Hadoop(二)—— HDFS
HDFS(Hadoop Distributed File System)Hadoop分布式文件系统。
一、HDFS产生的背景
随着数据量越来越大,如果大到一台主机的磁盘都存放不下,该如何解决这个问题。一种思路是将数据分片放到多台主机上。如果放到多台主机上,又该怎么去管理,如果有些主机宕机了,数据丢失了该如何解决?
这时,就需要一种系统去解决上述问题,来更好地管理多台主机上的数据文件,这种系统就是分布式文件管理系统。
二、HDFS的特点
(1)流式访问数据
一次写入,多次读取。也就是一条数据插入,会复制分发到不同的节点。对应的理解就是,来一点,处理一点。
非流式的话,就会累积到一定程度,再去复制分发。对应的理解就是,来一点懒得处理,来一堆,再去处理。
(2)运行在廉价的商业机器上
HDFS对硬件的要求小。
(3)适合存储大文件,不适合存储大量小文件
适合处理几百MB、几百TB量级的数据。
HDFS已经可以支持PB级的数据存储。
(4)不适合低延迟要求的数据访问
HDFS的定位是面向大规模数据的数据分析和存储的,关注点是数据的吞吐量。
不能满足低延迟的要求,作为达到低延迟效果的补充方案是,使用HBase。
三、HDFS一些概念
块
HDFS中的文件是以块的形式进行存储。在Hadoop 2.x版本中数据块的默认大小是128MB,老版本中是64MB。
为什么要使用128MB作为默认值?
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。
如果寻址时间约为10ms,传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。默认的块大小实际为128MB。 —— 《Hadoop权威指南》
磁盘设置太小,会增加寻址时间,块设置得太大,每个块数据传输的时间会增加,导致程序处理数据,会非常慢。
HDFS块的大小设置主要取决于磁盘传输速率,如果是SSD,可以考虑将块大小设置为256MB。
使用块的好处是:
- 单个文件的大小,可以超过HDFS集群中单个节点磁盘的大小,单个节点只存储这个文件的部分块。
- 提高容错性,每个块都有副本,若一个块丢失、损坏,系统可以读取副本中的数据。
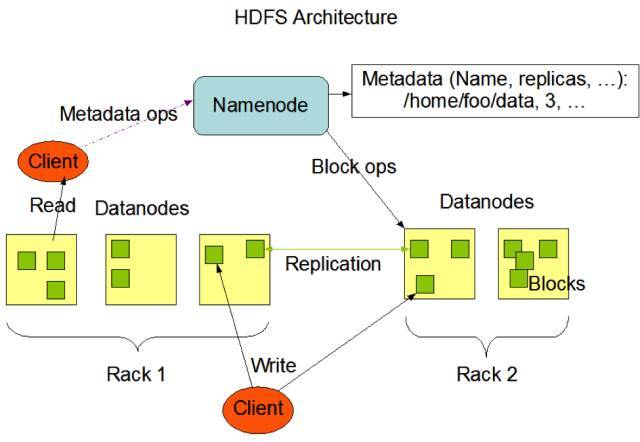
四、HDFS架构
NameNode与DataNode的关系就像Eureka和服务的关系。当Client需要查询数据的时候,首先先找NameNode,NameNode告诉它,这个文件有哪些DataBlock,这些DataBlock分别在哪些服务器上。然后Client就去找DataBlock。DataBlock将数据返回给Client。
NameNode
NameNode 是 主节点,DataNode是从节点。
NameNode调度DataNode,DataNode执行底层I/O任务。
NameNode存储元数据、文件到DataBlock的映射。
- 管理HDFS的命名空间
- 配置副本策略
- 管理文件到数据块的映射信息
- 处理客户端读写请求
DataNode
存储DataBlock的机器,就是DataNode。负责接收client写的文件,以及将client读取的文件传给client。
- 存储实际的DataBlock
- 执行数据块的读写操作
客户端
用户通过与NameNode、DataNode交互来访问整个文件系统。
- 文件切分。将文件切分成DataBlock
- 与NameNode进行交互,获取文件的位置信息
- 与DataNode交互,读取或者写入数据
- 通过命名管理HDFS、访问HDFS
SecondNameNode
- 辅助NameNode,分担其工作量
- 紧急情况下,辅助恢复NameNode
联邦NameNode
解决NameNode内存的问题,提出的解决方案是联邦NameNode,每个NameNode都保存一个命名空间信息如 /a ,会有多个NameNode。
五、HDFS高可用
如何解决NameNode不可用的问题,这里就设置一个备份NameNode。DataNode会向这两个NameNode上报心跳,而且这两个NameNode有一套共享存储机制,这个共享存储机制主要是QJM,QJM有点类似Zk,会有3个或多个节点,只有写入多数,才算成功。如果活动的NameNode挂掉了,在Zk上的临时节点就会消失,取代的是备用节点继续主节点的工作。
QJM
NFS
机架感知机制
为什么要关注rack(机架)呢?
