,下面我们依次量化每个子空间的数据,量化的过程就是计算每个短向量距离最近的聚类中心,距离就是L2距离,可以调用OpenCV函数,也可以自己写一个距离计算函数,但是要统一,如:
- float my_norm_L2( Mat mat1, Mat mat2 )
- {
- int d = mat1.cols;
- float sum_d = 0.0;
- for ( int i = ; i < d; i ++ )
- {
- float pp = mat1.at<float>( , i ) - mat2.at<float>( , i );
- sum_d = sum_d + pp*pp;
- }
- return sum_d;
- }
4。压缩
现在考虑一个D=128维的原始向量,它被切分成了M=8个d=16维的短向量,同时每个短向量都对应一个量化的索引值,索引值即该短向量距离最近的聚类中心的编号,每一个原始向量就可以压缩成M个索引值构成的压缩向量,只要设计好了数据结构,就可以获得所有1M数据的压缩向量。压缩向量其实就是M个索引值,每个索引值对应一个聚类中心,所以要同时保存压缩向量和聚类中心。
其实一个向量被8个索引值同时索引,而如果把这8个索引值转换成一个的话是多大呢,k的M次方,这里应该是256的8次方,这是一个很大很大的数,而上面的操作就等效于生成了一个这么大规模的码书。为什么这么说呢,因为每一个短向量(或称子向量)量化的过程都有k个选择,而一个原始向量有M个选择,类似于8位256进制的数可以表示的最大数值:

对于query图像的原始向量也经过上述流程的切分和量化过程,最后生成同样的M维压缩向量。
5。距离计算
对于训练数据和测试数据都压缩完成后,接下来就是讨论如何计算两个压缩向量之间的距离呢?而且是快速的计算。
作者提供了两种距离计算方式,分别为 “对称距离计算” 和 “非对称距离计算” ,分别如下左右图所示:
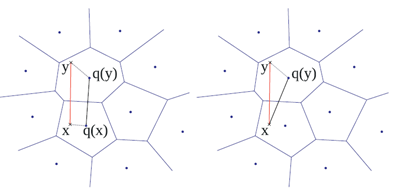
对称距离计算:直接使用两个压缩向量x,y的索引值所对应的码字q(x),q(y)之间的距离代替之,而q(x),q(y)之间的距离可以离线计算,因此可以把q(x),q(y)之间的距离制作成查找表,只要按照压缩向量的索引值进行对应的查找就可以了,所以速度非常快;
非对称距离计算:使用x,q(y)之间的距离代替x,y之间的距离,其中x是测试向量。虽然y的个数可能有上百万个,但是q(y)的个数只有k个,对于每个x,我们只需要在输入x之后先计算一遍x和k个q(y)的距离,制成查找表(因为只有k个,所以速度是非常快的),然后按照y对应的压缩向量索引值进行取值操作就可以了。
- Mat sumidxtab( Mat &D, Mat&x, Mat & dis )
- {
- dis = Mat::zeros( , x.rows, CV_32FC1 );
- for ( int i = ; i < x.rows; i ++ )
- {
- float distmp = ;
- for ( int j = ; j < D.cols; j ++ )
- {
- distmp = distmp + D.at<float>( x.at<int>( i, j ), j ) ;//ADC距离计算方式;
- }
- dis.at<float>( , i ) = distmp;
- }
- return dis;
- }
//D为查找表,x为压缩向量,dis为最终的距离
6。总结
不管哪种计算方法都可以实现快速的距离计算,但是非对称距离计算由于只量化了y,所以计算的距离精度更高,效果也更好。距离计算过程中只需要存储码书和对应的索引值就可以完全抛弃原始的图像表达向量,实现数据的压缩和距离的快速计算。
但是需要明白的是,这种算法是基于量化的,所以必然存在量化误差,所以距离的计算并不是完全准确的。通常通过这种算法迅速返回N个结果,然后再在N个结果中进行进一步的匹配计算,得到比较准确的结果。
在原文中,还有基于PQ的非线性计算方法IVFADC,它的速度更快,精度反而更高了,有时间再介绍。其实后续人们不断改进了PQ算法,如OPQ,Multi-ADC,DPQ,AQ/APQ,TQ,LOPQ等等,其中OPQ,Multi-ADC的提升效果还是比较明显的。
乘积量化(Product Quantization)的更多相关文章
- ANN中乘积量化与多维倒排小结
目前特征向量的比对加速优化能极大缩短比对耗时,改善用户体验. 优化的途径主要有两种,一是使用指令集(SSE,AVX)加速运算.二是使用ANN替代暴力搜索. 乘积量化和倒排索引组合是ANN中效果较好且实 ...
