torch_09_GAN
1.生成对抗网络
让两个网络相互竞争,通过生成网络来生成假的数据,对抗网络通过判别器判别真伪,最后希望生成网络生成的数据能够以假乱真骗过判别器
2.生成模型
就是‘生成’样本和‘真实’的样本尽可能的相似。生成模型的两个主要功能是学习一个概率分布Pmodel(X)和生成数据。
在生成对抗网络中,不再是将图片输入编码器得到隐含向量然后生成图片,而是随机初始化一个隐含向量,根据变分自动编码器的特点,初始化一个正态分布的隐含向量,通过类似解码的过程,将它映射到一个更高的维度,最后生成一个与输入数据相似的数据,这就是假的数据。生成对抗网络过程通过计算对抗过程来计算损失函数。
2.1 自动编码器(AutoEncoder)
编码器的结构:
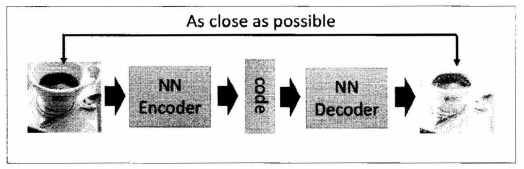
第一部分是编码器(Encoder),第二部分是解码器(Decoder),编码器和解码器都可以是任意的模型,通常使用神经网络模型作为编码器和解码器。输入的数据经过神经网络降维到一个编码(code),接着又通过另外一个神经网络去解码得到一个与输入数据一模一样的生成数据,然后通过比较这两个数据,最小化™之间的差异来训练这个网络中编码器和解码器的参数。当这个过程训练完之后,拿出这个解码器,随机传入一个编码,通过解码器能够生成一个和原数据差不多的数据。如下图:
2.2 变分自动编码器(Variational AutoEncoder-- VAE)
结构与自动编码器是相似的,也是由编码器和解码器构成的。
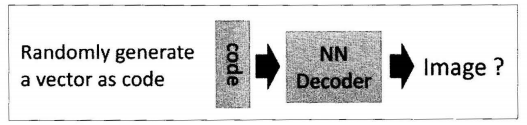
在自动编码器中只能输入一张图片,才能产生隐含向量,不能输入一个随机向量,虽然自动编码器能输出与原图很接近的图片,但是缺乏多样性。在变分自动编码器中,只需要在编码过程给它增加一些限制,迫使它生成的隐含向量能够粗略的遵循一个标准正态分布,这就是它与一般的自动编码器最大的不同。
在变分自动编码器中,只需要给它一个标准正态分布的随机向量,利用解码器就可以生成一张图片。不需要先给它一张原始图片。
模型的准确率:解码器生成的图片与原图片的相似程度。
loss的计算:解码器生成图片与原始图片的均方误差 + 隐含向量与标准正态分布之间的差异 (使用的是KL divergence)
在变分编码器中,使用了一个技巧-重新参数化,来解决KL divergence的计算问题
不再每次生成一个隐含向量,而是生成两个向量:一个表示均值,一个表示标准差,然后通过这两个统计量合成隐含向量,用一个标准正态分布先乘上标准差再加上均值。这里默认编码之后的隐含向量是服从一个正态分布的,这个时候要让均值尽可能接近0,
3.对抗过程
对抗过程是一个判断真假的判别器,相当于一个二分类问题。输入一张图片,如果是真的图片希望判别器输出为1,假的图片输出为0,这与图片的标签没有关系。
4.训练过程
先优化判别器,将真的图片和假的图片都输入给判别模型,让判别器计算损失,不断优化,让判别器能够区分出真的图片和假的图片,真的图片为1,假的为0.