机架内的机器之间的网络速度 高于 跨机架机器之间的网络速度机架之间的网络通信通常受上层交换机之间的网络带宽的限制
关注了又能起到什么作用?
HDFS默认存3份,第一个副本放在Client上传的DataNode,第二个副本放在与第一个副本相同机架的不同的DataNode,第三个副本放在与第二个副本不同相同机架的DataNode上
如果本地数据损坏,可以从同机架的另一个节点获取数据,为了降低带宽消耗和读取延时,HDFS会尽量取它最近的副本。默认情况,机架感知是没有开启的。
六、Shell操作
HDFS shell里面的很多操作,都和我们操作Linux文件的命令是一样的。

启动HDFS
执行脚本
./bin/hdfs namenode -format
下面两种方式是等价的
./sbin/start-dfs.sh
或
#### 启动namenode进程
./sbin/hadoop-daemon.sh start namenode
#### 启动datanode进程
./sbin/hadoop-daemon.sh start datanode
namenode是什么?datanode是什么?为什么必须要格式化namenode才能启动成功?
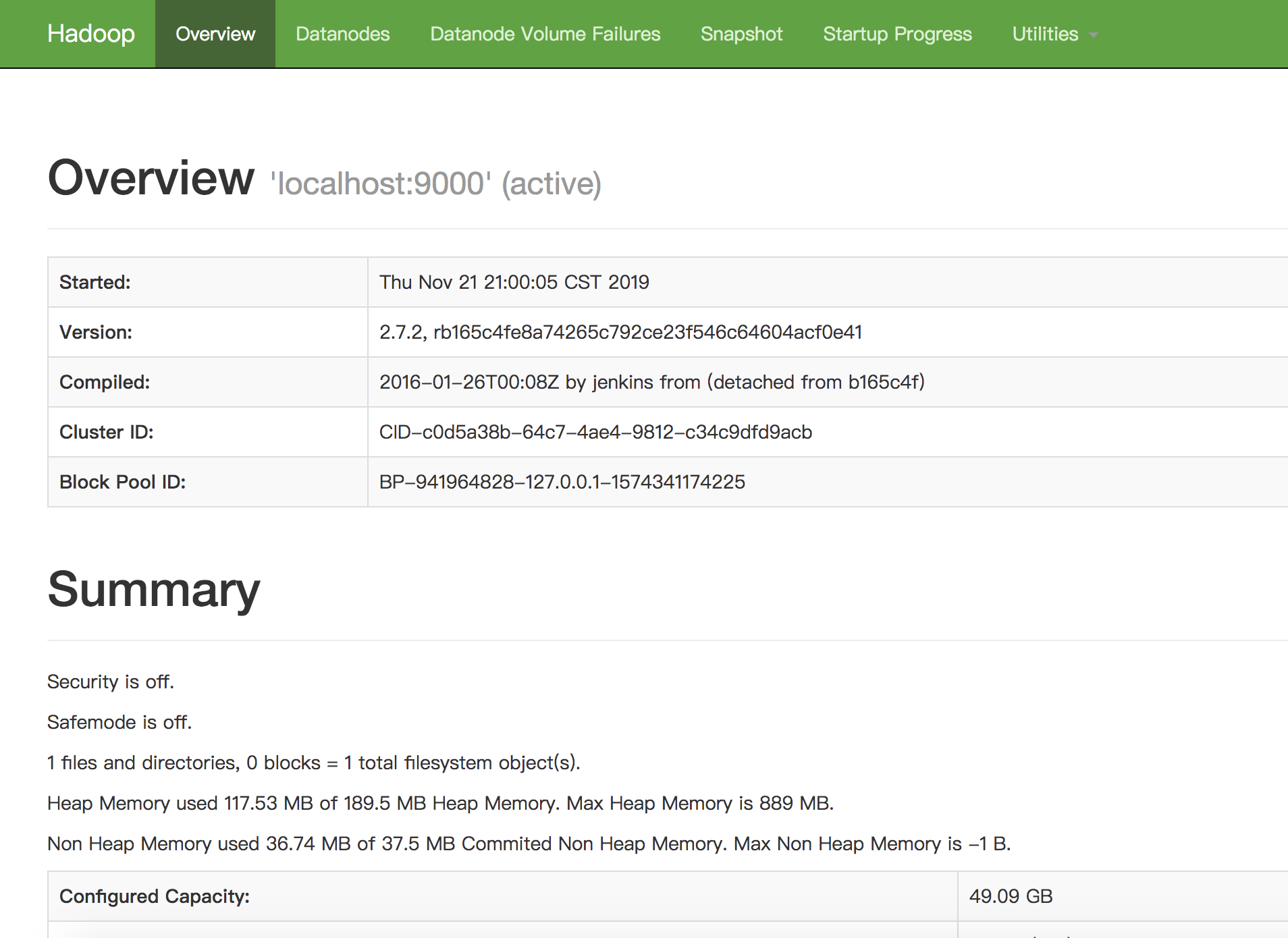
访问 http://127.0.0.1:50070/dfshealth.html#tab-overview
看到DFS的面板。
创建文件夹
./hdfs dfs -mkdir -p /usr/fonxian/input

添加文件到HDFS
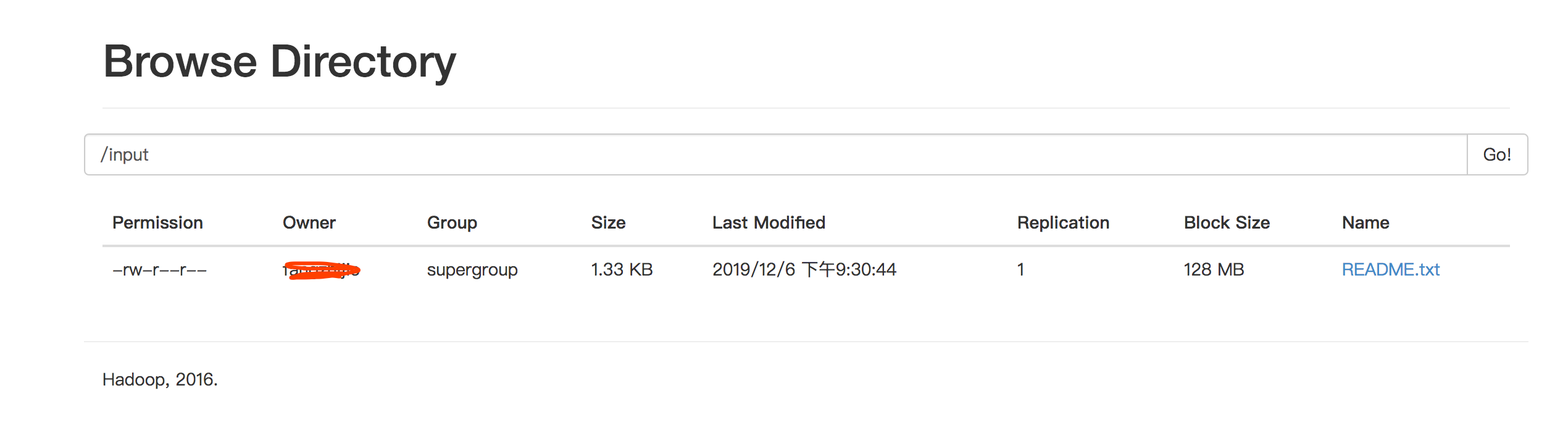
将文件上传的HDFS中的input目录下:
从图中可以看出HDFS默认的块大小为128MB,而文件使用的大小为1.33KB。
./hdfs dfs -put README.txt /input/
或
hadoop fs -mkdir -p /fonxian/mydata
hadoop fs -moveFromLocal NOTICE.txt /fonxian/mydata
追加文件内容
hadoop fs -appendToFile README.txt /fonxian/mydata/NOTICE.txt
将本地文件复制到HDFS
hadoop fs -copyFromLocal version.txt /fonxian/mydata/
将HDFS文件拷贝到本地
hadoop fs -copyToLocal /fonxian/mydata/version.txt /usr/local/
查看HDFS文件夹中的文件大小
hadoop fs -du -h /fonxian/mydata/

七、Java API操作
引入依赖
配置pom.xml文件
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
添加文件
