Python 爬取 13 个旅游城市,告诉你五一大家最爱去哪玩?
五一假期已经结束,小伙伴是不是都还没有玩过瘾?但是没办法,还有很多bug等着我们去写,同样还有需要money需要我们去赚。为了生活总的拼搏。

今年五一放了四天假,很多人不再只是选择周边游,因为时间充裕,选择了稍微远一点的景区,甚至出国游。各个景点成了人山人海,拥挤的人群,甚至去卫生间都要排队半天,那一刻我突然有点理解灭霸的行为了。
今天,通过分析去哪儿网部分城市门票售卖情况,简单的分析一下哪些景点比较受欢迎。等下次假期可以做个参考。
通过请求https://piao.qunar.com/ticket/list.htm?keyword=北京,获取北京地区热门景区信息,再通过BeautifulSoup去分析提取出我们需要的信息。
这里为了偷懒只爬取了前4页的景点信息,每页有15个景点。因为去哪儿并没有什么反爬措施,所以直接请求就可以了。
这里只是随机选择了13个热门城市:北京, 上海, 成都, 三亚, 广州, 重庆, 深圳, 西安, 杭州, 厦门, 武汉, 大连, 苏州。
并将爬取的数据存到了MongoDB数据库 。
爬虫部分完整代码如下
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient class QuNaEr():
def __init__(self, keyword, page=1):
self.keyword = keyword
self.page = page def qne_spider(self):
url = 'https://piao.qunar.com/ticket/list.htm?keyword=%s®ion=&from=mpl_search_suggest&page=%s' % (self.keyword, self.page)
response = requests.get(url)
response.encoding = 'utf-8'
text = response.text
bs_obj = BeautifulSoup(text, 'html.parser') arr = bs_obj.find('div', {'class': 'result_list'}).contents
for i in arr:
info = i.attrs
# 景区名称
name = info.get('data-sight-name')
# 地址
address = info.get('data-address')
# 近期售票数
count = info.get('data-sale-count')
# 经纬度
point = info.get('data-point') # 起始价格
price = i.find('span', {'class': 'sight_item_price'})
price = price.find_all('em')
price = price[0].text conn = MongoClient('localhost', port=27017)
db = conn.QuNaEr # 库
table = db.qunaer_51 # 表 table.insert_one({
'name' : name,
'address' : address,
'count' : int(count),
'point' : point,
'price' : float(price),
'city' : self.keyword
}) if __name__ == '__main__':
citys = ['北京', '上海', '成都', '三亚', '广州', '重庆', '深圳', '西安', '杭州', '厦门', '武汉', '大连', '苏州']
for i in citys:
for page in range(1, 5):
qne = QuNaEr(i, page=page)
qne.qne_spider()
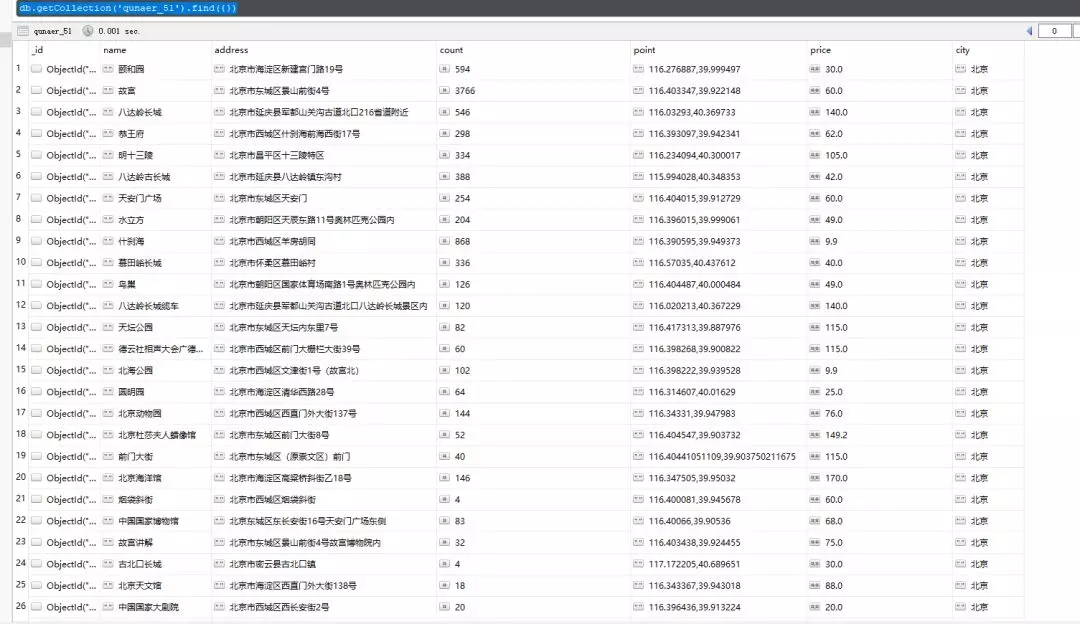
效果图如下
有了数据,我们就可以分析出自己想要的东西了
1、最受欢迎的15个景区
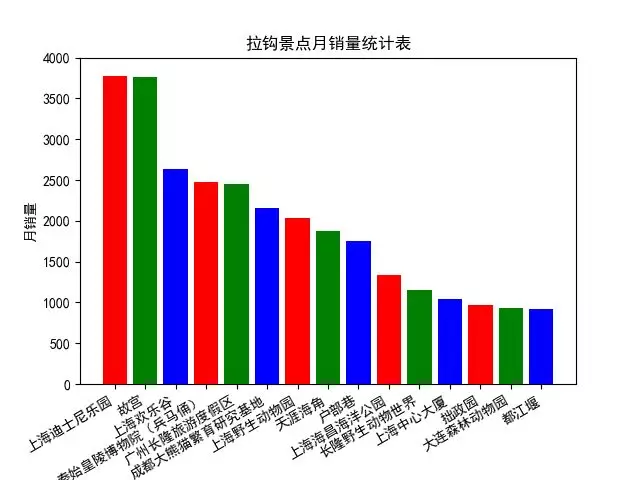
由图可以看出,在选择的13个城市中,最热门的景区为上海的迪士尼乐园
代码如下
