【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:
掌握定向网络数据爬取和网页解析的基本能力
the Website is the API…
1 python ide
文本ide:IDLE,Sublime Text
集成ide:Pycharm,Anaconda&Spyder,Wing,Visual Studio & PTVS,Eclipse & PyDev,Canopy
默认源太慢:
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) https://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 https://pypi.mirrors.ustc.edu.cn/simple/
2 网络爬虫规则
2.1 Requests库 自动爬取html页面
#安装方法 管理员权限启动cmd安装
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
#测试下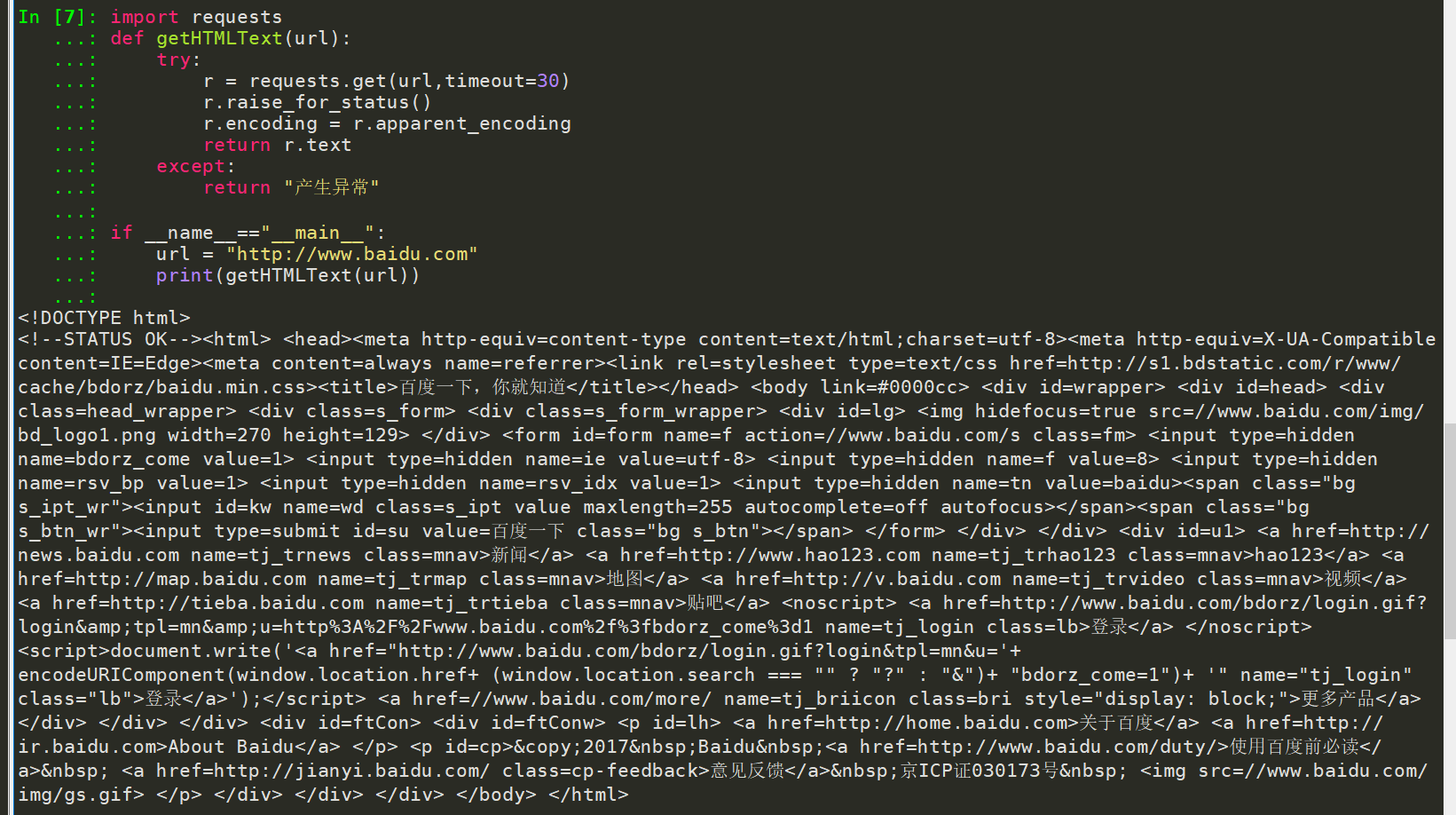
#requests库7个主要方法:
a、requests.request() 构造一个请求,支撑以下各方法的基础方法
b、requests.get() 获取HTML网页的主要方法,对应于HTTP的GET
c、requests.head() 获取HTML网页头信息的方法,对应于HTTP的HEAD
d、requests.post() 向HTML网页提交POST请求的方法,对应于HTTP的POST
e、requests.put() 向HTML网页提交PUT请求的方法,对应于HTTP的PUT
f、requests.patch() 向HTML网页提交局部修改请求,对应于HTTP的PATCH
g、requests.delete() 向HTML页面提交删除请求,对应于HTTP的DELETE
r = requests.get(url)
r是返回一个包含服务器资源的Response对象,右边是构造一个向服务器请求资源的Request对象
requests.get(url,params=None,**kwargs) 完整格式
params:url中的额外参数,字典或者字节流格式可选
**kwargs:12个控制访问参数可选
打开源码可知,get方法是调用requests方法封装的,实际上7个方法中,其余6个都是由request方法封装
Response对象常用5个属性
r.status_code HTTP请求的返回状态,200表示连接成功,404表示失败
r.text HTTP响应内容的字符串形式,即,url对应的页面内容
r.encoding 从HTTP header中猜测的响应内容编码方式,如果header中不存在charset,则认为编码为ISO-8859-1
r.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式)
r.content HTTP响应内容的二进制形式
requests库异常
requests.ConnectionError 网络连接错误异常,如DNS查询失败、拒绝连接等
requests.HTTPError HTTP错误异常
requests.URLRequired URL缺失异常
requests.TooManyRedirects 超过最大重定向次数,产生重定向异常
requests.ConnectTimeout 连接远程服务器超时异常
requests.Timeout 请求URL超时,产生超时异常
爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return “产生异常”