public class HdfsClient {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
// 1.获取hdfs客户端对象
FileSystem fs = FileSystem.get(conf);
// 2.在hdfs上创建路径
fs.mkdirs(new Path("/test/hdfs/client"));
// 3.关闭资源
fs.close();
System.out.println("over");
}
}
如何提示没有权限,说明当前于用户testhadoop,没有操作hdfs的权限,该权限是root用户才有。
AccessControlException: Permission denied: user=testhadoop, access=WRITE, inode="/test/hdfs/client1":root:supergroup:
解决方法一:需要增加VM参数,来解决这个问题
-DHADOOP_USER_NAME=root
解决方案二:在代码中指定user
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://localhost:9000"),conf,"root");
上传文件
public static void uploadFile(FileSystem fs) throws IOException {
fs.copyFromLocalFile(new Path("/usr/local/hadoop/etc/hadoop/hdfs-site.xml"),new Path("/hdfs-test.xml"));
}
参数优先级
在项目resource下创建hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
运行上面上传文件的程序,会发现副本数为客户端这边配置的值。

Configuration conf = new Configuration();
conf.set("dfs.replication","1");
再在代码中增加参数配置,会发现优先级:客户端代码中的参数 > 客户端resource配置的参数 > 服务器配置的参数

下载文件
public static void uploadFile(FileSystem fs) throws IOException {
fs.copyFromLocalFile(new Path("/usr/local/hadoop/etc/hadoop/hdfs-site.xml"), new Path("/test-config.xml"));
}
若要剪切HDFS的文件到本地,则可以加上delSrc参数,第一个参数为delSrc参数。
