impala进阶
一、impala存储
1、文件类型
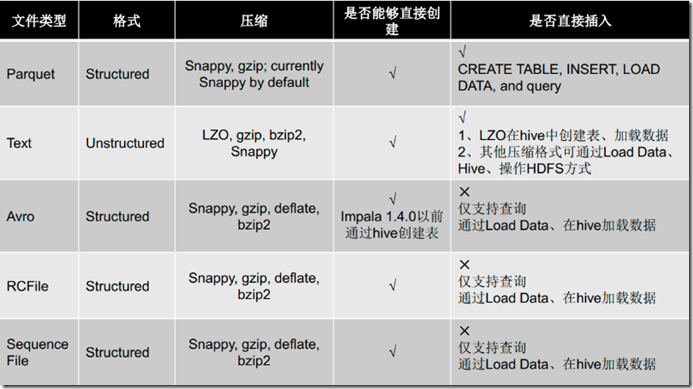
2、压缩方式

二、impala分区
1、创建分区方式
partitioned by 创建表时,添加该字段指定分区列表:
create table t_person(id int, name string, age int) partitioned by (type string); 使用alter table 进行分区的添加和删除操作:
alter table t_person add partition (sex=‘man');
alter table t_person drop partition (sex=‘man');
alter table t_person drop partition (sex=‘man‘,type=‘boss’);
2、分区内添加数据
insert into t_person partition (type='boss') values (1,’zhangsan’,18),(2,’lisi’,23)
insert into t_person partition (type='coder') values (3,wangwu’,22),(4,’zhaoliu’,28),(5,’tianqi’,24)
3、查询指定分区
select id,name from t_person where type=‘coder’
三、impala SQL
1、impala SQL与hive SQL对比
impala SQL支持的数据类型:
INT
TINYINT
SMALLINT
BIGINT
BOOLEAN
CHAR
VARCHAR
STRING
FLOAT
DOUBLE
REAL
DECIMAL
TIMESTAMP CDH5.5版本以后才支持一下类型:
ARRAY
MAP
STRUCT
Complex
Impala不支持HiveQL以下特性:
可扩展机制,例如:TRANSFORM、自定义文件格式、自定义SerDes – XML、JSON函数 – 某些聚合函数:
covar_pop, covar_samp, corr, percentile,percentile_approx, histogram_numeric, collect_set
Impala仅支持:AVG,COUNT,MAX,MIN,SUM – 多Distinct查询 – HDF、UDAF --以下语句:
ANALYZE TABLE (impala: COMPUTE STATS), DESCRIBE COLUMN, DESCRIBE DATABASE, EXPOR TABLE, IMPORT TABLE, SHOW TABLE EXTENDED,
SHOW INDEXES, SHOW COLUMNS.
impala SQL支持视图:
视图
– 创建视图:create view v1 as select count(id) as total from tab_3 ;
– 查询视图:select * from v1;
– 查看视图定义:describe formatted v1 注意:
不能向impala的视图进行插入操作
insert 表可以来自视图
2、数据导入
加载数据:
insert语句:插入数据时每条数据产生一个数据文件,不建议用此方式; load data方式:在进行批量插入时使用这种方式比较合适; 来自中间表:此种方式使用于从一个小文件较多的大表中读取文件并写入新的表生产少量的数据文件。也可以通过此种方式进行格式转换。
空值处理:
impala将“\n” 表示为NULL,在结合sqoop使用是注意做相应的空字段过滤, 也可以使用以下方式进行处理:
alter table name set tblproperties (“serialization.null.format” = “null”)
3、优化
查询sql执行之前,可以先对该sql做一个分析,列出需要完成这一项查询的详细方案(命令:explain) 1、SQL优化,使用之前调用执行计划
2、选择合适的文件格式进行存储
3、避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间表)
4、使用合适的分区技术,根据分区粒度测算
5、使用compute stats进行表信息搜集
6、网络io的优化:
a.避免把整个数据发送到客户端
b.尽可能的做条件过滤
c.使用limit字句
d.输出文件时,避免使用美化输出
7、使用profile输出底层信息计划,在做相应环境优化
四、impala与hbase整合
因为impala是基于hive的,和hive使用同样的元数据,hive与hbase整合以后,impala也就可以使用hbase了;
Impala可以通过Hive外部表方式和HBase进行整合,步骤如下: 步骤1:创建hbase表,向表中添加数据
create 'test info','info'
put 'test info','1','info:name','zhangsan'
put 'test info','2','info:name','lisi' 步骤2:创建hive表
CREATE EXTERNAL TABLE test_info(key string,name string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping"=":keyinfo:name")
TBLPROPERTIES
(hbase.table.name" = "test info"); 步骤3:刷新Impala表
invalidate metadata
五、impala与hive对比
1、Impala和Hive的关系
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数 据、ODBC/JDBC驱动、
