大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS
此处选取的是爬虫大作业——对猫眼电影上《小偷家族》电影的影评。
此处选取的是comment.csv文件,共计20865条数据。
将comment.csv上传到HDFS
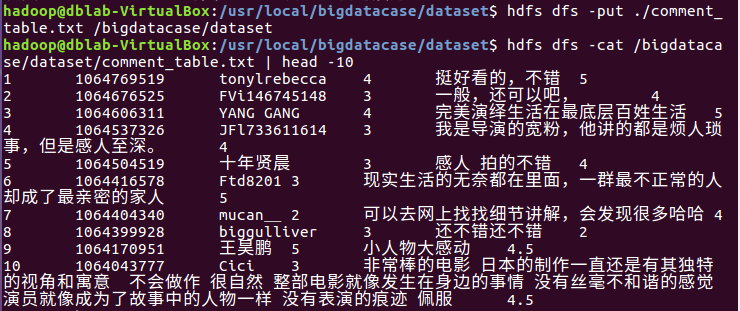
2.对CSV文件进行预处理生成无标题文本文件
编辑pre_deal.sh文件对csv文件进行数据预处理。
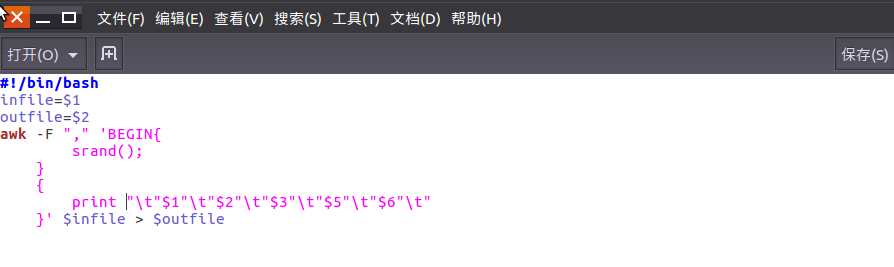
使得pre_deal.sh中的内容生效。
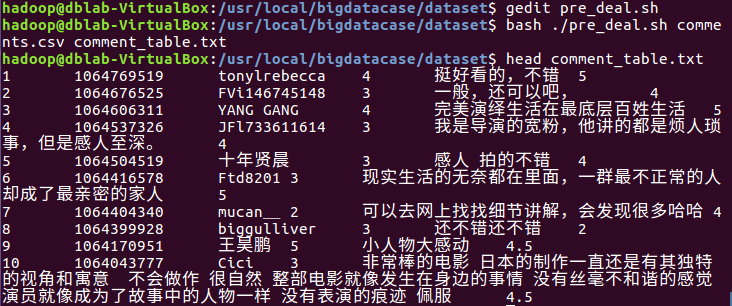
3.把hdfs中的文本文件最终导入到数据仓库Hive中
创建数据库dblab;
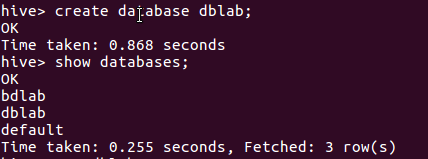
在数据库dblab中创建相应的表,此处是bigdata_user。

4.在Hive中查看并分析数据
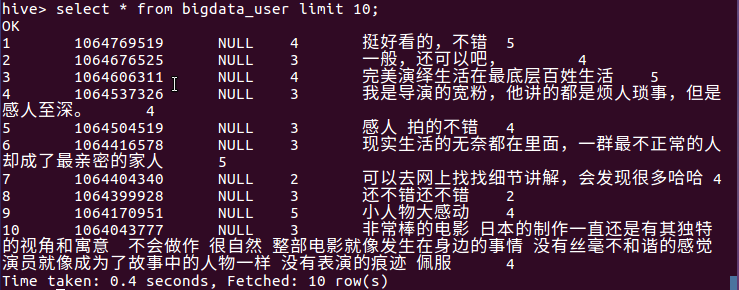
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
- 查询前20位猫眼电影用户对《小偷家族》电影的评分
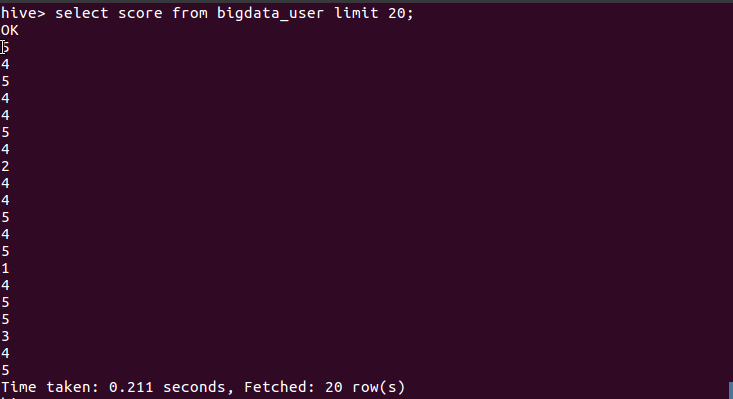
由上图可以看出大部分用户评分都在4分以上(5分评分为满分),这也就说明大部分用户对此部电影的评价都非常高。
- 查询给此电影1分评分的用户的评论

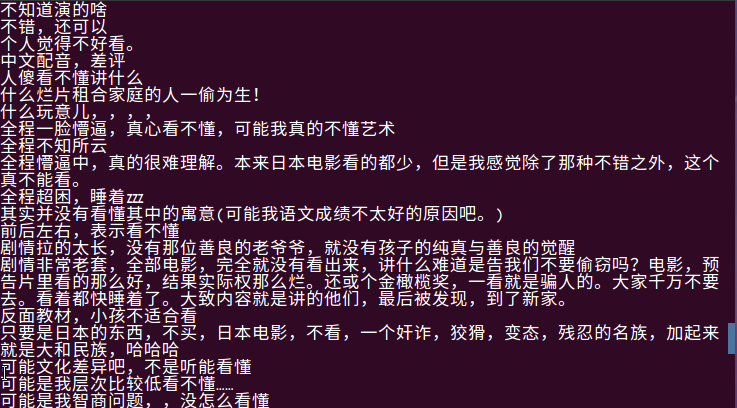
由上图可以看出给低分评价的用户多半为没看懂与难以理解所给出的低评分,由此可以得出用户对于电影的理解都不完全相同,一千个读者就有一千个哈姆雷特,大部分用户都是靠着主观意识来给与电影评分。
- 查询给此电影5分评分的用户的评论