- 暴力求解——最大乘积 Maximum Product,UVa 11059
最大乘积 Maximum Product 题目链接:http://acm.hust.edu.cn/vjudge/contest/view.action?cid=84562#problem/B 解题思路 ...
- 最大乘积 Maximun Product
最大乘积 题目链接:http://acm.hust.edu.cn/vjudge/contest/view.action?cid=84562#problem/B 题意: 输入n个元素组成的序列s,你需要 ...
- [Swift]LeetCode628. 三个数的最大乘积 | Maximum Product of Three Numbers
Given an integer array, find three numbers whose product is maximum and output the maximum product. ...
- 最大乘积(Maximum Product,UVA 11059)
Problem D - Maximum Product Time Limit: 1 second Given a sequence of integers S = {S1, S2, ..., Sn}, ...
- LeetCode 238. 除自身以外数组的乘积( Product of Array Except Self)
题目描述 给定长度为 n 的整数数组 nums,其中 n > 1,返回输出数组 output ,其中 output[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积. 示例: 输 ...
- 【LeetCode】1464. 数组中两元素的最大乘积 Maximum Product of Two Elements in an Array (Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 暴力 找最大次大 日期 题目地址:https://le ...
- [Swift]LeetCode318. 最大单词长度乘积 | Maximum Product of Word Lengths
Given a string array words, find the maximum value of length(word[i]) * length(word[j]) where the tw ...
- FastText 分析与实践
一. 前言 自然语言处理(NLP)是机器学习,人工智能中的一个重要领域.文本表达是 NLP中的基础技术,文本分类则是 NLP 的重要应用.在 2016 年, Facebook Research 开源了 ...
随机推荐
- JavaScript for 、for...of 、for...in 等 iteration 效率测试
由于不同浏览器,不同版本性能不一,且控制台本质是是套用了一大堆eval,沙盒化程度高,所以需使用node环境测试来提高准确性 // 准备待测数组 const NUM = 1e7; let arr = ...
- SpringBoot项目里,让TKmybatis支持可以手写sql的Mapper.xml文件
SpringBoot项目通常配合TKMybatis或MyBatis-Plus来做数据的持久化. 对于单表的增删改查,TKMybatis优雅简洁,无需像传统mybatis那样在mapper.xml文件里 ...
- rocksdb学习笔记
rocksdb是在leveldb的基础上优化而得,解决了leveldb的一些问题. 主要的优化点 1.增加了column family,这样有利于多个不相关的数据集存储在同一个db中,因为不同colu ...
- diango运行流程
diango运行流程 Django处理一个请求的流程: 在浏览器的地址栏中输入地址,回车,发了一个GET请求 wsgi模块接收了请求,将请求的相关信息封装成request对象 根据地址找到对应函数 执 ...
- openstack Glance安装与配置
一.实验目的: 1.理解glance镜像服务在OpenStack框架中的作用 2.掌握glance服务安装的基本方法 3.掌握glance的配置基本方法 二.实验步骤: 1.在controller节点 ...
- fiddler抓包的一些基本知识整理
fiddler常用命令:selelct xx: 高亮显示所有的text,js,image等响应类型?xxx:匹配所有url.protocol.host中包含xxx的会话=404:选择响应状态码为404 ...
- Vue.js学习笔记--菜鸟搭建一个企业级vue的项目
vue.js新手搭建一个企业项目,从0开始 前置条件: node.npm请先安装配置好 下面开始: npm 下载vue-cli脚手架工具 确认安装成功看到版本号: 初始化项目,选用webpack(p ...
- Java连接数据库 #07# MyBatis Generator简单例子
MyBatis Generator是一个可以帮助我们免去手写实体类&接口类以及XML的代码自动生成工具. 下面,通过一个简单的例子介绍MyBatis Generator如何使用. 大体流程如下 ...
- .NET Application,Session,Cookie,ViewState,Cache对象用法
作用域 保存地址 生命周期Application 应用程序 服务器内存 IIS启动Session 整个站点 服务器内存 Session到时 默认20分钟Cashe 应用程序 服务器内存 应用程序的周期 ...
- ubuntu18.04 安装 搜狗输入法
一.安装fcitx sudo apt-get install fcitx-bin 因为搜狗拼音依赖fcitx,相关的依赖库和框架都会自动安装上. sudo apt-get install fcitx- ...