SQL语法、灵活的文件格式、存储资源池等。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想
法的大数 据分析工具。
可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。 Impala与Hive在Hadoop中的关系如下图:
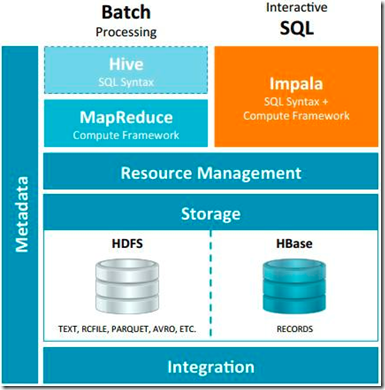
2、Impala相对于Hive所使用的优化技术
1、没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与 MapReduce相比:
Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取 数据的方式获取结果,把结果数据组成按执行树流式传
递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免 每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动
时间。
2、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
3、充分利用可用的硬件指令(SSE4.2)。
4、更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。
5、通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
6、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
3、Impala与Hive的异同
数据存储:使用相同的存储数据池都支持把数据存储于HDFS, HBase。
元数据:两者使用相同的元数据。
SQL解释处理:比较相似都是通过词法分析生成执行计划。 执行计划:
Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会 被编译成多轮MapReduce,则会有更多的写中间结
果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的 map->reduce模式,以此保
证Impala有更好的并发性和避免不必要的中间sort与shuffle。 数据流:
Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用
等到全部处理完成,更符合SQL交互式查询使用。 内存使用:
Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行
架构的特性,shuffle过程也会有写本地磁盘的操作。
Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一 定的限制,最好
还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)。 调度:
Hive: 任务调度依赖于Hadoop的调度策略。
Impala: 调度由自己完成,目前只有一种调度器simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。调度器 目前还比较简单
,在SimpleScheduler::GetBackend中可以看到,现在还没有考虑负载,网络IO状况等因素进行调度。但目前 Impala已经有对执行过程的性能统计分析,应该以后版本会利用
这些统计信息进行调度吧。 容错:
Hive: 依赖于Hadoop的容错能力。
Impala: 在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与Impala的设计有关,因为Impala定位于实时查询,一次查询失败, 再查一次就
好了,再查一次的成本很低)。但从整体来看,Impala是能很好的容错,所有的Impalad是对等的结构,用户可以向任何一个 Impalad提交查询,如果一个Impalad失效,其
上正在运行的所有Query都将失败,但用户可以重新提交查询由其它Impalad代替执行,不 会影响服务。对于State Store目前只有一个,但当State Store失效,也不会影响服
务,每个Impalad都缓存了State Store的信息,只是不能再更新集群状态,有可能会把执行任务分配给已经失效的Impalad执行,导致本次Query失败。 适用面:
Hive: 复杂的批处理查询任务,数据转换任务。
Impala:实时数据分析,因为不支持UDF,能处理的问题域有一定的限制,与Hive配合使用,对Hive的结果数据集进行实时分析。
4、impala的优缺点
优点:
支持SQL查询,快速查询大数据。
可以对已有数据进行查询,减少数据的加载,转换。
多种存储格式可以选择(Parquet, Text, Avro, RCFile, SequeenceFile)。
可以与Hive配合使用。 缺点:
不支持用户定义函数UDF。
不支持text域的全文搜索。
不支持Transforms。
不支持查询期的容错。
对内存要求高。
impala进阶的更多相关文章
- nodejs进阶(6)—连接MySQL数据库
1. 建库连库 连接MySQL数据库需要安装支持 npm install mysql 我们需要提前安装按mysql sever端 建一个数据库mydb1 mysql> CREATE DATABA ...
- nodejs进阶(4)—读取图片到页面
我们先实现从指定路径读取图片然后输出到页面的功能. 先准备一张图片imgs/dog.jpg. file.js里面继续添加readImg方法,在这里注意读写的时候都需要声明'binary'.(file. ...
