Linux性能优化实战学习笔记:第十五讲
一、内存映射
内存管理也是操作系统最核心的功能之一,内存主要用来存储系统和应用程序的指令、数据、缓存等
1、我们通说的内存指的是物理内存还是虚拟内存?
我们通常说的内存容量,其实这指的是物理内存,物理内存也称为主存,大多数计算机用的主存都是动态随机访问内存(DRAM)。只有内核才可以直接访问物理内存。
那么,进程要访问内存时,该怎么办呢?
2、进程是如何访问内存的?
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样,进程就可以很方便地访问内存,更确切地说是访问虚拟内存
3、虚拟内存的内核空间和用户空间分布图
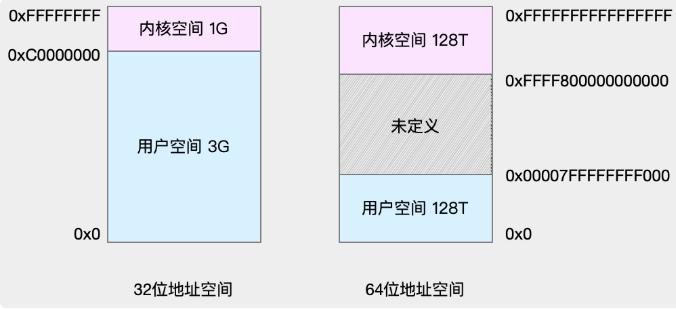
4、进程是如何访问内核空间内存的?
进程在用户态时,只能访问用户内存;只有进入内核态后,才可以访问内核空间内存,虽然每个进程的地址空间都包含了内核空间,但这些内核空间,其实关联的都是想同的物理内存
这样、进程切换到内核态后,就可以很方便地访问内核空间内存
5、并不是所有的虚拟机内存都会分配物理内存
既然每个进程都有一个这么大的地址空间,那么所有进程的虚拟内存加起来,自然要比实际的物理内存大得多
所以并不是所有的虚拟机内存都会分配物理内存,只有那些实际使用的虚拟机内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的
6、什么是内存映射?
内存映射,其实就是将虚拟内存地址映射到物理内存地址,为了完成内存映射,内核为每个进程都维护了一张页表,
记录虚拟地址与物理地址的映射关系,如下图所示:
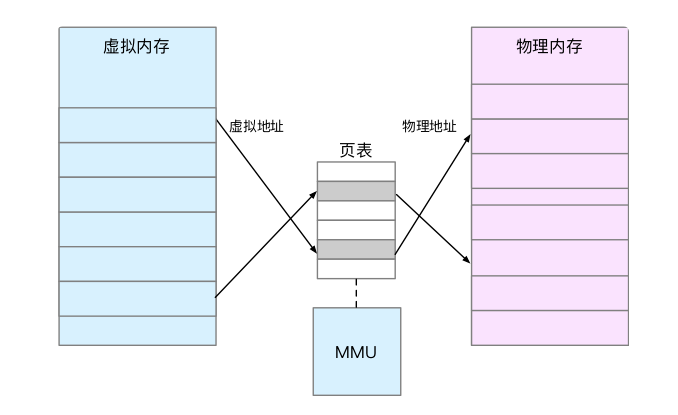
页表实际上存储在 CPU 的内存管理单元 MMU 中,这样,正常情况下,处理器就可以直接通过硬件,找出要访问的内存
7、进程访问的虚拟地址在页表中查不到,怎么办?
当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表,最后再返回用户空间、恢复进程运行
8、什么是TLB?TLB的作用是什么
TLB 其实就是 MMU 中页表的高速缓存,由于进程的虚拟地址空间是独立的,而 TLB 的访问速度又比MMU 快得多,
所以,通过减少进程的上下文切换,减少 TLB 的刷新次数,就可以提高 TLB 缓存的使用率,进而提高 CPU 的内存访问性能。
9、MMU 是以什么为单位来管理内存?
