29、Java虚拟机垃圾回收调优
一、背景
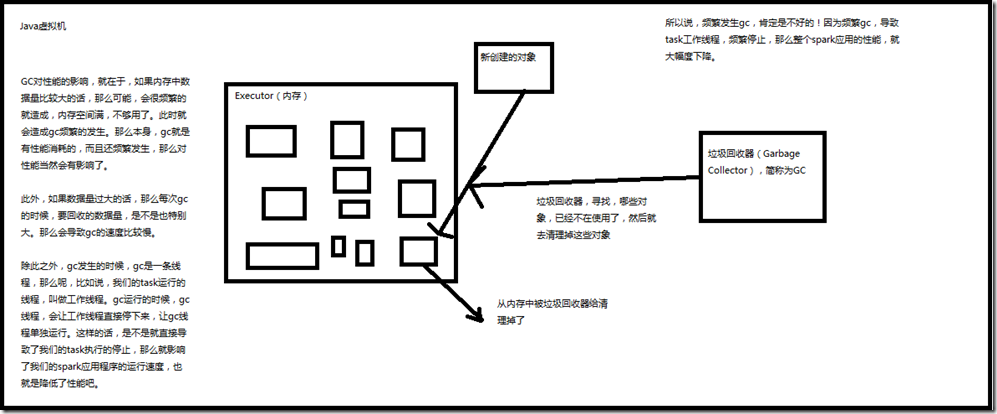
如果在持久化RDD的时候,持久化了大量的数据,那么Java虚拟机的垃圾回收就可能成为一个性能瓶颈。因为Java虚拟机会定期进行垃圾回收,此时就会追踪所有的java对象,
并且在垃圾回收时,找到那些已经不在使用的对象,然后清理旧的对象,来给新的对象腾出内存空间。 垃圾回收的性能开销,是跟内存中的对象的数量,成正比的。所以,对于垃圾回收的性能问题,首先要做的就是,使用更高效的数据结构,比如array和string;其次就是在持久化rdd时,
使用序列化的持久化级别,而且用Kryo序列化类库,这样,每个partition就只是一个对象——一个字节数组。
二、监测垃圾回收
我们可以对垃圾回收进行监测,包括多久进行一次垃圾回收,以及每次垃圾回收耗费的时间。只要在spark-submit脚本中,增加一个配置即可,
--conf "spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"。 但是要记住,这里虽然会打印出Java虚拟机的垃圾回收的相关信息,但是是输出到了worker上的日志中,而不是driver的日志中。 但是这种方式也只是一种,其实也完全可以通过SparkUI(4040端口)来观察每个stage的垃圾回收的情况。
三、优化executor内存比例
1、图解
2、说明
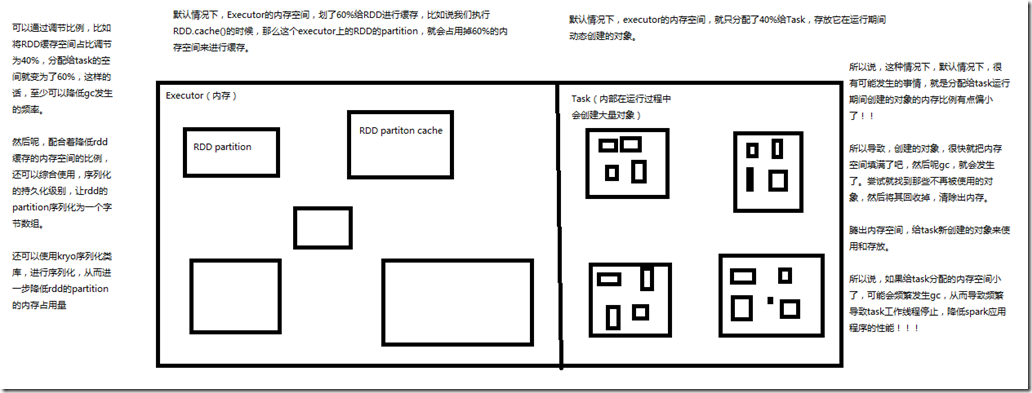
对于垃圾回收来说,最重要的就是调节RDD缓存占用的内存空间,与算子执行时创建的对象占用的内存空间的比例。默认情况下,Spark使用每个executor 60%的内存空间来缓存RDD,
那么在task执行期间创建的对象,只有40%的内存空间来存放。 在这种情况下,很有可能因为你的内存空间的不足,task创建的对象过大,那么一旦发现40%的内存空间不够用了,就会触发Java虚拟机的垃圾回收操作。因此在极端情况下,
垃圾回收操作可能会被频繁触发。 在上述情况下,如果发现垃圾回收频繁发生。那么就需要对那个比例进行调优,使用new SparkConf().set("spark.storage.memoryFraction", "0.5")即可,可以将RDD缓存占用空间的比例降低,
从而给更多的空间让task创建的对象进行使用。 因此,对于RDD持久化,完全可以使用Kryo序列化,加上降低其executor内存占比的方式,来减少其内存消耗。给task提供更多的内存,从而避免task的执行频繁触发垃圾回收。
四、高级的垃圾回收调优
1、图解
2、说明
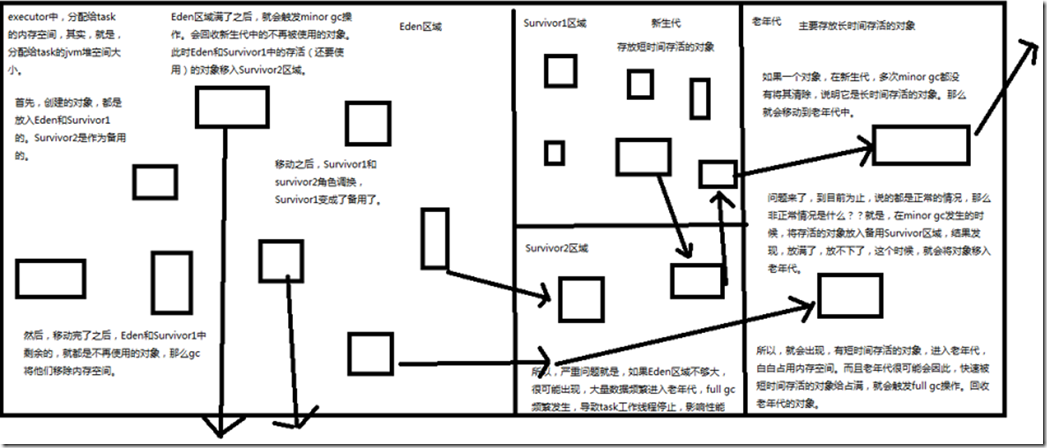
Java堆空间被划分成了两块空间,一个是年轻代,一个是老年代。年轻代放的是短时间存活的对象,老年代放的是长时间存活的对象。年轻代又被划分了三块空间,Eden、Survivor1、Survivor2。 首先,Eden区域和Survivor1区域用于存放对象,Survivor2区域备用。创建的对象,首先放入Eden区域和Survivor1区域,如果Eden区域满了,那么就会触发一次Minor GC,