- JavaScript进阶之路(一)初学者的开始
一:写在前面的问题和话 一个javascript初学者的进阶之路! 背景:3年后端(ASP.NET)工作经验,javascript水平一般般,前端水平一般般.学习资料:犀牛书. 如有误导,或者错误的地 ...
- nodejs进阶(3)—路由处理
1. url.parse(url)解析 该方法将一个URL字符串转换成对象并返回. url.parse(urlStr, [parseQueryString], [slashesDenoteHost]) ...
- nodejs进阶(5)—接收请求参数
1. get请求参数接收 我们简单举一个需要接收参数的例子 如果有个查找功能,查找关键词需要从url里接收,http://localhost:8000/search?keyword=地球.通过前面的进 ...
- nodejs进阶(1)—输出hello world
下面将带领大家一步步学习nodejs,知道怎么使用nodejs搭建服务器,响应get/post请求,连接数据库等. 搭建服务器页面输出hello world var http = require ...
- [C#] 进阶 - LINQ 标准查询操作概述
LINQ 标准查询操作概述 序 “标准查询运算符”是组成语言集成查询 (LINQ) 模式的方法.大多数这些方法都在序列上运行,其中的序列是一个对象,其类型实现了IEnumerable<T> ...
- Java 进阶 hello world! - 中级程序员之路
Java 进阶 hello world! - 中级程序员之路 Java是一种跨平台的语言,号称:"一次编写,到处运行",在世界编程语言排行榜中稳居第二名(TIOBE index). ...
- C#进阶系列——WebApi 接口返回值不困惑:返回值类型详解
前言:已经有一个月没写点什么了,感觉心里空落落的.今天再来篇干货,想要学习Webapi的园友们速速动起来,跟着博主一起来学习吧.之前分享过一篇 C#进阶系列——WebApi接口传参不再困惑:传参详解 ...
随机推荐
- k8s web终端连接工具
k8 web terminal 一个k8s web终端连接工具,在前后端分离或未分离项目中心中,也可以把此项目无缝集成,开箱即用. 项目地址:https://github.com/jcops/k8-w ...
- 《一起学netty》
o文章摘自 netty 官网(netty.io) netty 是一个异步的,事件驱动的网络应用通信框架,可以让我们快速编写可靠,高性能,高可扩展的服务端和客户端 样例一:discard ser ...
- LeetCode 622:设计循环队列 Design Circular Queue
LeetCode 622:设计循环队列 Design Circular Queue 首先来看看队列这种数据结构: 队列:先入先出的数据结构 在 FIFO 数据结构中,将首先处理添加到队列中的第一个元素 ...
- 用 PHP 函数变量数组改变代码结构
项目越做越大,代码越来越乱,维护困难.原因很多吧.起初为了实现功能,并没有注重代码的结构,外包公司嘛.虽然公司的项目负责人一直考虑复用.封装,但是我觉得基本上没有达到想要的效果.因为整个代码中没有用到 ...
- Entity Framework Core 练习参考
项目地址:https://gitee.com/dhclly/IceDog.EFCore 项目介绍 对 Microsoft EntityFramework Core 框架的练习测试 参考文档教程 官方文 ...
- docker安装kafka
文本摘自此文章 .kafka需要zookeeper管理,所以需要先安装zookeeper. 下载zookeeper镜像 $ docker pull wurstmeister/zookeeper .启动 ...
- kali渗透综合靶机(十七)--HackInOS靶机
kali渗透综合靶机(十七)--HackInOS靶机 靶机下载地址:https://www.vulnhub.com/hackinos/HackInOS.ova 一.主机发现 1.netdiscover ...
- 从VisualStudio资源文件看.NET资源处理
c# 工程里面,经常会添加资源文件. 作用: 一处文本多个地方的UI使用,最好把文本抽成资源,多处调用使用一处资源. 多语言版本支持,一份代码支持多国语言.配置多国语言的资源文件,调用处引用资源. 例 ...
- kuangbin专题简单搜索题目几道题目
1.POJ1321棋盘问题 Description 在一个给定形状的棋盘(形状可能是不规则的)上面摆放棋子,棋子没有区别.要求摆放时任意的两个棋子不能放在棋盘中的同一行或者同一列,请编程求解对于给定形 ...
- css中的baseline
这是css中的一个容易被人忽略的概念,今天在知乎上看到一个问题,这个问题应该是关于baseline,才去补习了一下关于baseline的知识,首先我来还原一下问题: <div style=&qu ...