不过要注意,MMU 并不以字节为单位来管理内存,而是规定了一个内存映射的最小单位,也就是页,通常是 4 KB大小,
这样,每一次内存映射,都需要关联 4 KB 或者 4KB 整数倍的内存空间
10、如何减少页表的项数
页的大小只有 4 KB ,导致的另一个问题就是,整个页表会变得非常大。比方说,仅 32 位系统就需要 100 多万个页表项(4GB/4KB),才可以实现整个地址空间的映射。
为了解决页表项过多的问题,Linux 提供了两种机制,也就是多级页表和大页(HugePage)。
11、多级页
多级页表就是把内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移。由于虚拟内存空间通常只用了很少一部分,
那么多级页表就只保存这些使用中的区块,这样就可以大大地减少页表的项数
Linux 用的正是四级页表来管理内存页,如下图所示,虚拟地址被分为 5 个部分,前 4 个表项用于选择页,而最后一个索引表示页内偏移。

12、大页
再看大页,顾名思义,就是比普通页更大的内存块,常见的大小有 2MB 和 1GB。大页通常用在使用大量内存的的进程上,比如 Oracle、DPDK 等
通过这些机制,在页表的映射下,进程就可以通过虚拟地址来访问物理内存了。那么具体到一个 Linux 进程中,这些内存又是怎么使用的呢
二、虚拟内存空间分布
1、虚拟内存空间分布图

通过这张图你可以看到,用户空间内存,从低到高分别是五种不同的的内存段
2、虚拟内存空间分布详解

1、在这五个内存段中,堆和文件映射段的内存是动态分配的,比如说,使用 C 标准库的 malloc() 或者mmap() ,就可以分别在堆和文件映射段动态分配内存
2、其实 64 位系统的内存分布也类似,只不过内存空间要大得多,那么,更重要的问题来了,内存究竟是怎么分配的呢?
三、内存分配与回收
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
1、内存分配

都只在首次访问时才分配,也就是通过缺页异常进入内核中,再由内内核来分配内存。
1、如何减少内存碎片?
整体来说,Linux 使用伙伴系统来管理内存分配。前面我们提到过,这些内存在 MMU 中以页为单位进行管理,伙伴系统也一系统也一样,以页为单位来管理内存,并且会通过相邻页的合并,
减少内存碎片化(比如 brk 方式造成的内存碎片)。
2、比页更小的内存(不到 1K ),该怎么分配内存呢?
实际系统运行中,确实有大量比页还小的对象如果为它们也分配单独的页,那就太浪费内存了。所以,在用户空间,malloc 通过 brk() 分配的内存,在释放时并不立即归还系统,
而是缓存起来重复利用。在内核空间,Linux 则通过 slab 分配器来管理小内存。你可以把slab 看成构建在伙伴系统上的一个缓存,主要作用就是分配并分配并释放内核中的小对象。
2、内存回收
对内存来说,如果只分配而不释放,就会造成内存泄漏,甚至会耗尽系统内存。所以,在应用程序用完内存后,还需要调用free() 或 unmap() ,来释放这些不用的内存。
当然,系统也不会任由某个进程用完所有内存,在发现内存紧张时,系统就会通过一系列机制来回收内存,比如下面下面这三种方式:
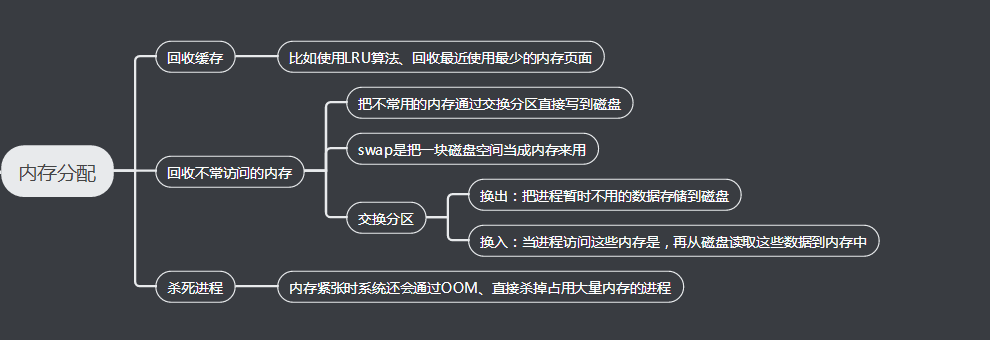
第三种方式提到的 OOM(Out of Memory),其实是内核的一种保护机制它监控进程的内存使用情况,并且使用 oom_score 为每个进程的内存使用情况进行评分:
一个进程消耗的内存越大,oom_score 就越大;
一个进程运行占用的 CPU 越多,oom_score 就越小
这样,进程的 oom_score 越大,代表消耗的内存越多,也就越容易被 OOM 杀死,从而可以更好保护系统。
当然,为了实际工作的需要,管理员可以通过 /proc 文件系统,手动设置进程的 oom_adj ,从而调整进程的 oom_score。
oom_adj 的范围是 [-17, 15],数值越大,表示进程越容易被 OOM 杀死;数值越小,表示进程越不容易被 OOM 杀死,其中 -17 表示禁止 OOM。
比如用下面的命令,你就可以把 sshd 进程的调小为 -16,这样, sshd 进程就不容易被 OOM 杀死
