并发编程(五)--GIL、死锁现象与递归锁、信号量、Event事件、线程queue
一、GIL全局解释器锁
1、什么是全局解释器锁
GIL本质就是一把互斥锁,相当于执行权限,每个进程内都会存在一把GIL,同一进程内的多个线程,必须抢到GIL之后才能使用Cpython解释器来执行自己的代码,即同一进程下的多个线程无法实现并行,但是可以实现并发。
#1 所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码) #2 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
例如下面多个线程的执行过程:
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
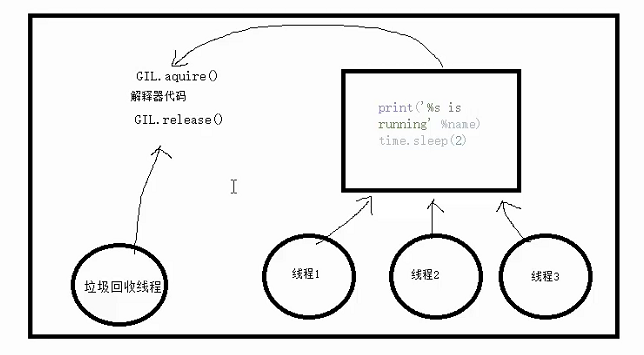
2、为什么要用GIL
因为CPython解释器的垃圾回收机制不是线程安全的
二、GIL与LOCK
锁的目的 :锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
(1)GIL是保护解释器级别的锁,使利用CPython解释器时并发使用
(2)LOCK是自定义的锁,用来保证多线程/进程对同一个数据进行修改时的数据安全,使修改数据时串行
所有线程抢的是GIL锁,或者说所有线程抢的是执行权限 线程1抢到GIL锁,拿到执行权限,开始执行,然后加了一把Lock,还没有执行完毕,即线程1还未释放Lock,有可能线程2抢到GIL锁,开始执行,执行过程中发现Lock还没有被线程1释放,于是线程2进入阻塞,被夺走执行权限,有可能线程1拿到GIL,然后正常执行到释放Lock。。。这就导致了串行运行的效果 既然是串行,那我们执行 t1.start() t1.join t2.start() t2.join() 这也是串行执行啊,为何还要加Lock呢,需知join是等待t1所有的代码执行完,相当于锁住了t1的所有代码,而Lock只是锁住一部分操作共享数据的代码
分析
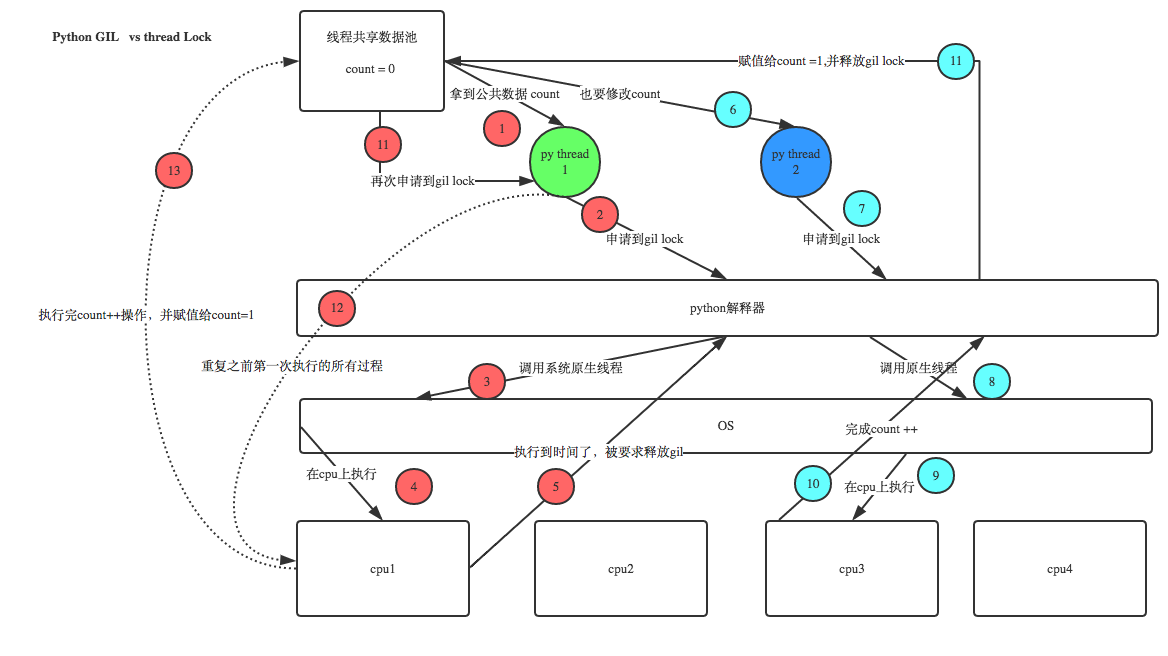
注意点 :
#1.线程抢的是GIL锁,GIL锁相当于执行权限,拿到执行权限后才能拿到互斥锁Lock,其他线程也可以抢到GIL,但如果发现Lock仍然没有被释放则阻塞,
即便是拿到执行权限GIL也要立刻交出来 #2.join是等待所有,即整体串行,而锁只是锁住修改共享数据的部分,即部分串行,要想保证数据安全的根本原理在于让并发变成串行,join与互斥锁都可以实现,
毫无疑问,互斥锁的部分串行效率要更高
三、GIL与多线程
1、进程可以利用多核,但是开销大,而python的多线程开销小,但却无法利用多核优势
===>
#1. cpu到底是用来做计算的
#2. 多cpu,意味着可以有多个核并行完成计算,所以多核提升的是计算性能
#3. 每个cpu一旦遇到I/O阻塞,仍然需要等待,所以多核对I/O操作没什么用处
因此,对计算来说,cpu越多越好,但是对于I/O来说,再多的cpu也没用。当然对运行一个程序来说,随着cpu的增多执行效率肯定会有所提高(不管提高幅度多大,总会有所提高),这是因为一个程序基本上不会是纯计算或者纯I/O,所以我们只能相对的去看一个程序到底是计算密集型还是I/O密集型,从而进一步分析python的多线程到底有无用武之地
#分析:
我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是:
方案一:开启四个进程
方案二:一个进程下,开启四个线程 #单核情况下,分析结果:
如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜
如果四个任务是I/O密集型,方案一创建进程的开销大,且进程的切换速度远不如线程,方案二胜 #多核情况下,分析结果:
如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜
如果四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜 #结论:
现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
===>多核情况下,Python对于计算密集型,使用多进程的效率高
而对于I/O密集型,Python使用多线程的效率高一点
