Python中使用@的理解
Python函数中使用@
稍提一下的基础
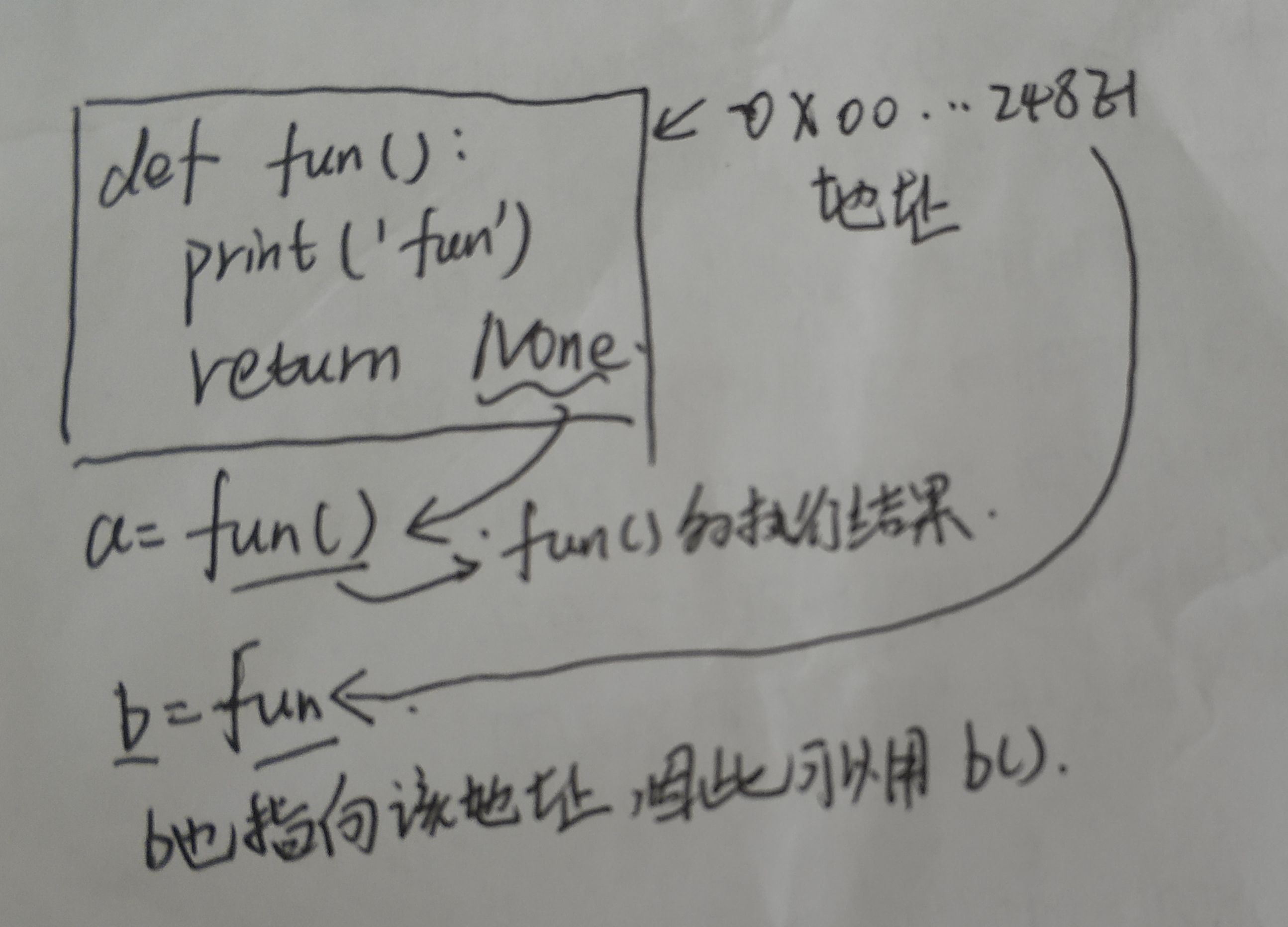
fun 和fun()的区别
以一段代码为例:
def fun():print('fun')return Nonea = fun() #fun函数并将返回值给aprint('a的值为',a)b = fun #将fun函数地址赋给bb() #调用b,b和fun指向的地址相同print('b的值为',b)'''输出funa的值为 Nonefunb的值为 <function fun at 0x00000248E1EBE0D0>'''
根据输出可以看出,a=fun()是将函数fun的返回值(None)赋给a,而b=fun是将函数的地址赋给b,如果调用函数,需要b()
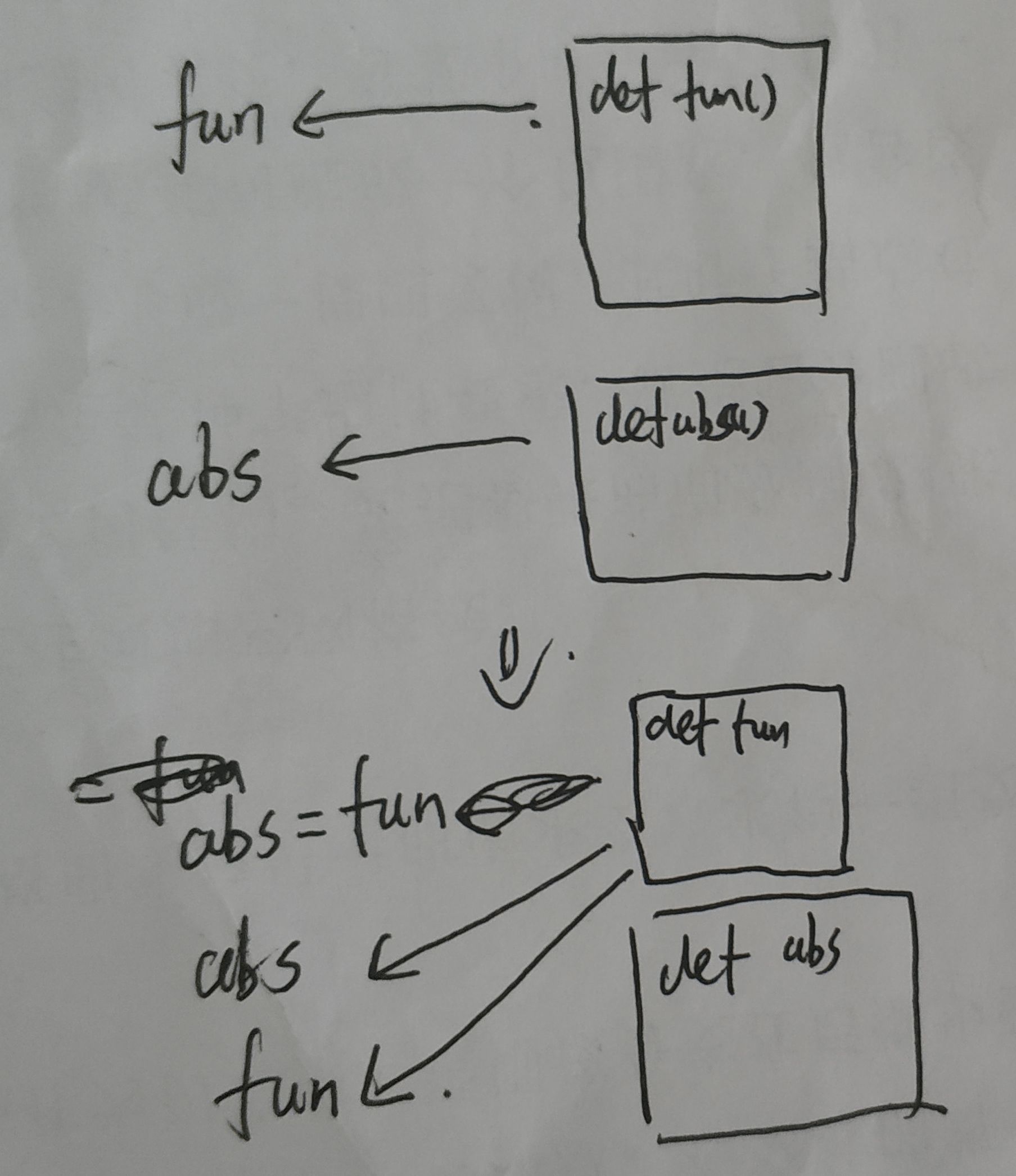
类似的,其他内置函数也可以通过这种方法,相当于起了一个同名的函数
>>>a = abs>>>a(-1)1
除此之外,原来的函数名也被覆盖为其他函数,例如
def fun():print('fun')abs = funabs() #输出fun
综上,可以理解为fun,abs在不带括号时为变量,该变量包含了函数在内容的地址
返回函数
参考链接:https://www.liaoxuefeng.com/wiki/1016959663602400/1017434209254976
以廖老师的教程为例
def lazy_sum(*args):def sum():ax = 0for n in args:ax = ax + nreturn axreturn sum>>> f = lazy_sum(1, 3, 5, 7, 9)>>> f<function lazy_sum.<locals>.sum at 0x101c6ed90>>>>f()25