echo -16 > /proc/$(pidof sshd)/oom_adj
四、如何查看内存使用情况
1、free图解
[root@api ~]# free
total used free shared buff/cache available
Mem: 8010968 935180 5968260 16668 1107528 6835728
Swap: 4194300 0 4194300
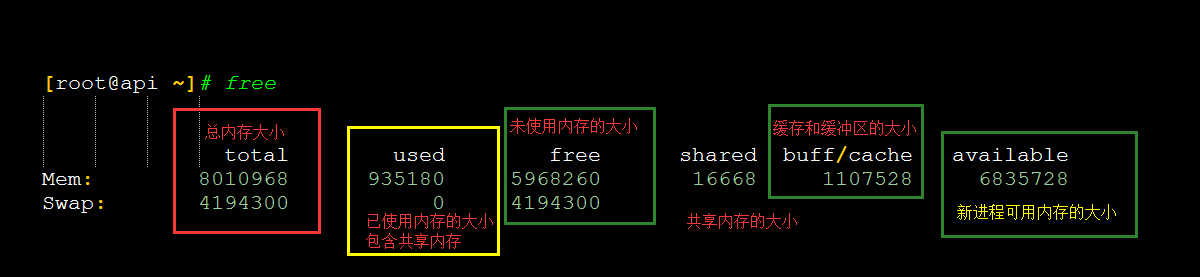
这里尤其注意一下,最后一列的可用内存 available,available 不仅包含未使用内存,还包括了可回收的缓存,所以一般会比未使用内存更大。
不过,并不是所有缓存都可以回收,所以一般会比未使用内存更大
2、top图解
top - 11:52:35 up 16 days, 55 min, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 101 total, 1 running, 100 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.1 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 14.7/8010968 [||||||||||||||| ]
KiB Swap: 0.0/4194300 [ ] PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 41348 3580 2332 S 0.0 0.0 0:36.59 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
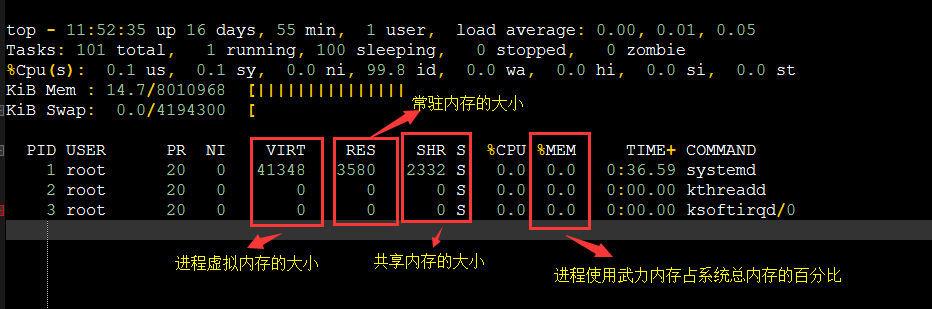
VIRT 是进程虚拟内存的大小:只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
RES 是常驻内存的大小:也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。
SHR 是共享内存的大小:比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。
%MEM 是进程使用物理内存占系统总内存的百分比。
3、需要注意两点
第一:虚拟内存通常并不会全部分配物理内存。从上面的输出,你可以发现每个进程的虚拟内存都比常驻内存大得多。
第二:共享内存 SHR 并不一定是共享的,比方说,程序的代码、非共享的动态链接库,也都算在 SHR 里。当然,
SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
Linux性能优化实战学习笔记:第十五讲的更多相关文章
- Linux性能优化实战学习笔记:第五讲
一.什么是CPU的使用率 1.你最常用什么指标来描述系统的CPU性能? 我想你的答案,可能不是平均负载,也不是CPU上下文切换,而是另一个更直观的指标CPU使用率 CPU使用率到底是怎么算出来的吗? ...
- Linux性能优化实战学习笔记:第四十五讲
一.上节回顾 专栏更新至今,四大基础模块的最后一个模块——网络篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,热情地留言和互动.还有不少同学分享了在实际生产环境中,碰到各种性能 ...
- Linux性能优化实战学习笔记:第三十二讲
一.上节总结 专栏更新至今,四大基础模块的第三个模块——文件系统和磁盘 I/O 篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,并且热情地留言与讨论. 今天是性能优化的第四期. ...
- Linux性能优化实战学习笔记:第三十六讲
一.上节总结回顾 上一节,我们回顾了经典的 C10K 和 C1000K 问题.简单回顾一下,C10K 是指如何单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 则是单机支持处理 ...