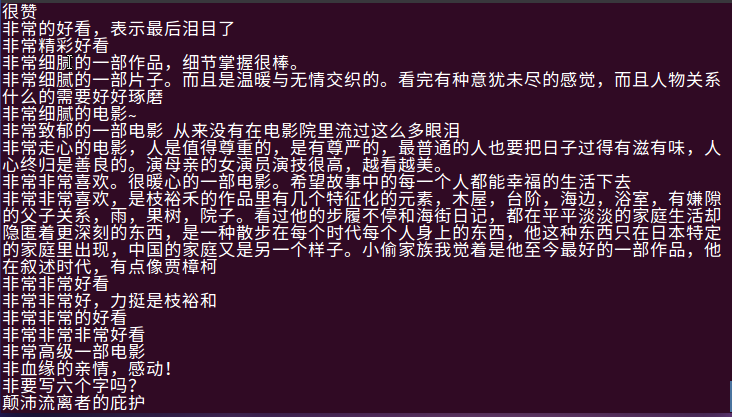
由5分评价也可以得出此部电影的主旨与想向观众表达的东西,可看出此部电影主要是围绕着亲情,感动为主题来叙述的。
- 查询对比5评分用户与1分评分用户的人数
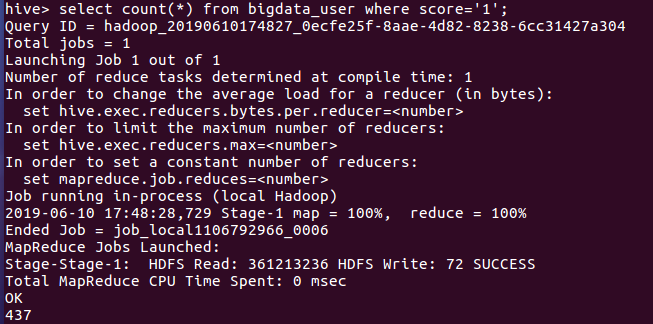
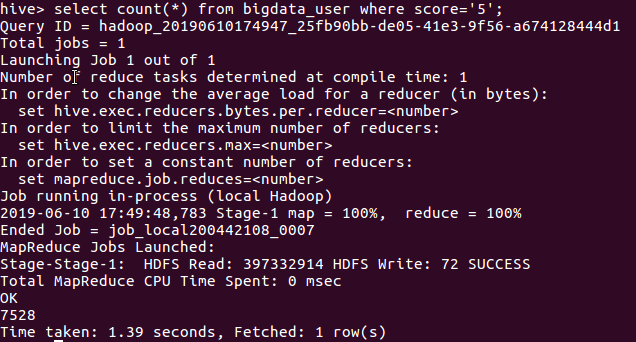
由上图可知给5分高分评价的用户人数为7528人,给1分低分评价用户人数为437人。由此可以知道这是一部优秀的电影。
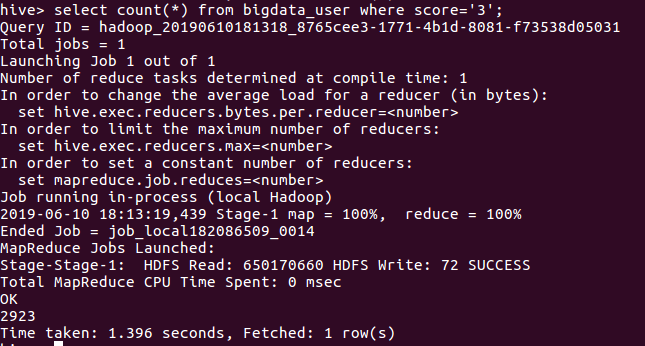
- 查询评分为3的用户人数
- 查询评分为1的用户id

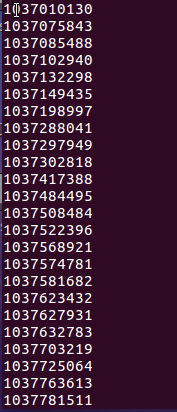
- 查询评分为4的用户的评论


与评分为5的评论相差不多,基本都是对整个电影的好评与受到的感动。
- 查询城市葫芦岛的评论用户人数
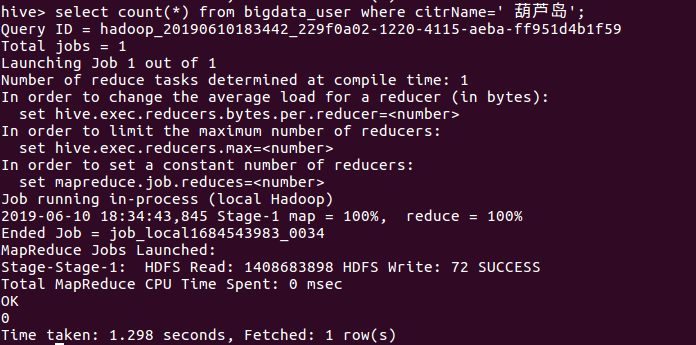
由此可看出此部电影还是比较小众,在较为不发达的城市基本无人问津。
- 查询评分为5的处于表格的序号

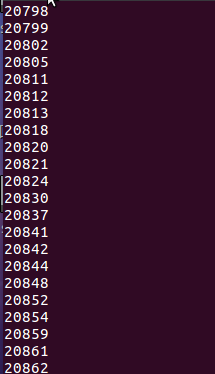
- 查询表格的数据中名字不重合的数据的数量
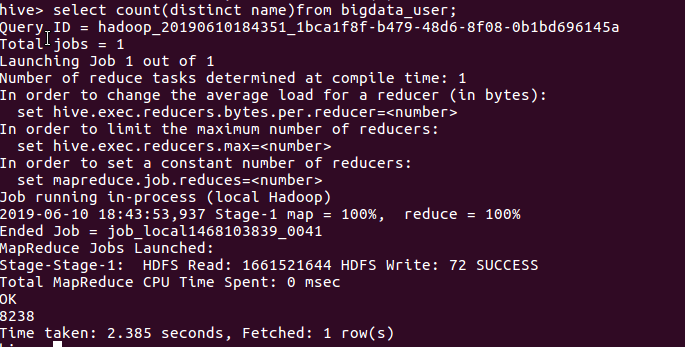
由上图可以看出由8238名用户没有重复评论数据的产生。说明爬取的数据仍然具备较大的重复性,需要注意。
- 查询表格数据中评论未重合的数据数量
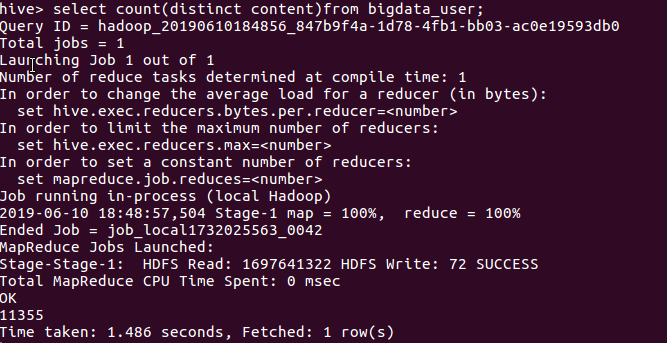
由上图可看出11355名用户评论没有重复数据的产生,基本可以视为有效数据。
总结:对于此次作业的完成,最大的问题就在于对于整个Hadoop环境的配置,就算是按部就班的按照步骤走,在这个过程中也遇到了非常多的问题,只要有一步的配置出现错误,会导致整个环境的配置失败。
