66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一、数据处理原理剖析
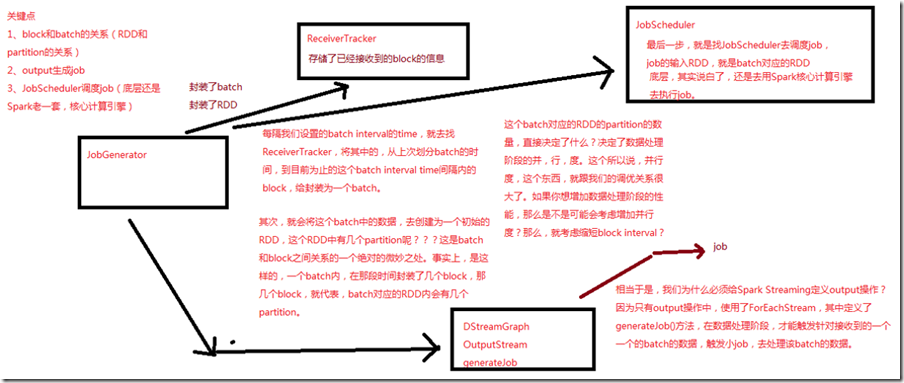
每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval time间隔内的block封装为一个batch; 其次,会将这个batch中的数据,去创建为一个初始的RDD,一个batch内,在这段时间封装了几个block,就代表这个batch对应的RDD内会有几个partition; 这个batch对应的RDD的partition决定了数据处理阶段的并行度,这个跟调优关系很大,如果想增加数据处理阶段的性能,就考虑增加并行度,那么就考虑缩短block interval; 只有output操作中,使用了ForEachStream,其中定义了generatorJob()方法,在数据处理阶段,才触发针对接收到的一个一个batch的数据,触发小的job,去处理该batch的数据; 最后一步,去找JobScheduler去调度job,job的输入RDD,就是batch对应的RDD;
二、源码分析
入口,JobGenerator的generateJobs()方法
###org.apache.spark.streaming.scheduler/JobGenerator.scala /**
* 定时,调度generateJobs()方法,传入一个time,其实就是一个batch interval内的时间段
*/
private def generateJobs(time: Time) {
// Set the SparkEnv in this thread, so that job generation code can access the environment
// Example: BlockRDDs are created in this thread, and it needs to access BlockManager
// Update: This is probably redundant after threadlocal stuff in SparkEnv has been removed.
SparkEnv.set(ssc.env)
Try {
// 找到ReceiverTracker,调用其allocateBlocksToBatch方法,将当前时间段内的block分配给一个batch,并为其
// 创建一个RDD
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
// 调用DSteamGraph的generateJobs()来根据程序定义的DSteam之间的依赖关系和算子,生成job
graph.generateJobs(time) // generate jobs using allocated block
} match {
// 如果成功创建了job
case Success(jobs) =>
// 从ReceiverTracker中,获取当前batch interval对应的block数据
val receivedBlockInfos =
jobScheduler.receiverTracker.getBlocksOfBatch(time).mapValues { _.toArray }
// 用jobScheduler提交job,其对应的原始数据,是那批block
jobScheduler.submitJobSet(JobSet(time, jobs, receivedBlockInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
eventActor ! DoCheckpoint(time)
}
66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)的更多相关文章
- 65、Spark Streaming:数据接收原理剖析与源码分析
一.数据接收原理 二.源码分析 入口包org.apache.spark.streaming.receiver下ReceiverSupervisorImpl类的onStart()方法 ### overr ...
- 64、Spark Streaming:StreamingContext初始化与Receiver启动原理剖析与源码分析
一.StreamingContext源码分析 ###入口 org.apache.spark.streaming/StreamingContext.scala /** * 在创建和完成StreamCon ...
- 18、TaskScheduler原理剖析与源码分析
一.源码分析 ###入口 ###org.apache.spark.scheduler/DAGScheduler.scala // 最后,针对stage的task,创建TaskSet对象,调用taskS ...
