python爬虫-豆瓣电影的尝试
一、背景介绍
1. 使用工具
Pycharm
2. 安装的第三方库
requests、BeautifulSoup
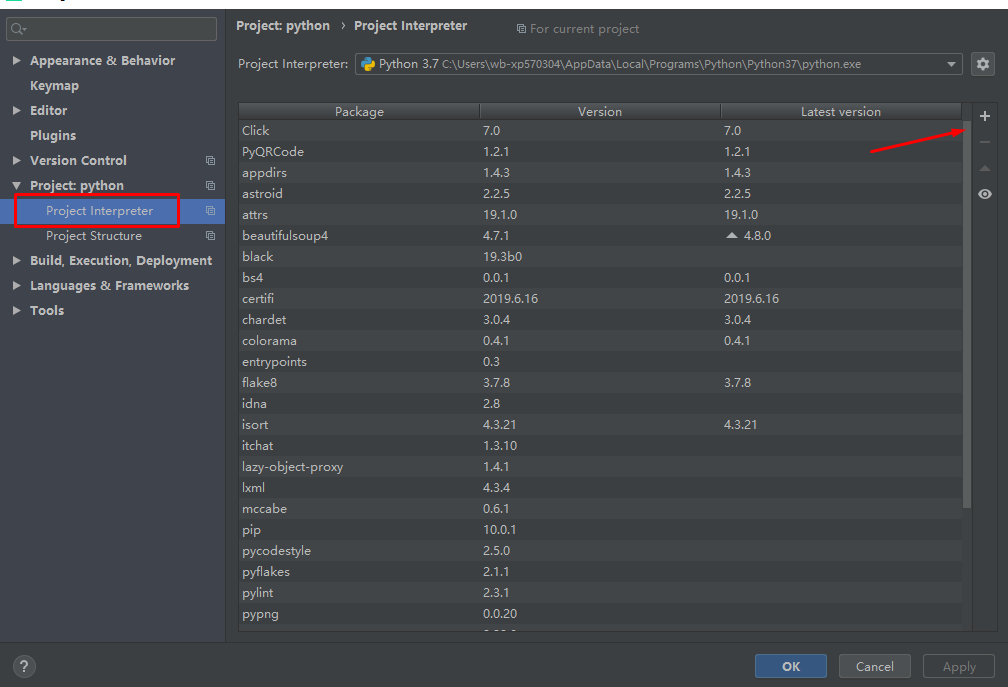
2.1 如何安装第三方库
File => Settings => Project Interpreter => + 中搜索你需要的插件
3. 可掌握的小知识
1. 根据url 获取页面html内容
2. 解析html内容,选出自己需要的内容
二、代码示例
网页的样子是这个,获取排行榜中电影的名字
import requests
from bs4 import BeautifulSoup def getHtml():
url = 'https://movie.douban.com/chart'
# Get获取改页面的内容
html = requests.get(url)
# 用lxml解析器解析该页面的内容
soup = BeautifulSoup(html.content, "lxml")
getFilmName(soup)
# print(soup) def getFilmName(html):
for i in html.find_all('a', class_="nbg"):
img = i.find('img')
print(img['alt']) getHtml() 返回值:
恶人传
孟买酒店
阿丽塔:战斗天使
雷霆沙赞!
夏目友人帐
地久天长
调音师
三夫
寄生虫
地狱男爵:血皇后崛起
三、结语
先从简单的入手,帮助自己,也希望能帮助未入门的同学
python爬虫-豆瓣电影的尝试的更多相关文章
- Python爬虫-豆瓣电影 Top 250
爬取的网页地址为:https://movie.douban.com/top250 打开网页后,可观察到:TOP250的电影被分成了10个页面来展示,每个页面有25个电影. 那么要爬取所有电影的信息,就 ...
- python爬虫: 豆瓣电影top250数据分析
转载博客 https://segmentfault.com/a/1190000005920679 根据自己的环境修改并配置mysql数据库 系统:Mac OS X 10.11 python 2.7 m ...
- 放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~)
放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wa ...