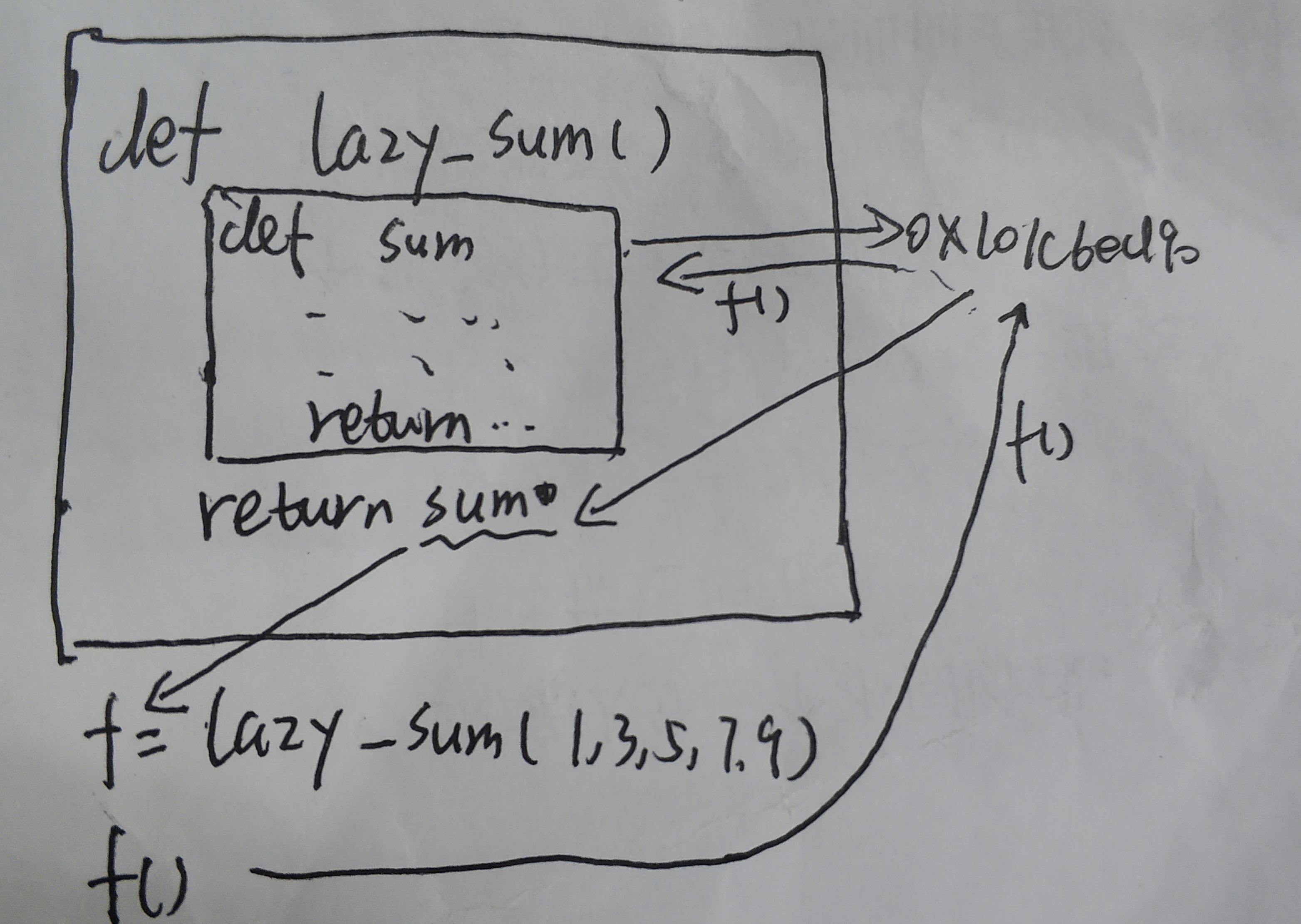
在单步调试中可以发现,当读到def sum():时,解释器会直接跳到return sum将sum函数的地址返回给f,因此f()即为执行sum() (不是非常准确,但先如此理解)
如果对返回函数还是有些不理解的话,可以假设lazy_sum()的返回值改为1
def lazy_sum(*args):def sum():ax = 0for n in args:ax = ax + nreturn axreturn 1f = lazy_sum(1,3,5,7,9)print(f)#Q输出1print(f())#报错'int' object is not callable
此时无论lazy_sum()的参数如何修改,都会把1赋给f,而1()是不可调用的,因此会报错
⭐️返回函数中的闭包问题也要了解一下,内嵌函数可以访问外层函数的变量
参数的嵌套调用
仍然上述例子,此时将lazy_sum()改为空函数,内嵌的sum()需要参数:
def lazy_sum():def sum(*args):ax = 0for n in args:ax = ax + nreturn axreturn sumf = lazy_sum()(1,3,5,7,9)print(f)#输出25
按照运算的优先级,可以理解为:
- 执行
lazy_sum(),返回sum; - 执行
sum(1,3,5,7,9),返回25; - 将
25赋给f
如果有了以上基础,再来看@的用法就会觉得很容易了
@的使用