2、测试
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(10000):
res*=i if __name__ == '__main__':
l=[]
print(os.cpu_count())
start=time.time()
for i in range(4):
p=Process(target=work)
#p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
计算密集型,多进程效率高
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():
time.sleep(2)
print('===>') if __name__ == '__main__':
l=[]
print(os.cpu_count())
start=time.time()
for i in range(400):
# p=Process(target=work)
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
I/O密集型,多线程效率高
应用场景:
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
四、死锁现象与递归锁
1、死锁现象
两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
此时称系统处于死锁状态或系统产生了死锁(例如a持有B房间的钥匙,却被所在A房间,而b持有A房间的钥匙,却被锁在B房间,两人都被锁了),
这些永远在互相等待的进程称为死锁进程
from threading import Thread,Lock,RLock
import time mutexA=Lock()
mutexB=Lock() class Mythead(Thread):
def run(self):
self.f1()
self.f2() def f1(self):
mutexA.acquire()
print('%s 抢到A锁' %self.name)
mutexB.acquire()
print('%s 抢到B锁' %self.name)
mutexB.release()
mutexA.release() def f2(self):
mutexB.acquire()
print('%s 抢到了B锁' %self.name)
time.sleep(2)
mutexA.acquire()
print('%s 抢到了A锁' %self.name)
mutexA.release()
mutexB.release() if __name__ == '__main__':
for i in range(100):
t=Mythead()
t.start()
死锁
2、死锁的解决方法——递归锁
在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
mutexA=mutexB=threading.RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,
这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止
五、信号量
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
===>一直有n个线程并发运行,但是这n个线程是变化的,不是最初的n个线程在运行
from threading import Thread,Semaphore
import time,random
sm=Semaphore(5) #允许5个线程并发运行,但是5个线程可以不是原来那5个 def task(name):
sm.acquire()
print('%s 正在上厕所' %name)
time.sleep(random.randint(1,3))
sm.release() if __name__ == '__main__':
for i in range(20):
t=Thread(target=task,args=('路人%s' %i,))
t.start()
六、Event
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