if __name__ == “__main__”:
url = “http://www.baidu.com”
print(getHTMLText(url))
http协议对资源的6中操作:
GET 请求获取URL位置的资源
HEAD 请求获取URL位置资源的响应消息报告,即获得该资源的头部信息
POST 请求向URL位置的资源后附加新的数据
PUT 请求向URL位置存储一个资源,覆盖原URL位置的资源
PATCH 请求局部更新URL位置的资源,即改变该处资源的部分内容
DELETE 请求删除URL位置存储的资源
通过URL和命令管理资源,操作独立无状态,网络通道及服务器成为了黑盒子
理解PATCH和PUT的区别:
假设URL位置有一组数据UserInfo,包括UserID、UserName等20个字段
需求:用户修改了UserName,其他不变
. 采用PATCH,仅向URL提交UserName的局部更新请求
. 采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除
PATCH的最主要好处:节省网络带宽
http协议与requests库功能是一致的
requests.request()
requests.request(method, url, **kwargs)
method : 请求方式,对应get/put/post等7种
∙ url : 拟获取页面的url链接
∙ **kwargs: 控制访问的参数,共13个
method : 请求方式
r = requests.request(‘GET’, url, **kwargs)
r = requests.request(‘HEAD’, url, **kwargs)
r = requests.request(‘POST’, url, **kwargs)
r = requests.request(‘PUT’, url, **kwargs)
r = requests.request(‘PATCH’, url, **kwargs)
r = requests.request(‘delete’, url, **kwargs)
r = requests.request(‘OPTIONS’, url, **kwargs)
**kwargs: 控制访问的参数,均为可选项
params : 字典或字节序列,作为参数增加到url中
data : 字典、字节序列或文件对象,作为Request的内容
json : JSON格式的数据,作为Request的内容
headers : 字典,HTTP定制头
cookies : 字典或CookieJar,Request中的cookie
auth : 元组,支持HTTP认证功能
files : 字典类型,传输文件
timeout : 设定超时时间,秒为单位
proxies : 字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects : True/False,默认为True,重定向开关
stream : True/False,默认为True,获取内容立即下载开关
verify : True/False,默认为True,认证SSL证书开关
cert : 本地SSL证书路径
2.2 robots.txt 网络爬虫排除标准
小规模,数据量小,爬取速度不敏感,Requests库 , 90%以上 , 爬取网页 玩转网页
中规模,数据规模较大,爬取速度敏感,Scrapy库 ,爬取网站 爬取系列网站
大规模,搜索引擎爬取,速度关键 ,定制开发,爬取全网
限制网络爬虫:1.来源审查 2.robots协议
2.3 实战项目
a.爬取京东某网页 b、爬取亚马逊某网页 有来源审查防爬虫
b、爬取亚马逊某网页 有来源审查防爬虫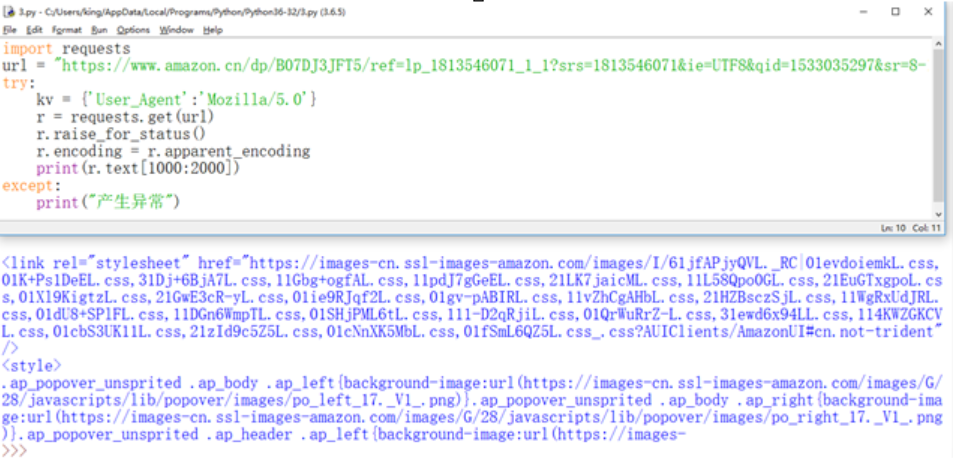 c.爬取百度搜索关键词