- 22、BlockManager原理剖析与源码分析
一.原理 1.图解 Driver上,有BlockManagerMaster,它的功能,就是负责对各个节点上的BlockManager内部管理的数据的元数据进行维护, 比如Block的增删改等操作,都会 ...
- 21、Shuffle原理剖析与源码分析
一.普通shuffle原理 1.图解 假设有一个节点上面运行了4个 ShuffleMapTask,然后这个节点上只有2个 cpu core.假如有另外一台节点,上面也运行了4个ResultTask,现 ...
- 20、Task原理剖析与源码分析
一.Task原理 1.图解 二.源码分析 1. ###org.apache.spark.executor/Executor.scala /** * 从TaskRunner开始,来看Task的运行的工作 ...
- 19、Executor原理剖析与源码分析
一.原理图解 二.源码分析 1.Executor注册机制 worker中为Application启动的executor,实际上是启动了这个CoarseGrainedExecutorBackend进程: ...
- 23、CacheManager原理剖析与源码分析
一.图解 二.源码分析 ###org.apache.spark.rdd/RDD.scalal ###入口 final def iterator(split: Partition, context: T ...
- 16、job触发流程原理剖析与源码分析
一.以Wordcount为例来分析 1.Wordcount val lines = sc.textFile() val words = lines.flatMap(line => line.sp ...
随机推荐
- Redis cluster的核心原理分析
一.节点间的内部通信机制 1.基础通信原理 (1)redis cluster节点间采取gossip协议进行通信 跟集中式不同,不是将集群元数据(节点信息,故障,等等)集中存储在某个节点上,而是互相之间 ...
- 用C#做一个 拉流播放器
做拉流播放器第一个想到就是,.,..FFmpeg没错 我也是用强大的他它来做的.但是我用的不是 cmd 调用 而是用的强大的FFmpeg.AutoGen FFmpeg.AutoGen 这个是C# 一 ...
- ssm框架 pom的配置 / 还有里面springMVC.xml的配置 / webapp.xml的配置
首先是pom的配置: <dependencies> <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-jav ...
- docker容器的使用整理
2019/10/24, docker 19.03.4 摘要:docker容器常用命令整理 gitbooks文档 docker脚本安装 使用官方脚本安装docker,从阿里云下载: curl -fsSL ...
- Java自学-操作符 位操作符
Java的位操作符 位操作符 在实际工作中使用并不常见. 示例 1 : 一个整数的二进制表达 位操作都是对二进制而言的,但是我们平常使用的都是十进制比如5. 而5的二进制是101. 所以在开始学习之前 ...
- 【转载】C#中使用decimal.TryParse方法将字符串转换为十进制decimal类型
在C#编程过程中,将字符串string转换为decimal类型过程中,时常使用decimal.Parse方法,但decimal.Parse在无法转换的时候,会抛出程序异常,其实还有个decimal.T ...
- vue从零开始(三)指令
v-bind的使用 <!-- 绑定一个属性 --> <img v-bind:src="imageSrc"> <!-- 动态特性名 (2.6.0+) - ...
- Mac音频播放
Mac音频播放 audioqueue播放pcm数据 http://msching.github.io/blog/2014/08/02/audio-in-ios-5/ audiounit播放pcm数据 ...
- 复盘一篇浅谈KNN的文章
认识-什么是KNN KNN 即 K-nearest neighbors, 是一个hello world级别, 但被广泛使用的机器学习算法, 中文叫K近邻算法, 是一种基本的分类和回归方法. KNN既可 ...
- Linux LVM 逻辑卷管理
使用Linux好久了,一定会意识到一个问题,某个分区容量不够用了,想要扩容怎么办?这里就涉及到LVM逻辑卷的管理了,可以动态调整Linux分区容量. LVM 概述 全称Logical Volume M ...