from pymongo import MongoClient
# 设置字体,不然无法显示中文
from pylab import * mpl.rcParams['font.sans-serif'] = ['SimHei'] conn = MongoClient('localhost', port=27017)
db = conn.QuNaEr # 库
table = db.qunaer_51 # 表 result = table.find().sort([('count', -1)]).limit(15)
# x,y轴数据
x_arr = [] # 景区名称
y_arr = [] # 销量
for i in result:
x_arr.append(i['name'])
y_arr.append(i['count']) """
去哪儿月销量排行榜
"""
plt.bar(x_arr, y_arr, color='rgb') # 指定color,不然所有的柱体都会是一个颜色
plt.gcf().autofmt_xdate() # 旋转x轴,避免重叠
plt.xlabel(u'景点名称') # x轴描述信息
plt.ylabel(u'月销量') # y轴描述信息
plt.title(u'拉钩景点月销量统计表') # 指定图表描述信息
plt.ylim(0, 4000) # 指定Y轴的高度
plt.savefig('去哪儿月销售量排行榜') # 保存为图片
plt.show()
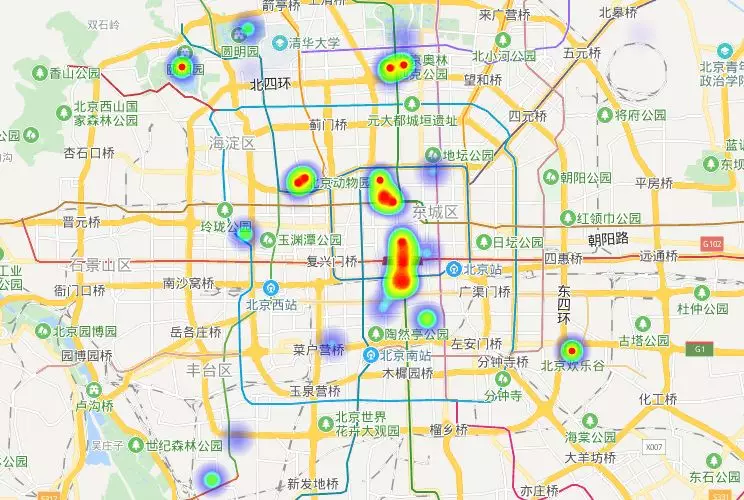
2、景区热力图
这里为了方(tou)便(lan),只展示一下北京地区的景区热力图。用到了百度地图的开放平台。首先需要先注册开发者信息,首页底部有个申请秘钥的按钮,点击进行创建就可以了。我的应用类型选择的是浏览器端,因此只需要组装数据替换掉相应html代码即可。另外还需要将自己访问应用的AK替换掉。效果图如下
3、景区价格
价格是出游第一个要考虑的,一开始想统计一下各城市的平均价格,但是后来发现效果不是很好,比如北京的刘老根大舞台价格在580元,这样拉高了平均价格。就好比姚明和潘长江的平均身高在190cm,并没有什么说服力。所以索性展示一下景区的价格分布。
根据价格设置了六个区间
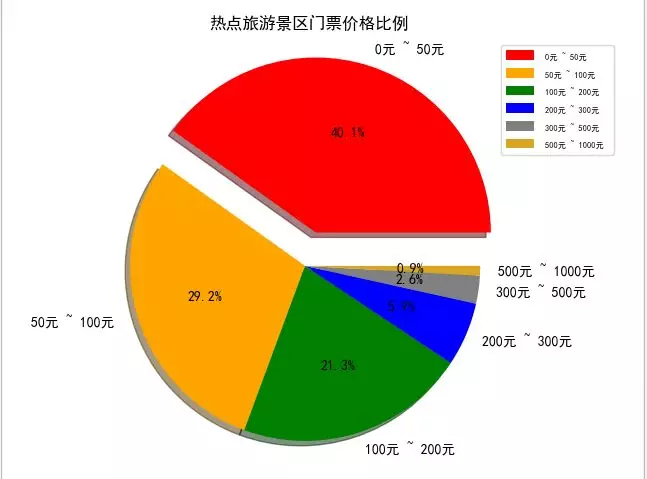
通过上图得知,大部分的景区门票价格都在200元以下。每次旅游花费基本都在交通、住宿、吃吃喝喝上了。门票占比还是比较少的。
代码如下
arr = [[0, 50], [50,100], [100, 200], [200,300], [300,500], [500,1000]]
name_arr = []
total_arr = []
for i in arr:
result = table.count({'price': {'$gte': i[0], '$lt': i[1]}})
name = '%s元 ~ %s元 ' % (i[0], i[1])
name_arr.append(name)
total_arr.append(result) color = 'red', 'orange', 'green', 'blue', 'gray', 'goldenrod' # 各类别颜色
explode = (0.2, 0, 0, 0, 0, 0) # 各类别的偏移半径 # 绘制饼状图
pie = plt.pie(total_arr, colors=color, explode=explode, labels=name_arr, shadow=True, autopct='%1.1f%%') plt.axis('equal')
plt.title(u'热点旅游景区门票价格比例', fontsize=12) plt.legend(loc=0, bbox_to_anchor=(0.82, 1)) # 图例
# 设置legend的字体大小
leg = plt.gca().get_legend()
ltext = leg.get_texts()
plt.setp(ltext, fontsize=6)
# 显示图
plt.show()
最后欢迎大家关注我的公众号,每天都会努力分享各种干货
Python 爬取 13 个旅游城市,告诉你五一大家最爱去哪玩?的更多相关文章
- 利用python爬取城市公交站点