c.爬取百度搜索关键词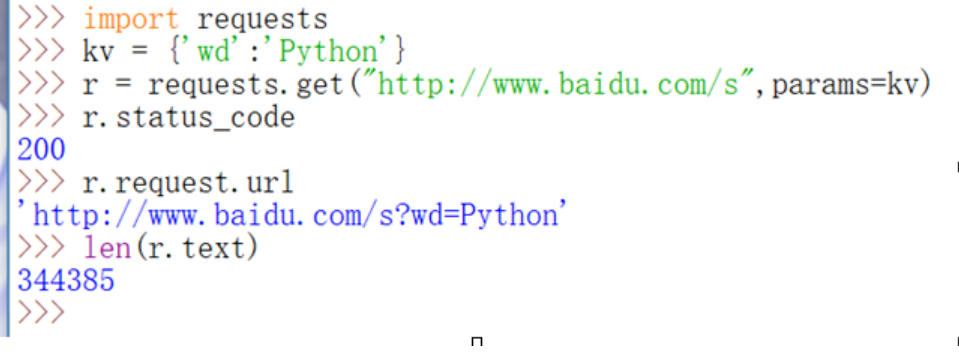 d.网络图片的爬取和存储
d.网络图片的爬取和存储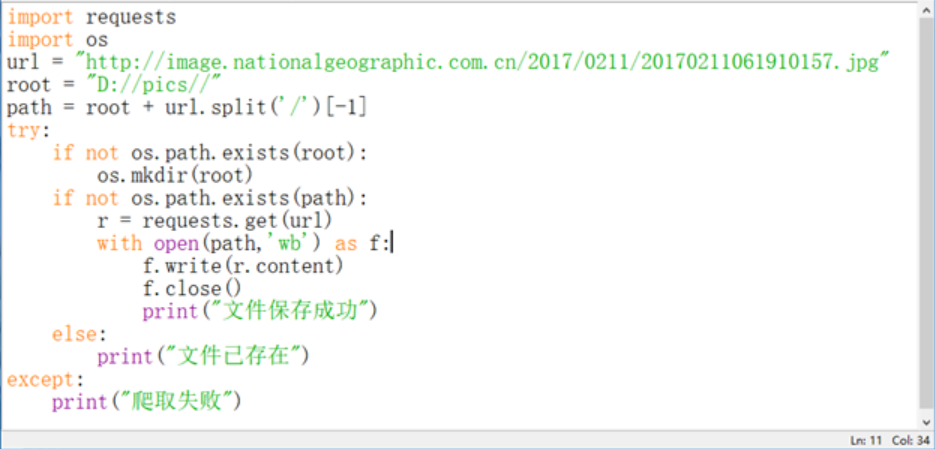
3 网络爬虫规则之提取
3.1 Beautiful Soup库入门
#安装
pip install beautifulsoup4 #测试下
#测试下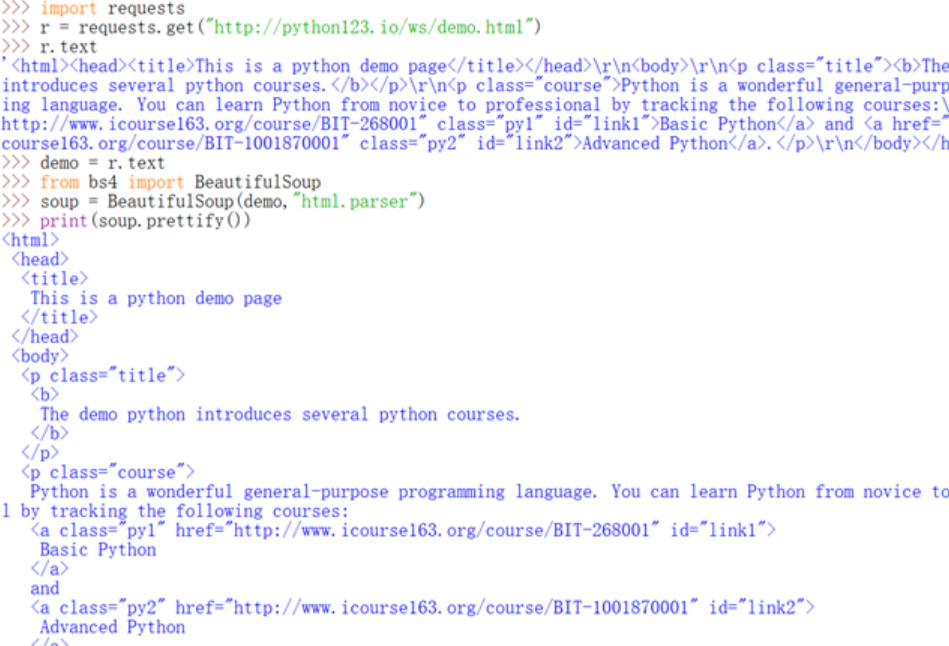 html文档 等价于 标签树 等价于 BeautifulSoup类
html文档 等价于 标签树 等价于 BeautifulSoup类
Beautiful Soup库,也叫beautifulsoup4 或bs4
约定引用方式如下,即主要是用BeautifulSoup类
import bs4 from
import bs4 from BeautifulSoup
4种解析器:
soup = BeautifulSoup(‘<html>data</html>’,’html.parser’)
bs4的HTML解析器 BeautifulSoup(mk,’html.parser’) 安装bs4库
lxml的HTML解析器 BeautifulSoup(mk,’lxml’) pip install lxml
lxml的XML解析器 BeautifulSoup(mk,’xml’) pip install lxml
html5lib的解析器 BeautifulSoup(mk,’html5lib’) pip install html5lib
BeautifulSoup类5种基本元素:
Tag 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾
Name 标签的名字,<p>…</p>的名字是’p’,格式:<tag>.name
Attributes 标签的属性,字典形式组织,格式:<tag>.attrs
NavigableString 标签内非属性字符串,<>…</>中字符串,格式:<tag>.string
Comment 标签内字符串的注释部分,一种特殊的Comment类型
Tag 标签:
任何存在于HTML语法中的标签都可以用soup.<tag>访问获得
当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个 Tag的name(名字):每个<tag>都有自己的名字,通过<tag>.name获取,字符串类型
Tag的name(名字):每个<tag>都有自己的名字,通过<tag>.name获取,字符串类型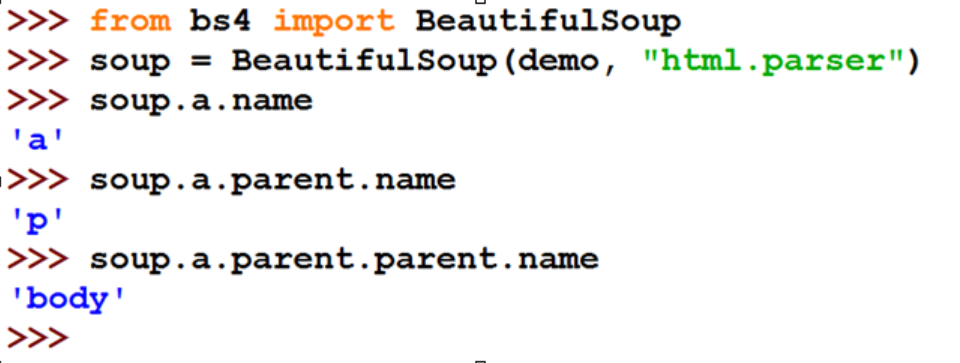 Tag的attrs(属性):一个<tag>可以有0或多个属性,字典类型
Tag的attrs(属性):一个<tag>可以有0或多个属性,字典类型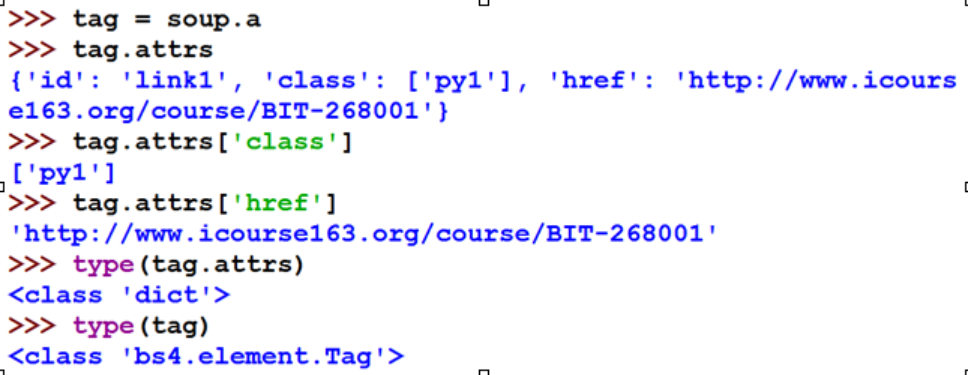 Tag的NavigableString:NavigableString可以跨越多个层次
Tag的NavigableString:NavigableString可以跨越多个层次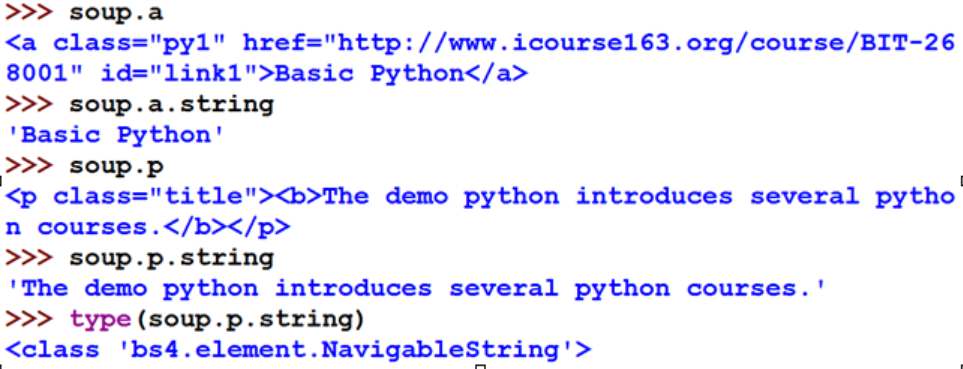 Tag的Comment:Comment是一种特殊类型
Tag的Comment:Comment是一种特殊类型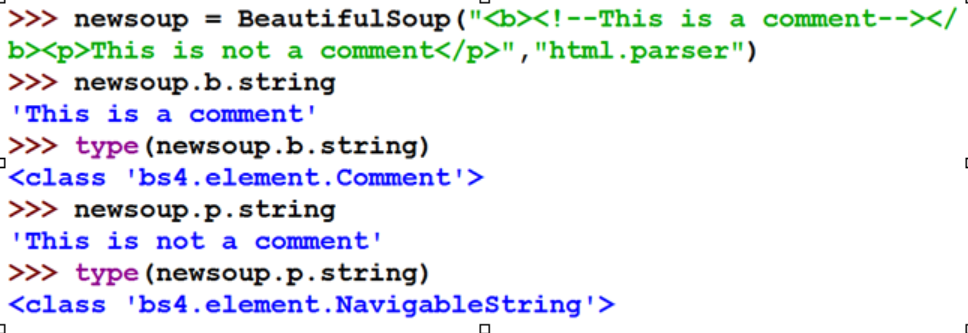
html或者xml都是树形结构
三种遍历方式:下行遍历、下行遍历、平行遍历
BeautifulSoup类型是标签树的根节点
下行遍历:
.contents 子节点的列表,将<tag>所有儿子节点存入列表