如果需要具体理解装饰器,可以参考廖老师的博客,本文仅介绍@的执行流程
本文参考了 Python @函数装饰器及用法(超级详细),Python中的注解“@”
不带参数的单一使用(一个@修饰)
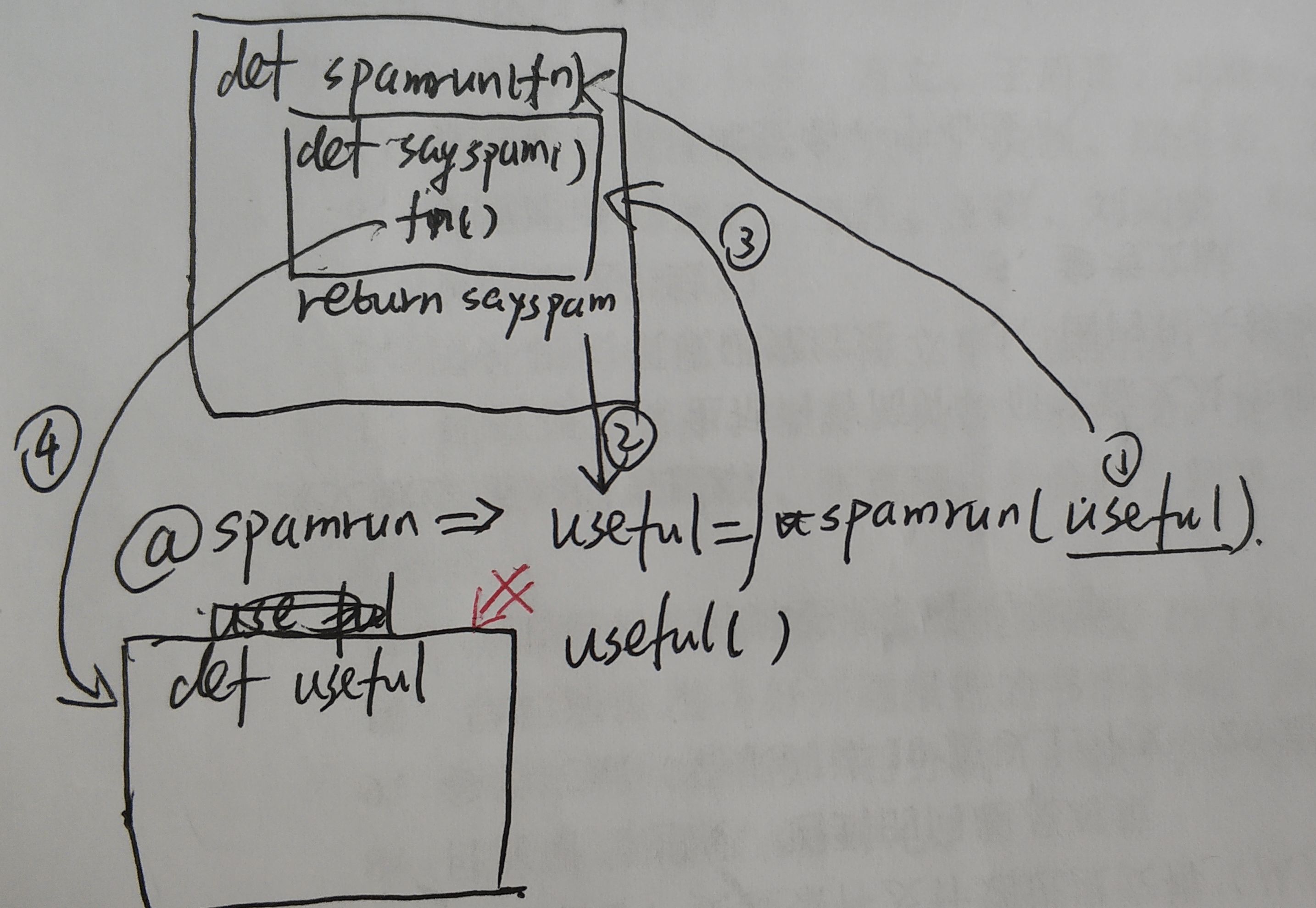
def spamrun(fn):def sayspam():print("spam,spam,spam")fn()return sayspam@spamrundef useful():print('useful')useful()'''输出:spam,spam,spamuseful'''
修饰效果相当于useful = spamrun(useful),具体步骤如下:
- 在初始化时,解释器读到
@spamrun,此时将下方的useful作为参数传入到spamrun中 spamrun(useful)中,由于是返回函数,直接将sayspam()的内存地址赋给useful- 执行
useful(),此时useful指向了sayspam,因此打印spam,spam,spam。然后执行fn(),此时的fn才指向原来的useful()的地址,开始执行print('useful')
执行流程可以在下图了解一下,可以理解为经过@后,useful已经不直接指向函数useful()的地址了,而是sayspam。再调用useful()时,执行sayspam(),由于fn保存原先useful()函数的地址,因此可以执行useful()的功能,即可以打印出'useful'。如果‘使坏’把fn()去掉的话,相当于useful()再也不会执行了
一般情况下,使用@时不会改变函数原先的执行逻辑,而只是增加功能,因此成为装饰器,如廖老师教程中可以使原函数打印日志
