Attention 和self-attention
1.Attention
最先出自于Bengio团队一篇论文:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE ,论文在2015年发表在ICLR。
encoder-decoder模型通常的做法是将一个输入的句子编码成一个固定大小的state,然后将这样的一个state输入到decoder中的每一个时刻,这种做法对处理长句子会很不利,尤其是随着句子长度的增加,效果急速下滑。
论文动机:是针对encoder-decoder长句子翻译效果不好的问题。
解决原理:仿造人脑结构,对一张图片或是一个句子,能够重点关注到不同部分。
论文解决思路:在生成当前词的时候,只要把上一个state与所有的input word作为融合,而后做一个权重计算。通过这种方式生成的词就会有针对性,在句子长度较长时效果尤其明显。
整体框架如下图:

2.Self-attention
出自于Google团队的论文:Attention Is All You Need ,2017年发表在NIPS。
论文动机:RNN本身的结构,阻碍了并行化;同时RNN对长距离依赖问题,效果会很差。
解决思路:通过不同词向量之间矩阵相乘,得到一个词与词之间的相似度,进而无距离限制。
整体结构:

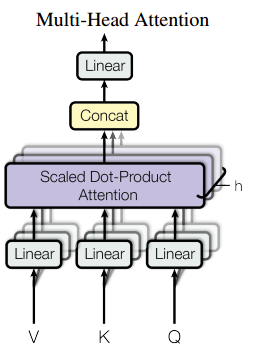
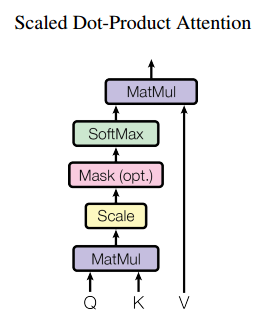
multi-head attention:
将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
self-attention:
每个词位的词都可以无视方向和距离,有机会直接和句子中的每个词encoding。比如下图这个句子,每个单词和同句其他单词之间都有一条边作为联系,边的颜色越深表明联系越强,而一般意义模糊的词语所连的边都比较深。比如:law,application,missing,opinion。

Attention 和self-attention的更多相关文章
- 注意力机制---Attention、local Attention、self Attention、Hierarchical attention
一.编码-解码架构 目的:解决语音识别.机器翻译.知识问答等输出输入序列长度不相等的任务. C是输入的一个表达(representation),包含了输入序列的有效信息. 它可能是一个向量,也可能是一 ...
- 可视化展示attention(seq2seq with attention in tensorflow)
目前实现了基于tensorflow的支持的带attention的seq2seq.基于tf 1.0官网contrib路径下seq2seq 由于后续版本不再支持attention,迁移到melt并做了进一 ...
- (转)注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 本文转自:http://www.cnblogs.com/robert-dlut/p/5952032.html 近年来,深度 ...
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了 ...
- Attention and Augmented Recurrent Neural Networks
Attention and Augmented Recurrent Neural Networks CHRIS OLAHGoogle Brain SHAN CARTERGoogle Brain Sep ...
- (转)Attention
本文转自:http://www.cosmosshadow.com/ml/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/2016/03/08/Attention.ht ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(二)引入attention机制
在上一篇博客中介绍的论文"Show and tell"所提出的NIC模型采用的是最"简单"的encoder-decoder框架,模型上没有什么新花样,使用CNN ...
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- Attention Model(注意力模型)思想初探
1. Attention model简介 0x1:AM是什么 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但 ...
- 【NLP】Attention Model(注意力模型)学习总结
最近一直在研究深度语义匹配算法,搭建了个模型,跑起来效果并不是很理想,在分析原因的过程中,发现注意力模型在解决这个问题上还是很有帮助的,所以花了两天研究了一下. 此文大部分参考深度学习中的注意力机制( ...
随机推荐
- 3- 设置断点修改Response
以下是借鉴别人的知识分享.我在这里转载,如有冒犯,还请告知. 只要你会设置断点修改请求内容的话,这个设置断点修改响应内容的方法也是一样的,只需要修改一下命令即可. 修改响应内容也有两种方法: 第一种: ...
- [vue]初探vue生态核心插件Vuex
为什么会有 Vuex 这个东西 ? 一个应用内部运行的机制,事件 -> 状态 -> UI,我们的前端常常会因为这两个过程而产生大量代码,从而变得难以维护. vue的声明式渲染,解决了从 状 ...
- 文件(图片)转base64
普通图片转base64 function getBase64(url, callback){ var canvas = document.createElement('canvas'),//创建can ...
- wxxcx_learn订单
自动写入时间戳 protected $autoWriteTimestamp = true: 事务的使用 Db::startTrans();....... Db::commit();.. Db::rol ...
- 【spring boot】配置信息
======================================================================== 1.feign 超时配置 2.上传文件大小控制 3.J ...
- liunx新装tomcat之后,tomcat不能识别新发布的项目
遇到的问题 在liunx新装tomcat之后,发布之前的项目,发现在tomcat不能识别新发布的项目,打成war包,还是直接把项目拷贝过去都不行. 环境:虚拟机:VMware 主机系统:win10 虚 ...
- 面试完腾讯,总结了这12道Zookeeper面试题!
前言 ZooKeeper 是一个开源的分布式协调服务,可以基于 ZooKeeper 实现诸如:数据发布/订阅.负载均衡.命名服务.分布式协调/通知.集群管理.Master 选举.配置维护,名字服务.分 ...
- 使用Portainer集中管理多地域内网运行的Docker实例
1. 单机运行的Docker 容器化部署是现在进行时,开源应用大多数支持容器化部署 在少量机器的场景下往往采用docker cli 和 docker-compose管理,进行"单机式管理&q ...
- django基础之day04,聚合查询和分组查询
聚合查询: 聚合函数必须用在分组之后,没有分组其实默认整体就是一组 Max Min Sum Avg Count 1.分组的关键字是:aggretate 2.导入模块 from django.db.mo ...
- 咪咕音乐链接歌词封面搜索等接口API
搜索 pd.musicapp.migu.cn/MIGUM2.0/v1.0/content/search_all.do?&ua=Android_migu&version=5.0.1&am ...