.children 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
.descendants 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
遍历儿子节点
for child in soup.body.children:
print(child)
遍历子孙节点
for child in soup.body.descendants:
print(child)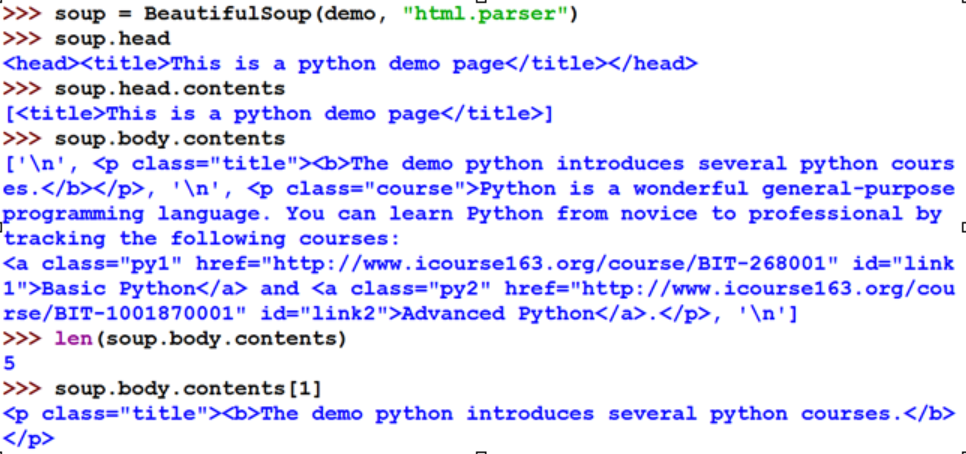
标签树的上行遍历
属性说明
.parent 节点的父亲标签
.parents 节点先辈标签的迭代类型,用于循环遍历先辈节点
遍历所有先辈节点,包括soup本身,所以要区别判断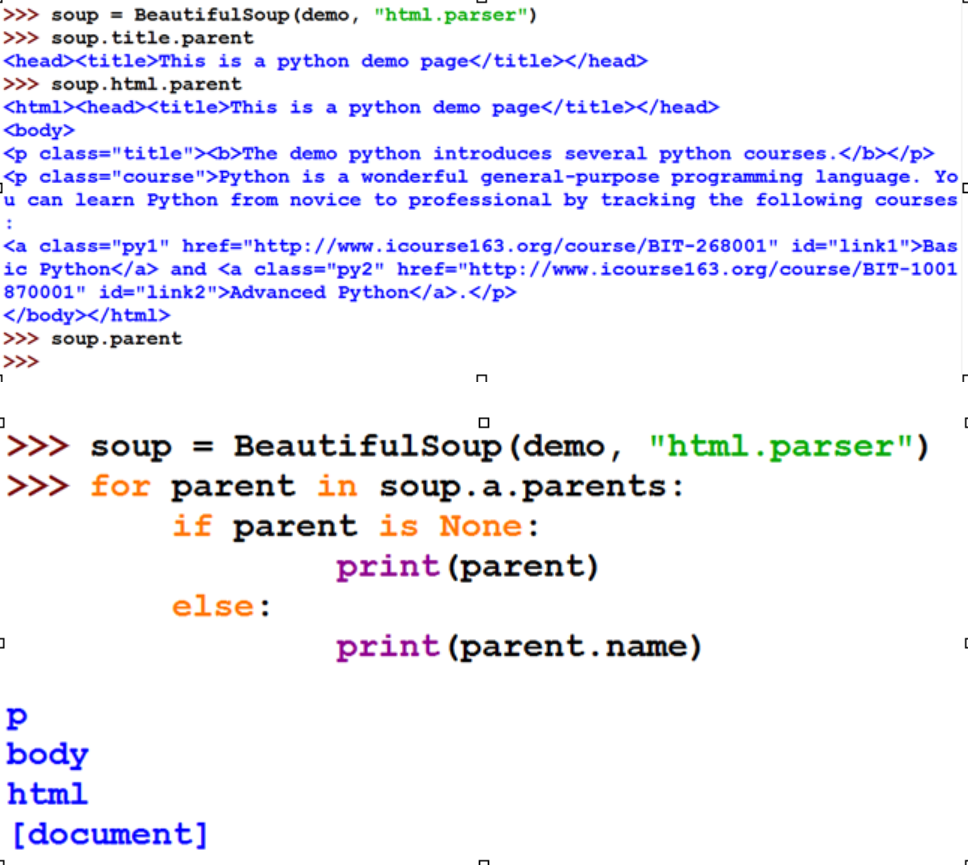
标签树的平行遍历 同一个父亲下
属性说明
.next_sibling 返回按照HTML文本顺序的下一个平行节点标签
.previous_sibling 返回按照HTML文本顺序的上一个平行节点标签
.next_siblings 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
.previous_siblings 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
遍历后续节点
for sibling in soup.a.next_sibling:
print(sibling)
遍历前续节点
for sibling in soup.a.previous_sibling:
print(sibling)
基于bs4库的HTML格式输出 如何让html页面更加友好的输出
bs4库的prettify()方法
.prettify()为HTML文本<>及其内容增加更加’\n’
.prettify()可用于标签,方法:<tag>.prettify()
bs4库的编码
bs4库将任何HTML输入都变成utf‐8编码
Python 3.x默认支持编码是utf‐8,解析无障碍
3.2 信息组织与提取
信息标记的三种形式:xml、json、yaml
标记后的信息可形成信息组织结构,增加了信息维度
标记的结构与信息一样具有重要价值
标记后的信息可用于通信、存储或展示
标记后的信息更利于程序理解和运用
文本、声音、图像、视频



XML 最早的通用信息标记语言,可扩展性好,但繁琐 Internet上的信息交互与传递
JSON 信息有类型,适合程序处理(js),较XML简洁 移动应用云端和节点的信息通信,无注释
YAML 信息无类型,文本信息比例最高,可读性好 各类系统的配置文件,有注释易读
信息提取的一般方法
从标记后的信息中提取所关注的内容xml、json、yaml
方法一:完整解析信息的标记形式,再提取关键信息
优点:信息解析准确
缺点:提取过程繁琐,速度慢
方法二:无视标记形式,直接搜索关键信息 对信息的文本查找函数即可
优点:提取过程简洁,速度较快
缺点:提取结果准确性与信息内容相关
融合方法:结合形式解析与搜索方法,提取关键信息
需要标记解析器及文本查找函数
<>.find_all(name, attrs, recursive, string, **kwargs)
返回一个列表类型,存储查找的结果
∙ name : 对标签名称的检索字符串
∙ attrs: 对标签属性值的检索字符串,可标注属性检索
∙ recursive: 是否对子孙全部检索,默认True
∙ string: <>…</>中字符串区域的检索字符串
<tag>(..) 等价于<tag>.find_all(..)
soup(..) 等价于soup.find_all(..)