def log(func):def wrapper(*args, **kw):print('call %s():' % func.__name__)return func(*args, **kw)return wrapper@logdef now():print('2015-3-25')now()'''call now():2015-3-25'''
不带参数的多次使用(两个@)
def spamrun(fn):def sayspam():print("spam,spam,spam")fn()return sayspamdef spamrun1(fn):def sayspam1():print("spam1,spam1,spam1")fn()return sayspam1@spamrun@spamrun1def useful():print('useful')useful()'''spam,spam,spamspam1,spam1,spam1useful'''
修饰效果相当于useful = spamrun(spamrun1(useful))
叠加使用时,装饰器的调用顺序和声明顺序是相反的,可以理解成是一个递归的过程。
- 遇到
@spamrun,开始向下寻找def 函数名 - 结果第二行也是一个@。
@spamrun1继续向下找 - 遇到了
def useful,执行useful = spamrun1(useful) - 回归。
@spamrun1返回useful给@spamrun,执行useful=spamrun(useful)
带参数的单次使用
以廖老师教程中的举例,简化一些,先不考虑*args,**kw,因为涉及到返回函数的闭包问题
def log(text):def decorator(func):def wrapper():print('%s %s():' % (text, func.__name__))return func()return wrapperreturn decorator@log('execute')def now():print('2015-3-25')now()
修饰效果相当于now=log('execute')(now)
1. 解释器读到@log('execute'),先执行了log('execute'),返回函数decorator
2. 将now作为decorator(func)的形参,返回warpper
3. 将`warpper`的内存地址赋给变量`now`
此时调用now(),先执行完print(...),然后return func()。注意此处是带括号的,因此执行了真正的now函数,最终return的为None
带参数的多次调用可以将之前的情况组合即可
总结
- @行不带参数
@XXXdef funXXX():
会被解释成funXXX = XXX(funXXX)
- 如果@那行中带参数,则被解释成
funXXX = XXX(@行的参数)(funXXX) - 要深刻理解返回函数以及
fun和fun()的区别 - 函数的内存地址,函数变量,函数的名称的区别。默认情况下,函数变量指向函数的内存地址,但也可以被改变
初学Python,学识短浅,希望多多交流
Python中使用@的理解的更多相关文章
- 转载-对于Python中@property的理解和使用
原文链接:https://blog.csdn.net/u013205877/article/details/77804137 重看狗书,看到对User表定义的时候有下面两行 @property def ...