fs.copyToLocalFile(true,new Path("/test-config.xml"), new Path("/usr/local/hadoop/etc/hadoop/hdfs-site-test.xml"),true);
删除文件
第二个参数设置为false,若删除的是文件夹,则会抛出异常,而设置为true,则会删除文件夹。
Path若是文件的路径,则设置成true或false都可以。
public static void deleteFile(FileSystem fs)throws IOException {
fs.delete(new Path("/fonxian"),true);
}
文件更名
public static void renameFile(FileSystem fs) throws IOException{
fs.rename(new Path("/hdfs-test.xml"),new Path("/hdfs-test123456.xml"));
}
查看文件详情
public static void getFileDetail(FileSystem fs) throws IOException{
RemoteIterator<LocatedFileStatus> remoteIterator = fs.listFiles(new Path("/"),true);
while(remoteIterator.hasNext()){
LocatedFileStatus status = remoteIterator.next();
System.out.println(status.getPath().getName());//文件名称
System.out.println(status.getPermission());//文件权限
System.out.println(status.getLen());//文件长度
BlockLocation[] locations = status.getBlockLocations();
for(BlockLocation location:locations){
String[] hosts = location.getHosts();
for(String host:hosts){
System.out.println(host);
}
}
System.out.println("------------------");
}
}
参考文档
《Hadoop实战》
5分钟深入浅出 HDFS
HDFS高可用性之QJM & NFS
Hadoop之HDFS面试题整理
hdfs 机架感知
Hadoop(二)—— HDFS的更多相关文章
- hadoop(二):hdfs HA原理及安装
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用.为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux ...