利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得 ...
- Python爬取跑男的评论,看看大家都在看谁吧
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于菜J学Python,作者: J哥 Python爬取爬取腾讯视频弹幕视频讲解 http ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- python 爬取历史天气
python 爬取历史天气 官网:http://lishi.tianqi.com/luozhuangqu/201802.html # encoding:utf-8 import requests fr ...
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- Python爬取视频指南
摘自:https://www.jianshu.com/p/9ca86becd86d 前言 前两天尔羽说让我爬一下菜鸟窝的教程视频,这次就跟大家来说说Python爬取视频的经验 正文 https://w ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
随机推荐
- date——系统时间的命令
这是一个可以用各种姿势获得各种时间的命令.最近在写自动化定时脚本时学了一下. 参考:https://www.cnblogs.com/ginvip/p/6357378.html 比如: 利用cronta ...
- 阿里云容器服务中国最佳,进入 Forrester 报告强劲表现者象限
近日,全球知名市场调研机构 Forrester 发布首个企业级公共云容器平台报告. 报告显示:阿里云容器服务创造了中国企业最好成绩,与谷歌云位于同一水平线,进入强劲表现者象限. 究其原因,分析师认为: ...
- F#周报2019年第24期
新闻 ML.NET 1.1发布与模型构建器升级 .NET Core 3.0预览版6发布 尝试新的System.Text.Json API F#调用Infer.NET 匿名记录类型文档 了解FableC ...
- 【maven】【IDEA】idea中使用maven编译项目,报错java: 错误: 找不到符号 【2】
=================================================================================== idea中使用maven编译项目 ...
- dedecms5.7文章页的标签随机插入到内容中并且标签的地址为其标签关联的其他文章地址
dedecms5.7文章页的标签随机插入到内容中并且标签的地址为其他标签关联的文章地址 1 添加2个自定义函数 在dede/include/extend.func.php底部 添加如下代码 //根据文 ...
- 解决FastCGI 进程超过了配置的活动超时时限的问题
近日,需要满足测试需求,进行大数据并发测试时,报出[HTTP 错误 500.0 - Internal Server Error E:\PHP\php-cgi.exe - FastCGI 进程超过了配置 ...
- C++优先队列例子
#pragma GCC optimize(3) #include <bits/stdc++.h> #define N 105 using namespace std; struct Nod ...
- Windows+Qt+MinGW使用gRPC
本文参考博客文章Qt gRPC 简单应用进行了亲自尝试,特此记录以下过程,为后人提供经验.我的环境:Windows10 x64需要依赖MSYS2环境(一个类Unix环境,包管理器)MSYS2 gith ...
- fgets实现
char *fgets(char *s, int n, FILE *stream) { register int c; register char *cs; cs = s; while(--n > ...
- dos转unix
方式一 # yum install dos2unix.x86_64 # dos2unix file 方式二 查看样式: :set ff? //dos/unix 设置: :set fileformat= ...