- Python中yield深入理解
众所周知,python中的yield有这样的用法: def test(alist): for i in alist: yield i 这样,这个test函数就变成了一个生成器,当每次调用的时候,就会自 ...
- python中Metaclass的理解
今天在学习<python3爬虫开发实战>中看到这样一段代码3 class ProxyMetaclass(type): def __new__(cls, name, bases, attrs ...
- python中切片的理解
Python中什么可以切片 l Python中符合序列的有序序列都支持切片(slice) l 如:列表,字符,元祖 Python中切片的格式 l 格式:[start : end : step] ...
- python中*args, **kwargs理解
先来看个例子: def foo(*args, **kwargs): print 'args = ', args print 'kwargs = ', kwargs print '----------- ...
- python 05 关于对python中引用的理解
数据的在内存中的地址就是数据的引用. 如果两个变量为同一个引用,那么这两个变量对应的数据一定相同: 如果两个变量对应的数据相同,引用不一定相同. 通过id(数据)可以查看数据对应的地址,修改变量的值, ...
- 深入理解python(一)python语法总结:基础知识和对python中对象的理解
用python也用了两年了,趁这次疫情想好好整理下. 大概想法是先对python一些知识点进行总结,之后就是根据python内核源码来对python的实现方式进行学习,不会阅读整个源码,,,但是应该会 ...
- Python中生成器的理解
1.生成器的定义 在Python中一边循环一边计算的机制,称为生成器 2.为什么要有生成器 列表所有的数据都存在内存中,如果有海量的数据将非常耗内存 如:仅仅需要访问前面几个元素,那后面绝大多数元素占 ...
- python中HTMLParser简单理解
找一个网页,例如https://www.python.org/events/python-events/,用浏览器查看源码并复制,然后尝试解析一下HTML,输出Python官网发布的会议时间.名称和地 ...
随机推荐
- jq 轮播图 转载-周菜菜
<style> li{list-style-type:none ; display:inline; width:90px; height:160px; float:left; } .pic ...
- JS中的浅拷贝与深拷贝
浅拷贝与深拷贝的区别: 浅拷贝: 对基本类型和引用类型只进行值的拷贝,即,拷贝引用对象的时候,只对引用对象的内存地址拷贝,新旧引用属性指向同一个对象,修改任意一个都会影响所有引用当前对象的变量. 深拷 ...
- 内核过DSE驱动签名验证.
一丶简介 现在的驱动,必须都有签名才能加载.那么如何加载无签名的驱动模块那. 下面可以说下方法.但是挺尴尬的是,代码必须在驱动中编写.所以就形成了 你必须一个驱动带有一个签名加载进去.执行你的代码.p ...
- X86 下的SSDT HOOK
目录 SSDTHOOK 1.SSDTHOOK 原理. 1.x32下的SSDT HOOK 2.SSDT HOOK代码 3.结果 4.总结 SSDTHOOK 1.SSDTHOOK 原理. x32下,直接获 ...
- pathlib.Path 类的使用
from pathlib import Path 参考 https://www.jb51.net/article/148789.htm
- 帝国cms替换iwms幻灯图片问题
在管理标签模板中增加一个新模板 页面模板内容为:[!--empirenews.listtemp--]<!--list.var1-->[!--empirenews.listtemp--] 列 ...
- jenkins使用--安装文档
添加Jenkins的源(repository): #sudo wget -O /etc/yum.repos.d/jenkins.repo http://jenkins-ci.org/redhat/je ...
- Parallel.For循环与普通的for循环
前两天看书发现了一个新的循环Parallel.For,这个循环在循环期间可以创建多个线程并行循环,就是说循环的内容是无序的.这让我想到了我前面的牛牛模拟计算是可以用到这个循环的,我前面的牛牛模拟计算是 ...
- Mariadb 10.3.17 中启用binlog
先检查是否开启了binlogSHOW VARIABLES LIKE 'log_bin';如果提示:+---------------+-------+| Variable_name | Value |+ ...
- Golang指针与unsafe
前言 我们知道在golang中是存在指针这个概念的.对于指针很多人有点忌惮(可能是因为之前学习过C语言),因为它会导致很多异常的问题.但是很多人学习之后发现,golang中的指针很简单,没有C那么复杂 ...