- Hadoop集群(二) HDFS搭建
HDFS只是Hadoop最基本的一个服务,很多其他服务,都是基于HDFS展开的.所以部署一个HDFS集群,是很核心的一个动作,也是大数据平台的开始. 安装Hadoop集群,首先需要有Zookeeper ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- Hadoop入门--HDFS(单节点)配置和部署 (一)
一 配置SSH 下载ssh服务端和客户端 sudo apt-get install openssh-server openssh-client 验证是否安装成功 ssh username@192.16 ...
- Hadoop基础-HDFS的API常见操作
Hadoop基础-HDFS的API常见操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习HDFS时的一些琐碎的学习笔记, 方便自己以后查看.在调用API ...
- Hadoop基础-HDFS安全管家之Kerberos实战篇
Hadoop基础-HDFS安全管家之Kerberos实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们都知道hadoop有很多不同的发行版,比如:Apache Hadoop ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop基础-HDFS的读取与写入过程剖析
Hadoop基础-HDFS的读取与写入过程剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简要介绍hadoop的写入过程,并不会设计到源码,我会用图和文字来描述hdf ...
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
- Hadoop基础-HDFS的读取与写入过程
Hadoop基础-HDFS的读取与写入过程 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 为了了解客户端及与之交互的HDFS,NameNode和DataNode之间的数据流是什么样 ...
随机推荐
- Doctype作用,标准模式与兼容模式的区别
<!DOCTYPE>声明位于位于HTML文档中的第一行,处于 <html> 标签之前.告知浏览器的解析器用什么文档标准解析这个文档.DOCTYPE不存在或格式不正确会导致文档以 ...
- tcp校验和
伪首部(pseudo header),通常指TCP伪首部和UDP伪首部 TCP的校验和是必需的,而UDP的校验和是可选的 TCP校验是需要校验包头和数据的 //共12字节 typedef struct ...
- Windows下MongoDB的下载安装、环境配置
下载MongoDB 1.进入MongoDB官网,Products -> 选择SOFTWARE下的MongoDB Server 2.选择下载最新版 3.选择对应的版本下载 msi安装包形式安装Mo ...
- WC_Project
个人项目:WC_Project 一.GitHub项目地址 GitHub项目地址:https://github.com/ting9500/WC_GNIT.git 二.PSP表格 PSP2.1 Perso ...
- Android笔记(七十五) Android中的图片压缩
这几天在做图记的时候遇第一次遇到了OOM,好激动~~ 追究原因,是因为在ListView中加载的图片太大造成的,因为我使用的都是手机相机直接拍摄的照片,图片都比较大,所以在加载的时候会出现内存溢出,那 ...
- Spring— 用更优雅的方式发HTTP请求(RestTemplate详解)
RestTemplate是Spring提供的用于访问Rest服务的客户端,RestTemplate提供了多种便捷访问远程Http服务的方法,能够大大提高客户端的编写效率. 我之前的HTTP开发是用ap ...
- 05-jQuery介绍
本篇主要介绍jQuery的加载.jquery选择器.jquery的样式操作.jQuery的事件.jquery动画等相关知识. 一.jQuery介绍 jQuery是目前使用最广泛的javascript函 ...
- golang版本管理工具GO111MODULE
在go1.11版本前,想要对go语言包进行管理,只能依赖第三方库实现,比如Vendor,GoVendor,GoDep,Dep,Glide等等. 1. 开启GO111MODULE 用环境变量 GO111 ...
- Python-tkinter开发学习 笔记
目录 课时一 kinter 介绍 查询官方帮助:help(tkinter) 概念介绍 最简单的界面 实现简单的模块 组件的摆放方式 pack()方式例子 gird() 方式例子 place方式例子 课 ...
- linux中container_of
linux 驱动程序中 container_of宏解析 众所周知,linux内核的主要开发语言是C,但是现在内核的框架使用了非常多的面向对象的思想,这就面临了一个用C语言来实现面向对象编程的问题,今天 ...