扩展方法:
<>.find() 搜索且只返回一个结果,同.find_all()参数
<>.find_parents() 在先辈节点中搜索,返回列表类型,同.find_all()参数
<>.find_parent() 在先辈节点中返回一个结果,同.find()参数
<>.find_next_siblings() 在后续平行节点中搜索,返回列表类型,同.find_all()参数
<>.find_next_sibling() 在后续平行节点中返回一个结果,同.find()参数
<>.find_previous_siblings() 在前序平行节点中搜索,返回列表类型,同.find_all()参数
<>.find_previous_sibling() 在前序平行节点中返回一个结果,同.find()参数
3.3 实例:大学排名爬取
#CrawUnivRankingB.py
import requests
from bs4 import BeautifulSoup
import bs4 def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "" def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string]) def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288))) def main():
uinfo = []
url = 'https://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
4 网络爬虫之实战
4.1正则表达式
正则表达式语法由字符和操作符构成
常用操作符
. 表示任何单个字符
[ ] 字符集,对单个字符给出取值范围[abc]表示a、b、c,[a‐z]表示a到z单个字符
[^ ] 非字符集,对单个字符给出排除范围[^abc]表示非a或b或c的单个字符
* 前一个字符0次或无限次扩展abc* 表示ab、abc、abcc、abccc等
+ 前一个字符1次或无限次扩展abc+ 表示abc、abcc、abccc等
? 前一个字符0次或1次扩展abc? 表示ab、abc
| 左右表达式任意一个abc|def 表示abc、def
{m} 扩展前一个字符m次ab{2}c表示abbc
{m,n} 扩展前一个字符m至n次(含n) ab{1,2}c表示abc、abbc
^ 匹配字符串开头^abc表示abc且在一个字符串的开头
$ 匹配字符串结尾abc$表示abc且在一个字符串的结尾
( ) 分组标记,内部只能使用| 操作符(abc)表示abc,(abc|def)表示abc、def
\d 数字,等价于[0‐9]
\w 单词字符,等价于[A‐Za‐z0‐9_]
经典正则表达式
^[A‐Za‐z]+$ 由26个字母组成的字符串
^[A‐Za‐z0‐9]+$ 由26个字母和数字组成的字符串
^‐?\d+$ 整数形式的字符串
^[0‐9]*[1‐9][0‐9]*$ 正整数形式的字符串
[1‐9]\d{5} 中国境内邮政编码,6位
[\u4e00‐\u9fa5] 匹配中文字符
\d{3}‐\d{8}|\d{4}‐\d{7} 国内电话号码,010‐68913536
ip地址
精确写法0‐99: [1‐9]?\d
100‐199: 1\d{2}
200‐249: 2[0‐4]\d
250‐255: 25[0‐5]
(([1‐9]?\d|1\d{2}|2[0‐4]\d|25[0‐5]).){3}([1‐9]?\d|1\d{2}|2[0‐4]\d|25[0‐5])
raw string类型(原生字符串类型)
re库采用raw string类型表示正则表达式,表示为:r’text’ 例如: r'[1‐9]\d{5}’ r’\d{3}‐\d{8}|\d{4}‐\d{7}’
raw string是不包含对转义符再次转义的字符串
re库也可以采用string类型表示正则表达式,但更繁琐
例如:
‘[1‐9]\\d{5}’
‘\\d{3}‐\\d{8}|\\d{4}‐\\d{7}’
建议:当正则表达式包含转义符时,使用raw string
re库主要功能函数
re.search() 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
re.match() 从一个字符串的开始位置起匹配正则表达式,返回match对象
re.findall() 搜索字符串,以列表类型返回全部能匹配的子串
re.split() 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
re.finditer() 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
re.sub() 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
re.search(pattern, string, flags=0)
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ string : 待匹配字符串
∙ flags : 正则表达式使用时的控制标记
常用标记
re.I re.IGNORECASE 忽略正则表达式的大小写,[A‐Z]能够匹配小写字符
re.M re.MULTILINE 正则表达式中的^操作符能够将给定字符串的每行当作匹配开始
re.S re.DOTALL 正则表达式中的.操作符能够匹配所有字符,默认匹配除换行外的所有字符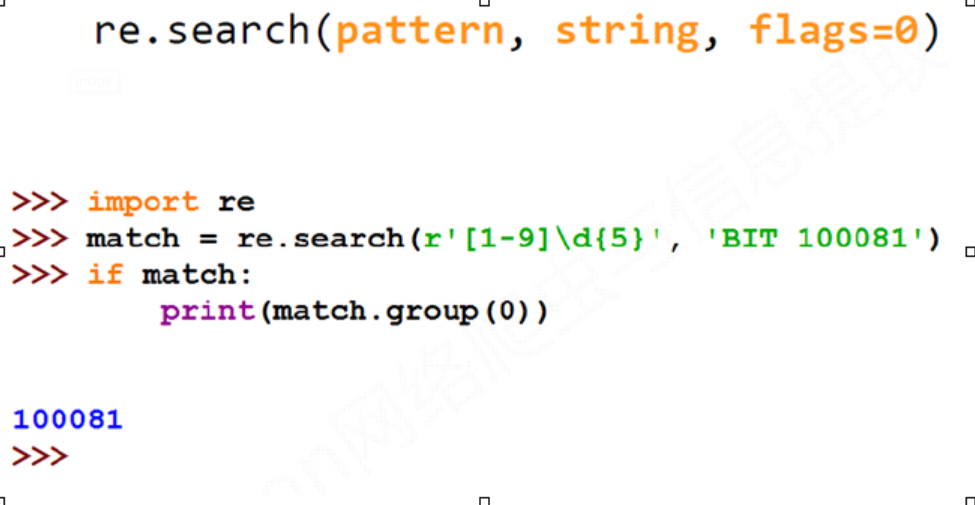
re.match(pattern, string, flags=0)
. pattern : 正则表达式的字符串或原生字符串表示
. string : 待匹配字符串
. flags : 正则表达式使用时的控制标记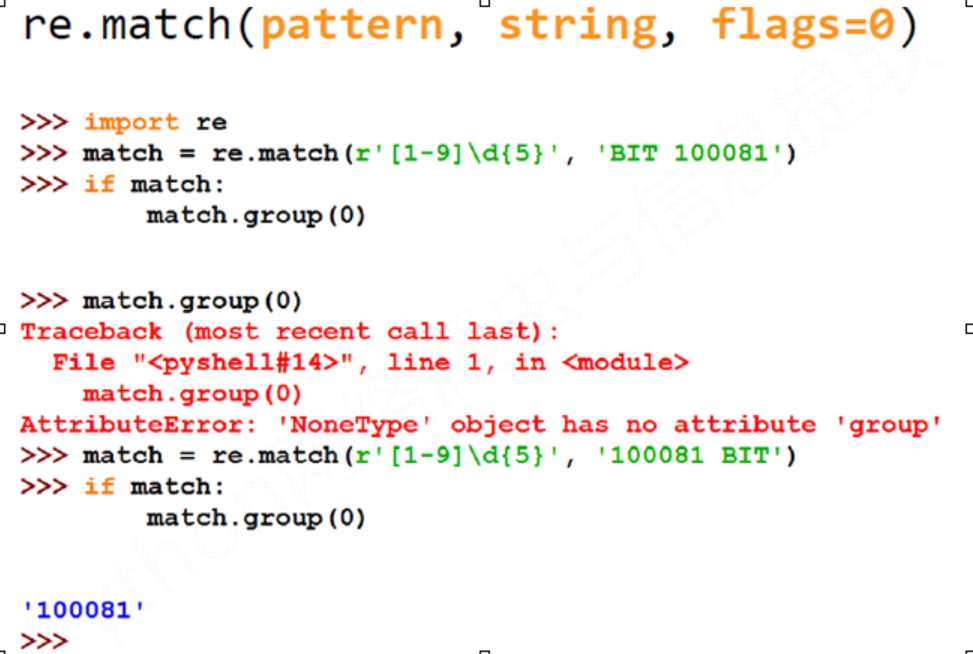
re.findall(pattern, string, flags=0)
. pattern : 正则表达式的字符串或原生字符串表示
. string : 待匹配字符串
. flags : 正则表达式使用时的控制标记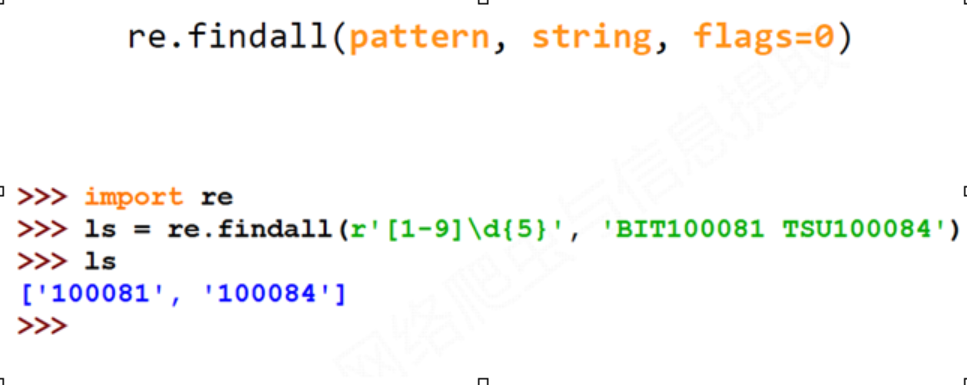
re.split(pattern, string, maxsplit=0, flags=0)
. pattern : 正则表达式的字符串或原生字符串表示
. string : 待匹配字符串
. maxsplit: 最大分割数,剩余部分作为最后一个元素输出
. flags : 正则表达式使用时的控制标记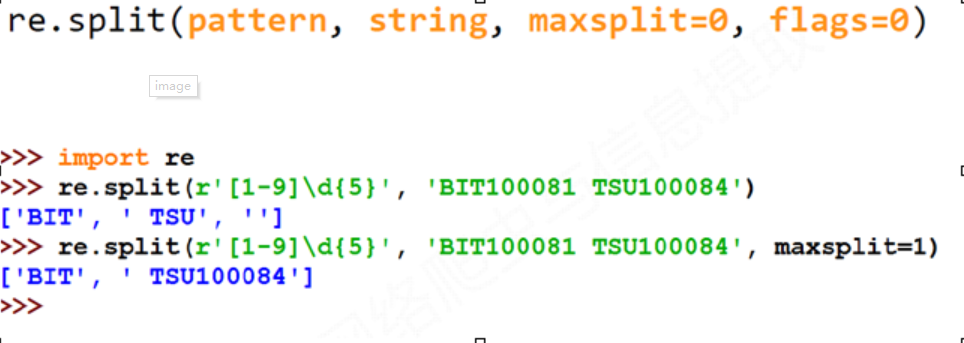
re.finditer(pattern, string, flags=0)