进行年轻代的垃圾回收。Eden和Survivor1区域中存活的对象,会被移动到Survivor2区域中。然后Survivor1和Survivor2的角色调换,Survivor1变成了备用。 如果一个对象,在年轻代中,撑过了多次垃圾回收,都没有被回收掉,那么会被认为是长时间存活的,此时就会被移入老年代。此外,如果在将Eden和Survivor1中的存活对象,
尝试放入Survivor2中时,发现Survivor2放满了,那么会直接放入老年代。此时就出现了,短时间存活的对象,进入老年代的问题。 如果老年代的空间满了,那么就会触发Full GC,进行老年代的垃圾回收操作。 Spark中,垃圾回收调优的目标就是,只有真正长时间存活的对象,才能进入老年代,短时间存活的对象,只能呆在年轻代。不能因为某个Survivor区域空间不够,
在Minor GC时,就进入了老年代。从而造成短时间存活的对象,长期呆在老年代中占据了空间,而且Full GC时要回收大量的短时间存活的对象,导致Full GC速度缓慢。 如果发现,在task执行期间,大量full gc发生了,那么说明,年轻代的Eden区域,给的空间不够大。此时可以执行一些操作来优化垃圾回收行为:
1、包括降低spark.storage.memoryFraction的比例,给年轻代更多的空间,来存放短时间存活的对象;
2、给Eden区域分配更大的空间,使用-Xmn即可,通常建议给Eden区域,预计大小的4/3;
3、如果使用的是HDFS文件,那么很好估计Eden区域大小,如果每个executor有4个task,然后每个hdfs压缩块解压缩后大小是3倍,此外每个hdfs块的大小是64M,
那么Eden区域的预计大小就是:4 * 3 * 64MB,然后呢,再通过-Xmn参数,将Eden区域大小设置为4 * 3 * 64 * 4/3。 ##总结
其实啊,根据经验来看,对于垃圾回收的调优,尽量就是说,调节executor内存的比例就可以了。因为jvm的调优是非常复杂和敏感的。除非是,真的到了万不得已的地方,
然后呢,自己本身又对jvm相关的技术很了解,那么此时进行eden区域的调节,调优,是可以的。 一些高级的参数
-XX:SurvivorRatio=4:如果值为4,那么就是两个Survivor跟Eden的比例是2:4,也就是说每个Survivor占据的年轻代的比例是1/6,所以,你其实也可以尝试调大Survivor区域的大小。
-XX:NewRatio=4:调节新生代和老年代的比例
29、Java虚拟机垃圾回收调优的更多相关文章
- java 内存 垃圾回收调优
要了解Java垃圾收集机制,先理解JVM内存模式是非常重要的.今天我们将会了解JVM内存的各个部分.如何监控以及垃圾收集调优. Java(JVM)内存模型 正如你从上面的图片看到的,JVM内存被分成多 ...