- python pandas 豆瓣电影 top250 数据分析
豆瓣电影top250数据分析 数据来源(豆瓣电影top250) 爬虫代码比较简单 数据较为真实,可以进行初步的数据分析 可以将前面的几篇文章中的介绍的数据预处理的方法进行实践 最后用matplotli ...
- [Python]从豆瓣电影批量获取看过这部电影的用户列表
前言 由于之后要做一个实验,需要用到大量豆瓣用户的电影数据,因此想到了从豆瓣电影的“看过这部电影 的豆瓣成员”页面上来获取较为活跃的豆瓣电影用户. 链接分析 这是看过"模仿游戏"的 ...
- python 爬虫豆瓣top250
网页api:https://movie.douban.com/top250?start=0&filter= 用到的模块:urllib,re,csv 捣鼓一上午终于好了,有些小问题 (top21 ...
- python爬虫---豆瓣Top250电影采集
代码: import requests from bs4 import BeautifulSoup as bs import time def get_movie(url): headers = { ...
- [Python]计算豆瓣电影TOP250的平均得分
用python写的爬虫练习,感觉比golang要好写一点. import re import urllib origin_url = 'https://movie.douban.com/top250? ...
- Python 爬虫-豆瓣读书
import requests from bs4 import BeautifulSoup def parse_html(num): headers = { 'User-Agent': 'Mozill ...
随机推荐
- Java枚举类接口实战
枚举类可以实现一个或多个接口.与普通类实现接口完全一样,枚举类实现接口时,需要实现该接口所包含的方法. 如果需要每个枚举值在调用同一个方法时呈现不同的行为,则可以让每个枚举值在{...}匿名块中实现自 ...
- [luogu 4719][模板]动态dp
传送门 Solution \(f_{i,0}\) 表示以i节点为根的子树内,不选i号节点的最大独立集 \(f_{i,1}\)表示以i节点为根的子树内,选i号节点的最大独立集 \(g_{i,0}\) 表 ...
- com.ibm.db2.jcc.am.SqlSyntaxErrorException: DB2 SQL Error: SQLCODE=-418, SQLSTATE=42610, SQLERRMC=null
写了一条sql,在db2数据库中可以执行,但是转换成mybatis的mapper文件后,在执行排序操作时报该错误. 我排序是这样写的 <if test="orderStr != nul ...
- js-关于异步原理的理解和总结
我们经常说JS是单线程的,比如Node.js研讨会上大家都说JS的特色之一是单线程的,这样使JS更简单明了,可是大家真的理解所谓JS的单线程机制吗?单线程时,基于事件的异步机制又该当如何,这些知识在& ...
- laravel修改了配置文件不生效,修改了数据库配置文件不生效
Laravel缓存配置文件,因此您可能只需要清除缓存: php artisan config:clear 转: http://www.voidcn.com/article/p-sgcusrjp-bxw ...
- ByteBuffer: 图解ByteBuffer(转)
ByteBuffer前前后后看过好几次了,实际使用也用了一些,总觉得条理不够清晰. <程序员的思维修炼>一本书讲过,主动学习,要比单纯看资料效果来的好,所以干脆写个详细点的文章来记录一下. ...
- Flutter ------- WebView加载网页
在Flutter 加载网页?也是有WebView的哦,和Android一样 1.添加依赖 dependencies: flutter_webview_plugin: ^0.2.1+2 2.导入库 im ...
- 目标检测标注工具labelImg安装及使用
目标检测中,原始图片的标注过程是非常重要的,它的作用是在原始图像中标注目标物体位置并对每张图片生成相应的xml文件表示目标标准框的位置.本文介绍一款使用方便且能够标注多类别并能直接生成xml文件的标注 ...
- 八、postman的cookie支持
postman中可以直接添加cookie,查看响应中的cookie https://postman-echo.com/cookies/set?foo1=bar1&foo2=bar2 var r ...
- Navigator的使用:
1.路由直接跳转到下一个页面: Navigator.pushNamed(context,"/login"); 2.跳转的下一个页面,替换当前的页面: Navigator.of(co ...