但是总体来说还是基本按照要求完成了本次作业,在这个过程中我也是受益匪浅。
大数据应用期末总评——Hadoop综合大作业的更多相关文章
- 大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 1.将爬虫大作业产生的csv文件上传到HDFS 此次作业选取的 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 大数据应用期末总评(hadoop综合大作业)
作业要求源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.将爬虫大作业产生的csv文件上传到HDFS (1)在/usr ...
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- Hadoop综合大作业1
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.课程评分标准: 分数组成: 考勤 10 平时作业 30 爬 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- Docker 基础篇 入门篇
1.Docker入门 1.为什么要用docker? 相比于传统: 部署非常慢 成本非常高 资源浪费 难于迁移和扩展 可能会被限定硬件厂商 由于物理机的诸多问题,后来出现了虚拟机 一个物理机可以部署多个 ...
- 当ABAP遇见普罗米修斯
Jerry每次在工作场合中同Prometheus(普罗米修斯)打交道时,都会"出戏",因为这个单词给我的第一印象,并不是用go语言实现的微服务监控利器,而是名导雷德利·斯科特(Ri ...
- Python爬虫系列:四、Cookie的使用
Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的.那么 ...
- 0x01 Python logging模块
目录 Python logging 模块 前言 logging模块提供的特性 logging模块的设计过程 logger的继承 logger在逻辑上的继承结构 logging.basicConfig( ...
- H3C Short GI
- Gtest:Using visual studio 2017 cross platform feature to compile code remotely
参考:使用Visual Studio 2017作为Linux C++开发工具 前言 最近在学Gtest单元测试框架,由于平时都是使用Source Insight写代码,遇到问题自己还是要到Linux下 ...
- JAVA-JNI调用使用
准备工作: 1.打开eclipse,新建c++项目,编写c++ jni接口如下图: 2.编译运行生成dll文件,导入到java项目,在java中创建调用使用,如下图: C文件定义: 头文件 /* DO ...
- Python并发编程-线程同步(线程安全)
Python并发编程-线程同步(线程安全) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 线程同步,线程间协调,通过某种技术,让一个线程访问某些数据时,其它线程不能访问这些数据,直 ...
- Node.js GET/POST对应的url/query-string常用的方法介绍
<一>,在学node.js--GET/POST请求时,先看模块url和query-string的用法 1. 模块url用法,一般用于解析get请求. parse: [Function: u ...
- InnoDB存储引擎与MyIsam存储引擎的区别
特性比较 mysql5.5之后默认的存储引擎为InnoDB,在此之前默认存储引擎是MyIsam 特点 MyIsam InnoDB 锁机制 表锁 行锁 事务 不支持 支持 外键 不支持 支持 B树索引 ...