然后优化生成器。固定判别器的参数,不断优化生成器,使生成器的生成的结果传递给判别器之后,尽可能的接近1,调整损失函数。
5.判别模型训练
开始需要自己创建label,真实的数据时1,生成的假的数据时0,然后将真实的数据输入给判别器,计算loss值,将假的数据输入判别器得到loss,将这两个loss加起来得到总的loss,然后反向传播更新参数能够得到一个优化好的判别器。
6.生成器训练
一个随机隐含向量通过生成网络得到了一个假的数据,然后希望假的数据经过判别模型尽可能和真实label接近,通过g_loss = criterion(output,real_label)实现,然后反向传播去优化生成器的参数,在这个过程中,判别器的参数不再发生变化,否则生成器永远无法骗过优化的判别器。
DCGAN,使用celeba数据集
训练过程:
第一批次(batch-size):
1.将随机生成的128*100*1*1给G网络,生成128*3*64*64的图片
2.将这些假图片给D网络,计算损失,并且把一批真图片(128*3*64*64,每次从Dataloder迭代器中拿出来一批作为真图片 )计算损失,两者损失相加,进行梯度优化
3.计算生成器损失,计算D(G(X)),把128张假图片,放入判别器,更新G的梯度,假图片标签为1
4.这就完成了一次一批(128张)的生成和判别
第二批次(batch-size):
1.又取出来一批真数据,假数据(重新生成一批假数据放入G网络中,生成128张假数据),放入D网络,真数据标签为1,假数据标签为0,放在一起计算损失,进行优化
2.然后把这些假数据放入D网络中,计算损失更新G网络的参数权重,注意的一点是,此时假数据的标签为1
3.规定训练到一定次数时,随机生成64*100*1*1的向量生成64张图片来查看生成假图片的效果
......
训练5个epochs
torch_09_GAN的更多相关文章
随机推荐
- 刨树根,抓住redis 进行七连问
追着 redis 进行七连问 Hello Redis 有几个问题想请教你 Hello,Redis! 我们相处已经很多年了,从模糊的认识到现在我们已经深入结合,你的好我一直都知道也一直都记住,能否在让我 ...
- layui + mvc + ajax 导出Excel功能
为了更方便,没基础的伙伴更容易理解,我尽量详细简便 省了很多代码,一步一步的试 自己引入文件 1. html 前端视图代码 Layui的数据绑定 全部代码 @{ Layout = null; } &l ...
- python算法题 python123网站单元四题目
目录 一:二分法求平方根 二:Collatz猜想 三:算24(只考虑满足,不考虑把所有情况找出来) 下面向大家介绍几个python算法题. 一:二分法求平方根 1.题目要求为 2.输入输出格式为 ...
- webpack4 css modules
demo 代码点此,webpack4 中通过 css-loader 开启 css 模块化, 开始前先做点准备工作. 不了解 css 模块化的,可以前往查看github_css_modules. ##准 ...
- 使用Composer安装阿里云短信失败
安装步骤 请参考以下步骤,使用Composer安装依赖. 如果在您的系统上全局安装Composer,您可以在项目目录中运行以下内容,将 Alibaba Cloud Client for PHP 添加为 ...
- 不了解MES系统中的看板管理?看完本文就懂了
如果想要在生产车间中,让生产过程管理都处在“看得见”的状态,那么看板可视化管理的导入是你的不二选择. MES看板包括四个部分:生产任务看板.各生产单位生产情况看板.质量看板和物料看板,其中生产任务看板 ...
- Git学习笔记3-远程仓库
1.添加远程仓库 $ git remote add [shortname] [url] $ git remote add origin https://github.com/Mike199201/Gi ...
- 002-OpenStack-认证服务
OpenStack-认证服务 [基于此文章的环境]点我快速打开文章 1.安装和配置 控制节点(controller) 1.1 创库授权 keystone mysql CREATE DATABASE k ...
- ArrayList对象声明& arrayList.size()
此程序用于测试 :每次for循环内重新定义一个Integer数组,赋值后加入arrayList.由于下一次的Integer对象重新定义,原来的对象是否会被释放? 解答:不会,因为原对象仍被引用(被ar ...
- 06webpack-- html-webpack-plugin的2个作用
<!-- 15 html-webpack-plugin的2个作用 下载 cnpm i html-webpack-plugin -D 作用在==>内存中生成页面 在webpack中 导入在内 ...