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ string : 待匹配字符串
∙ flags : 正则表达式使用时的控制标记
re.sub(pattern, repl, string, count=0, flags=0)
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ repl : 替换匹配字符串的字符串
∙ string : 待匹配字符串
∙ count : 匹配的最大替换次数
∙ flags : 正则表达式使用时的控制标记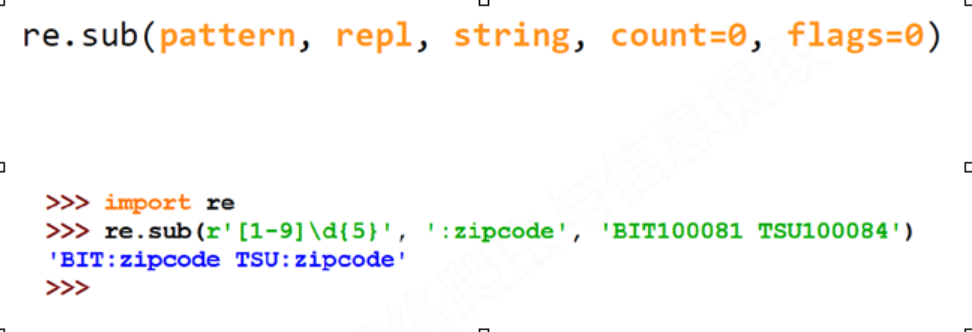
regex = re.compile(pattern, flags=0)
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ flags : 正则表达式使用时的控制标记
>>> regex = re.compile(r'[1‐9]\d{5}’)
regex.search() 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
regex.match() 从一个字符串的开始位置起匹配正则表达式,返回match对象
regex.findall() 搜索字符串,以列表类型返回全部能匹配的子串
regex.split() 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
regex.finditer() 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
regex.sub() 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
Match对象是一次匹配的结果,包含匹配的很多信息
Match对象的属性:
.string 待匹配的文本
.re 匹配时使用的patter对象(正则表达式)
.pos 正则表达式搜索文本的开始位置
.endpos 正则表达式搜索文本的结束位置
Match对象的方法:
.group(0) 获得匹配后的字符串
.start() 匹配字符串在原始字符串的开始位置
.end() 匹配字符串在原始字符串的结束位置
.span() 返回(.start(), .end())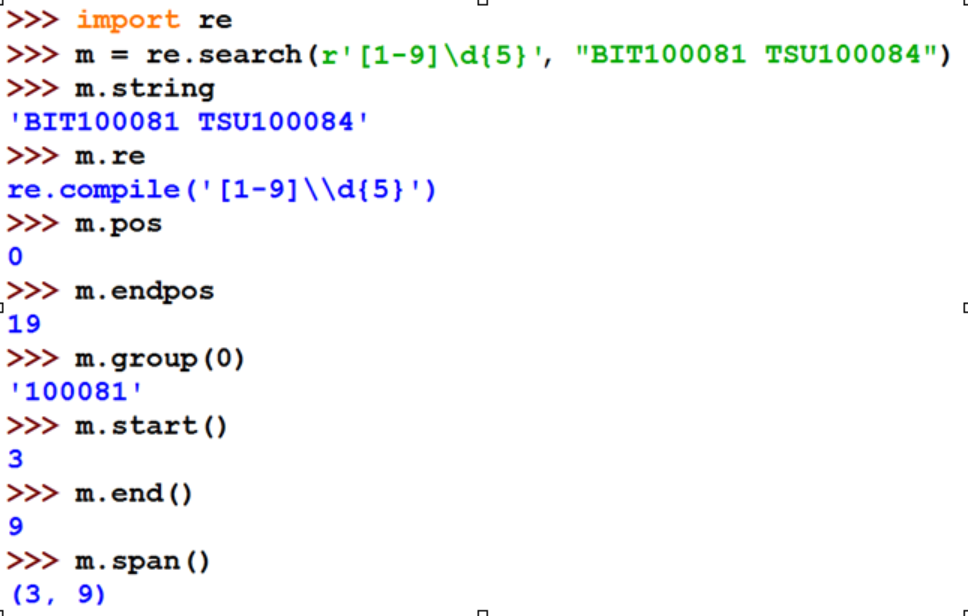
Re库的贪婪和最小匹配
Re库默认采用贪婪匹配,即输出匹配最长的子串
最小匹配操作符:
*? 前一个字符0次或无限次扩展,最小匹配
+? 前一个字符1次或无限次扩展,最小匹配
?? 前一个字符0次或1次扩展,最小匹配
{m,n}? 扩展前一个字符m至n次(含n),最小匹配
只要长度输出可能不同的,都可以通过在操作符后增加?变成最小匹配
4.2 淘宝商品比价定向爬虫
import requests
import re def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "" def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("") def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1])) def main():
goods = '书包'
depth = 3
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList) main()
4.3 股票数据定向爬虫
import requests
from bs4 import BeautifulSoup
import traceback
import re def getHTMLText(url, code="utf-8"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except:
return "" def getStockList(lst, stockURL):
html = getHTMLText(stockURL, "GB2312")
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue def getStockInfo(lst, stockURL, fpath):
count = 0
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html=="":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div',attrs={'class':'stock-bets'}) name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]}) keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
count = count + 1
print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="")
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="")
continue def main():
stock_list_url = 'https://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'D:/BaiduStockInfo.txt'
slist=[]
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file) main()
5 网络爬虫之框架-Scrapy
5.1 Scrapy框架介绍
Scrapy是一个快速功能强大的网络爬虫框架
安装:pip install scrapy
Microsoft Visual C++ 14.0 is required…报错,https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 网站下载对应版本
然后安装pip install d:\Twisted-18.7.0-cp36-cp36m-win32.whl
之后再安装scrapy
小测:scrapy ‐h
Scrapy不是一个函数功能库,而是一个爬虫框架
爬虫框架是实现爬虫功能的一个软件结构和功能组件集合
爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫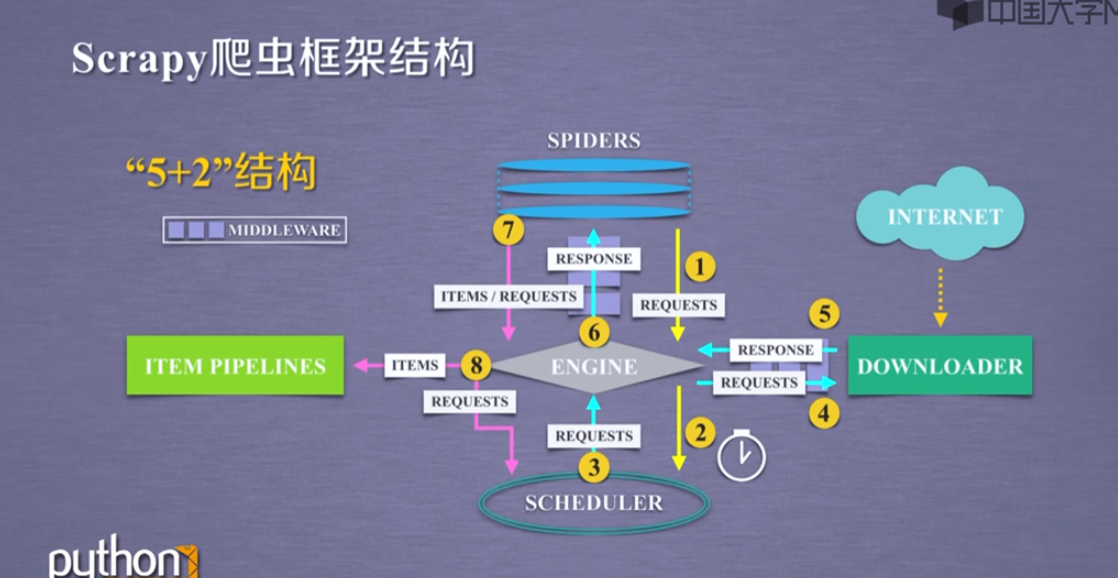
1 Engine从Spider处获得爬取请求(Request)
2 Engine将爬取请求转发给Scheduler,用于调度