from threading import Thread,Event
import time event=Event() def light():
print('红灯正亮着')
time.sleep(3)
event.set() #绿灯亮 def car(name):
print('车%s正在等绿灯' %name)
event.wait() #等灯绿
print('车%s通行' %name) if __name__ == '__main__':
# 红绿灯
t1=Thread(target=light)
t1.start()
# 车
for i in range(10):
t=Thread(target=car,args=(i,))
t.start()
车与红绿灯问题
七、进程队列(比较互斥锁,推荐使用队列)
1、queue队列 :使用import queue,用法与进程Queue一样
2、三种队列
(1). Queue:先进先出队列
import queue q=queue.Queue()
q.put('first')
q.put('second')
q.put('third') print(q.get())
print(q.get())
print(q.get()) '''
结果(先进先出):
first
second
third
'''
Queue队列
(2). LifoQueue:先进后出队列(相当于堆栈)
import queue q=queue.Queue()
q.put('first')
q.put('second')
q.put('third') print(q.get())
print(q.get())
print(q.get()) '''
结果(先进先出):
third
second
first
'''
先进后出队列
(3). ProirityQueue:优先级队列
put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
import queue q=queue.PriorityQueue()
#put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((20,'a'))
q.put((10,'b'))
q.put((30,'c')) print(q.get())
print(q.get())
print(q.get()) '''
结果(数字越小优先级越高,优先级高的优先出队):
(10, 'b')
(20, 'a')
(30, 'c')
'''
优先级队列
并发编程(五)--GIL、死锁现象与递归锁、信号量、Event事件、线程queue的更多相关文章
- python并发编程-多线程实现服务端并发-GIL全局解释器锁-验证python多线程是否有用-死锁-递归锁-信号量-Event事件-线程结合队列-03
目录 结合多线程实现服务端并发(不用socketserver模块) 服务端代码 客户端代码 CIL全局解释器锁****** 可能被问到的两个判断 与普通互斥锁的区别 验证python的多线程是否有用需 ...
- 8.14 day32 TCP服务端并发 GIL解释器锁 python多线程是否有用 死锁与递归锁 信号量event事件线程q
TCP服务端支持并发 解决方式:开多线程 服务端 基础版 import socket """ 服务端 1.要有固定的IP和PORT 2.24小时不间断提供服务 3.能够支 ...
- 并发编程~~~多线程~~~守护线程, 互斥锁, 死锁现象与递归锁, 信号量 (Semaphore), GIL全局解释器锁
一 守护线程 from threading import Thread import time def foo(): print(123) time.sleep(1) print('end123') ...
- (并发编程)RLock(与死锁现象),Semaphore,Even事件,线程Queue
一.死锁现象与递归锁所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在 ...
- 并发编程---死锁||递归锁---信号量---Event事件---定时器
死锁 互斥锁:Lock(),互斥锁只能acquire一次 递归锁: RLock(),可以连续acquire多次,每acquire一次计数器+1,只有计数为0时,才能被抢到acquire # 死锁 f ...