- Linux性能优化实战学习笔记:第四十三讲
一.上节回顾 上一节,我们了解了 NAT(网络地址转换)的原理,学会了如何排查 NAT 带来的性能问题,最后还总结了 NAT 性能优化的基本思路.我先带你简单回顾一下. NAT 基于 Linux 内核 ...
- Linux性能优化实战学习笔记:第四十四讲
一.上节回顾 上一节,我们学了网络性能优化的几个思路,我先带你简单复习一下. 在优化网络的性能时,你可以结合 Linux 系统的网络协议栈和网络收发流程,然后从应用程序.套接字.传输层.网络层再到链路 ...
- Linux性能优化实战学习笔记:第五十二讲
一.上节回顾 上一节,我们一起学习了怎么使用动态追踪来观察应用程序和内核的行为.先简单来回顾一下.所谓动态追踪,就是在系统或者应用程序还在正常运行的时候,通过内核中提供的探针,来动态追踪它们的行为,从 ...
- Linux性能优化实战学习笔记:第五十五讲
一.上节回顾 上一节,我们一起学习了,应用程序监控的基本思路,先简单回顾一下.应用程序的监控,可以分为指标监控和日志监控两大块. 指标监控,主要是对一定时间段内的性能指标进行测量,然后再通过时间序列的 ...
- Linux性能优化实战学习笔记:第五十八讲
一.上节回顾 专栏更新至今,咱们专栏最后一部分——综合案例模块也要告一段落了.很高兴看到你没有掉队,仍然在积极学习思考.实践操作,并热情地分享你在实际环境中,遇到过的各种性能问题的分析思路以及优化方法 ...
- Linux性能优化实战学习笔记:第十八讲
一.内存的分配和回收 1.管理内存的过程中,也很容易发生各种各样的“事故”, 对应用程序来说,动态内存的分配和回收,是既核心又复杂的一的一个逻辑功能模块.管理内存的过程中,也很容易发生各种各样的“事故 ...
随机推荐
- 【VSFTP服务】vsftpd文件传输协议
vsftpd文件传输协议 系统环境:CentOS Linux release 7.6.1810 (Core) 一.简介 FTP(文件传输协议)全称是:Very Secure FTP Server. ...
- 如何配置jdk的本地环境
在计算机→属性→高级系统设置→高级→环境变量,如图: 第一步:系统变量→新建 JAVA_HOME 变量 . 变量值填写jdk的安装目录(本人是C:\Program Files\Java\jdk1.8. ...
- oracle的instr()函数
我们知道很多语言都提供了indexOf()和lastIndexOf()函数,以便能查找某个字符在某个字符串中的出现的位置和最后一次出现的位置. 但是Oracle没有提供这两个函数,事实上,它提供了一个 ...
- 【UOJ#389】【UNR#3】白鸽(欧拉回路,费用流)
[UOJ#389][UNR#3]白鸽(欧拉回路,费用流) 题面 UOJ 题解 首先第一问就是判断是否存在一条合法的欧拉回路,这个拿度数和连通性判断一下就行了. 第二问判断转的圈数,显然我们只需要考虑顺 ...
- Kafka学习笔记之Kafka Consumer设计解析
0x00 摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以 ...
- War 包部署
Springboot 进行war包部署,以及踩坑历险!!! https://www.jianshu.com/p/4c2f27809571 Springboot2项目配置(热部署+war+外部tomca ...
- 安装win10和ubuntu双系统
2019-06-22 最近找了一份新的工作,要用到linux,由于之前基本上没有接触过这方面的东西,所以今天捣鼓一下,安装win10和linux双系统,办公研发双不误. 如果在安装的过程中遇到什么 ...
- 学习shiro第二天
昨天讲了shiro的认证流程以及代码实现,今天将对这个进行扩展. 因为我们的测试数据是shiro.ini文件中配置的静态数据,但实际上数据应该从数据库中查询出来才合理,因此我们今天讲讲JdbcReal ...
- EFLAGS寄存器(标志寄存器)
这篇文章不是从0开始的,前面还有一些汇编基础指令以及进制,我都没写,时间问题,还是今天空闲,我才想补一下博文,后面我陆续会把前面知识点渐渐补上.我不会重0基础讲起,中间会以.汇编.C.C++交叉的形式 ...
- python基础-面向对象编程之反射
面向对象编程之反射 反射 定义:通过字符串对对象的属性和方法进行操作. 反射有4个方法,都是python内置的,分别是: hasattr(obj,name:str) 通过"字符串" ...