3 Engine从Scheduler处获得下一个要爬取的请求
4 Engine将爬取请求通过中间件发送给Downloader
5 爬取网页后,Downloader形成响应(Response)通过中间件发给Engine
6 Engine将收到的响应通过中间件发送给Spider处理
7 Spider处理响应后产生爬取项(scraped Item)和新的爬取请求(Requests)给Engine
8 Engine将爬取项发送给Item Pipeline(框架出口)
9 Engine将爬取请求发送给Scheduler
Engine控制各模块数据流,不间断从Scheduler处获得爬取请求,直至请求为空
框架入口:Spider的初始爬取请求
框架出口:Item Pipeline
Engine
(1) 控制所有模块之间的数据流
(2) 根据条件触发事件
不需要用户修改
Downloader
根据请求下载网页
不需要用户修改
Scheduler
对所有爬取请求进行调度管理
不需要用户修改
Downloader Middleware
目的:实施Engine、Scheduler和Downloader之间进行用户可配置的控制
功能:修改、丢弃、新增请求或响应
用户可以编写配置代码
Spider
(1) 解析Downloader返回的响应(Response)
(2) 产生爬取项(scraped item)
(3) 产生额外的爬取请求(Request)
需要用户编写配置代码
Item Pipelines
(1) 以流水线方式处理Spider产生的爬取项
(2) 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
(3) 可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库
需要用户编写配置代码
Spider Middleware
目的:对请求和爬取项的再处理
功能:修改、丢弃、新增请求或爬取项
用户可以编写配置代码
requests vs. Scrapy
相同点:
两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
两者可用性都好,文档丰富,入门简单
两者都没有处理js、提交表单、应对验证码等功能(可扩展)
requests 库:
页面级爬虫
功能库
并发性考虑不足,性能较差
重点在于页面下载
定制灵活
上手十分简单
Scrapy框架:
网站级爬虫
框架
并发性好,性能较高
重点在于爬虫结构
一般定制灵活,深度定制困难
入门稍难requests
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行:scrapy <command> [options] [args]
常用命令:
startproject 创建一个新工程scrapy startproject <name> [dir]
genspider 创建一个爬虫scrapy genspider [options] <name> <domain>
settings 获得爬虫配置信息scrapy settings [options]
crawl 运行一个爬虫scrapy crawl <spider>
list 列出工程中所有爬虫scrapy list
shell 启动URL调试命令行scrapy shell [url]
5.2 Scrapy爬虫基本使用
demo.py
import scrapy
class DemoSpider(scrapy.Spider):
name = "demo"
#allowed_domains = ["python123.io"]
start_urls = ['https://python123.io/ws/demo.html']
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname, 'wb') as f:
f.write(response.body)
self.log('Saved file %s.' % name)
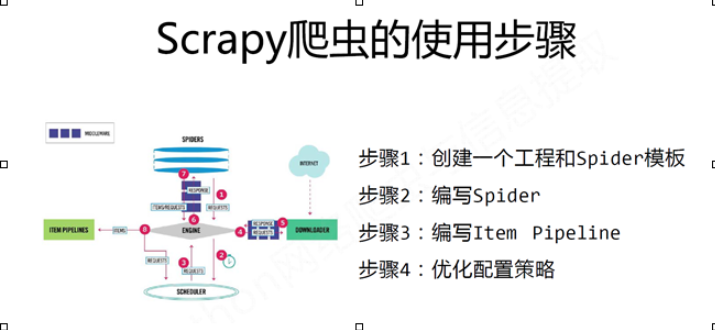
步骤1:建立一个Scrapy爬虫工程 scrapy startproject python123demo
步骤2:在工程中产生一个Scrapy爬虫
进入demo目录中运行 scrapy genspider dem python123.io
该命令作用:
(1) 生成一个名称为demo的spider
(2) 在spiders目录下增加代码文件demo.py
该命令仅用于生成demo.py,该文件也可以手工生成
步骤3:配置产生的spider爬虫
配置:(1)初始URL地址(2)获取页面后的解析方式
步骤4:运行爬虫,获取网页
在命令行下,执行如下命令:scrapy crawl demo
demo爬虫被执行,捕获页面存储在demo.html
yield 生成器
包含yield语句的函数是一个生成器
生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值
生成器是一个不断产生值的函数
生成器每调用一次在yield位置产生一个值,直到函数执行结束
Scrapy爬虫的数据类型:
Request类 class scrapy.http.Request() Request对象表示一个HTTP请求 由Spider生成,由Downloader执行
.url Request对应的请求URL地址
.method 对应的请求方法,’GET’ ‘POST’等
.headers 字典类型风格的请求头
.body 请求内容主体,字符串类型
.meta 用户添加的扩展信息,在Scrapy内部模块间传递信息使用
.copy() 复制该请求
Response类 class scrapy.http.Response() Response对象表示一个HTTP响应 由Downloader生成,由Spider处理
.url Response对应的URL地址
.status HTTP状态码,默认是200
.headers Response对应的头部信息
.body Response对应的内容信息,字符串类型
.flags 一组标记
.request 产生Response类型对应的Request对象
.copy() 复制该响应
Item类class scrapy.item.Item()
Item对象表示一个从HTML页面中提取的信息内容
由Spider生成,由Item Pipeline处理
Item类似字典类型,可以按照字典类型操作
Scrapy爬虫支持多种HTML信息提取方法:
• Beautiful Soup
• lxml
• re
• XPath Selector
• CSS Selector
5.3 股票数据爬虫scrapy实例
scrapy startproject BaiduStocks
scrapy genspider stocks baidu.com
stocks.py文件源代码