- 【译】Java SE 14 Hotspot 虚拟机垃圾回收调优指南
原文链接:HotSpot Virtual Machine Garbage Collection Tuning Guide,基于Java SE 14. 本文主要包括以下内容: 优化目标与策略(Ergon ...
- spark性能优化-JVM虚拟机垃圾回收调优
1 2 3 4
- Java虚拟机垃圾回收:内存分配与回收策略 方法区垃圾回收 以及 JVM垃圾回收的调优方法
在<Java对象在Java虚拟机中的创建过程>了解到对象创建的内存分配,在<Java内存区域 JVM运行时数据区>中了解到各数据区有些什么特点.以及相关参数的调整,在<J ...
- ☕【JVM技术指南】「JVM总结笔记」Java虚拟机垃圾回收认知和调优的"思南(司南)"【下部】
承接上文 (完结撒花1-52系列)[JVM技术指南]「JVM总结笔记」Java虚拟机垃圾回收认知和调优的"思南(司南)"[上部] 并行收集器 并行收集器(也称为吞吐量收集器)是类似 ...
- Java内存与垃圾回收调优
Java(JVM)内存模型 正如你从上面的图片看到的,JVM内存被分成多个独立的部分.广泛地说,JVM堆内存被分为两部分——年轻代(Young Generation)和老年代(Old Generat ...
- 【转】Java内存与垃圾回收调优
要了解Java垃圾收集机制,先理解JVM内存模式是非常重要的.今天我们将会了解JVM内存的各个部分.如何监控以及垃圾收集调优. Java(JVM)内存模型 正如你从上面的图片看到的,JVM内存被分成多 ...
- Java虚拟机垃圾回收(三) 7种垃圾收集器
Java虚拟机垃圾回收(三) 7种垃圾收集器 主要特点 应用场景 设置参数 基本运行原理 在<Java虚拟机垃圾回收(一) 基础>中了解到如何判断对象是存活还是已经死亡?在<Java ...
- Java虚拟机垃圾回收(三): 7种垃圾收集器(转载)
1.垃圾收集器概述 垃圾收集器是垃圾回收算法(标记-清除算法.复制算法.标记-整理算法.火车算法)的具体实现,不同商家.不同版本的JVM所提供的垃圾收集器可能会有很在差别,本文主要介绍HotSpot虚 ...
随机推荐
- attr()与prop()区分图
- Flutter Image(图片)
Image是一个用于展示图片的组件.支持 JPEG.PNG.GIF.Animated GIF.WebP.Animated WebP.BMP 和 WBMP 等格式. Image 有许多的静态函数: ne ...
- 从MVC -> MVVM ? 开发模式
MVVM 到底是什么? view :由 MVC 中的 view 和 controller 组成,负责 UI 的展示,绑定 viewModel 中的属性,触发 viewModel 中的命令: viewM ...
- Delphi对于文件的读写操作
delphi文件操作 取文件名 ExtractFileName(FileName); 取文件扩展名: ExtractFileExt(filename); 取文件名,不带扩展名: 方法一: Functi ...
- 全局唯一ID生成器(Snowflake ID组成) 分析
Snowflake ID组成 Snowflake ID有64bits长,由以下三部分组成: time—42bits,精确到ms,那就意味着其可以表示长达(2^42-1)/(1000360024*365 ...
- curl-手册
Manual -- curl usage explained Related: Man Page FAQ LATEST VERSION You always find news about wha ...
- zabbix Server 4.0 监控JMX监控详解
zabbix Server 4.0 监控JMX监控详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 大家都知道,zabbix server效率高是使用C语言编写的,有很多应用 ...
- 本地安装部署Jira
https://blog.csdn.net/u013492736/article/details/83315650 1. 首先在官网下自行搭建服务器的版本,有适合于windows的,也有linux版本 ...
- abp学习(四)——根据入门教程(aspnetMVC Web API进一步学习)
Introduction With AspNet MVC Web API EntityFramework and AngularJS 地址:https://aspnetboilerplate.com/ ...
- python安装脚本
[root@dn3 hadoop]# cat install.py #!/usr/bin/python #coding=utf- import os import sys : pass else: p ...