- GIL全局解释器锁-死锁与递归锁-信号量-event事件
一.全局解释器锁GIL: 官方的解释:掌握概念为主 """ In CPython, the global interpreter lock, or GIL, is a m ...
- GIL 信号量 event事件 线程queue
GIL全局解释器锁 官方解释: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple n ...
- 并发编程(五)——GIL全局解释器锁、死锁现象与递归锁、信号量、Event事件、线程queue
GIL.死锁现象与递归锁.信号量.Event事件.线程queue 一.GIL全局解释器锁 1.什么是全局解释器锁 GIL本质就是一把互斥锁,相当于执行权限,每个进程内都会存在一把GIL,同一进程内的多 ...
- Python并发编程05 /死锁现象、递归锁、信号量、GIL锁、计算密集型/IO密集型效率验证、进程池/线程池
Python并发编程05 /死锁现象.递归锁.信号量.GIL锁.计算密集型/IO密集型效率验证.进程池/线程池 目录 Python并发编程05 /死锁现象.递归锁.信号量.GIL锁.计算密集型/IO密 ...
随机推荐
- python 并行处理数据
来源:https://blog.csdn.net/weixin_42001089/article/details/88843152 import multiprocessing import time ...
- VMware虚拟机安装使用及系统安装教程
虚拟机是利用软件来模拟出完整计算机系统的工具.具有完整硬件系统功能的.运行在一个完全隔离环境中.虚拟机的使用范围很广,如未知软件评测.运行可疑型工具等,即使这些程序中带有病毒,它能做到的只有破坏您的虚 ...
- Redis笔记1-Redis介绍及数据类型使用场景
Redis介绍:C语言开发.单线程操作.高性能.键值对.可持久化的数据库.Redis采用redisObject结构来统一五种数据类型,redisObject是五种类型的父类,可以在函数间传递时隐藏具体 ...
- 新电脑安装操作系统一定要注意硬盘是否被bitlocker加密!
新电脑安装操作系统一定要注意硬盘是否被bitlocker加密! 前段时间帮一MM的戴尔灵越14燃5488装机,购买不久的电脑,硬盘是被bitlocker加密的,鬼知道戴尔为什么这么过分.按照常规思路, ...
- Spring Boot 知识笔记(集成zookeeper)
一.本机搭建zookeeper伪集群 1.下载安装包,复制三份 2.每个安装包目录下面新建一个data文件夹,用于存放数据目录 3.安装包的conf目录下,修改zoo.cfg配置文件 # The nu ...
- GreenPlum 大数据平台--segment 失效问题恢复《二》(全部segment宕机情况下)
01,情况描述 主Segment和它的镜像都宕掉.导致了greenplum数据库不可用状态 02,重启greenplum数据库 gpstop -r 03,恢复 gprecoverseg 04,状态检查 ...
- 远程文件传输命令•RHEL8/CentOS8文件上传下载-用例
scp协议 scp [options] [本地用户名@IP地址:]file1 [远程用户名 @IP 地址 :] file2 options: -v 用来显示进度,可以用来查看连接,认证,或是配置错误. ...
- 实验一 Linux基础与Java开发环境
实验一 (一)实验内容 基于命令行和IDE(Intellj IDEA 简易教程http://www.cnblogs.com/rocedu/p/4421202.html)进行简单的Java程序编辑.编译 ...
- Qt对话框之二:模态、非模态、半模态对话框
一.模态对话框 模态对话框:阻塞同一应用程序中其它可视窗口输入的对话框.模态对话框有自己的事件循环,用户必须完成这个对话框中的交互操作,并且关闭了它之后才能访问应用程序中的其它任何窗口. 显示模态对话 ...
- linux ,查看端口
netstat -antlp | grep java 注:grep java是过滤所有java进程