# -*- coding: utf-8 -*-
import scrapy
import re class StocksSpider(scrapy.Spider):
name = "stocks"
start_urls = ['https://quote.eastmoney.com/stocklist.html'] def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"[s][hz]\d{6}", href)[0]
url = 'https://gupiao.baidu.com/stock/' + stock + '.html'
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue def parse_stock(self, response):
infoDict = {}
stockInfo = response.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dt').extract()
valueList = stockInfo.css('dd').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*', keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*', valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key]=val infoDict.update(
{'股票名称': re.findall('\s.*\(',name)[0].split()[0] + \
re.findall('\>.*\<', name)[0][1:-1]})
yield infoDict
下面是pipelines.py文件源代码:
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class BaidustocksPipeline(object):
def process_item(self, item, spider):
return item class BaidustocksInfoPipeline(object):
def open_spider(self, spider):
self.f = open('BaiduStockInfo.txt', 'w') def close_spider(self, spider):
self.f.close() def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
下面是settings.py文件中被修改的区域:
# Configure item pipelines
# See https://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300,
}
【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)的更多相关文章
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容
python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容 Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖 ...
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- Python网络爬虫与信息提取(一)
学习 北京理工大学 嵩天 课程笔记 课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解 ...
- Python网络爬虫与信息提取[request库的应用](单元一)
---恢复内容开始--- 注:学习中国大学mooc 嵩天课程 的学习笔记 request的七个主要方法 request.request() 构造一个请求用以支撑其他基本方法 request.get(u ...
随机推荐
- 怎么在虚拟机下的Linux系统安装数据库
1.查看 linux下是否有老版本的mysql(有删除) 查找old mysql:rpm -qa | grep mysql 卸载:卸载命令:rpm –ev {包名}——:rpm -ev mysql-c ...
- 处理海量数据的grep、cut、awk、sed 命令
grep.cut.awk.sed 常常应用在查找日志.数据.输出结果等等,并对我们想要的数据进行提取. 通常grep,sed命令是对行进行提取,cut跟awk是对列进行提取 处理海量数据之grep命令 ...
- LG2766 最长不下降子序列问题 最大流 网络流24题
问题描述 LG2766 题解 \(\mathrm{Subtask 1}\) 一个求最长不下降子序列的问题,发现\(n \le 500\),直接\(O(n^2)\)暴力DP即可. \(\mathrm{S ...
- 树莓派autossh反向隧道
本来我是将树莓派连接到路由器,从而在电脑端通过IP访问.远在局域网之外的队友怎么访问呢? ssh反向隧道 它的原理比较简单: 树莓派主动向某公网服务器建立ssh连接,并请求公网服务器开启一个额外的SS ...
- Linux性能优化实战学习笔记:第六讲
一.环境准备 1.安装软件包 终端1 机器配置:2 CPU,8GB 内存 预先安装 docker.sysstat.perf等工具 [root@luoahong ~]# docker -v Docker ...
- Linux性能优化实战学习笔记:第三十五讲
一.上节回顾 前面内容,我们学习了 Linux 网络的基础原理以及性能观测方法.简单回顾一下,Linux网络基于 TCP/IP 模型,构建了其网络协议栈,把繁杂的网络功能划分为应用层.传输层.网络层. ...
- Linux性能优化实战学习笔记:第五十三讲
一.上节回顾 在前面的内容中,我为你介绍了很多性能分析的原理.思路以及相关的工具.不过,在实际的性能分析中,一个很常见的现象是,明明发生了性能瓶颈,但当你登录到服务器中想要排查的时候,却发现瓶颈已经消 ...
- java 声明并初始化字符串变量
public class Sample { public static void main(String[] args) { String str = "Hello world"; ...
- NOI 2019 退役记
非常抱歉,因为不退役了,所以这篇退役记鸽了.
- k8s本地部署
k8s是什么 Kubernetes是容器集群管理系统,是一个开源的平台,可以实现容器集群的自动化部署.自动扩缩容.维护等功能. Kubernetes 具有如下特点: 便携性: 无论公有云.私有云.混合 ...