ELK部署配置使用记录
为什么要用ELK:
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
1.收集-能够采集多种来源的日志数据
2.传输-能够稳定的把日志数据传输到中央系统
3.存储-如何存储日志数据
4.分析-可以支持 UI 分析
5.警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
ELK简介:
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Filebeat隶属于Beats。目前Beats包含四种工具:
1.Packetbeat(搜集网络流量数据)
2.Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
3.Filebeat(搜集文件数据)
4.Winlogbeat(搜集 Windows 事件日志数据)
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.html
Logstash:
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.html
Kibana:
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html
Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html
elasticsearch中文社区:
https://elasticsearch.cn/
部署Elk:
安装JDK 必须是1.8或者更高
- 把离线包传上去 解压出来,然后配置配置环境变量
- [root@localhost soft]# vim /etc/profile.d/java.sh

保存退出 重启配置
[root@localhost soft]# source /etc/profile.d/java.sh
测试一下
安装elasticsearch
- 上传离线安装包 解压 重命名 (也可以不重命名)
- [root@localhost soft]# mv elasticsearch-6.2./ elasticsearch
- [root@localhost soft]# ls
- elasticsearch jdk1..0_161
- [root@localhost soft]#
- 修改配置文件(备份一下防止误删)
[root@localhost soft]# cd /soft/elasticsearch/config/
[root@localhost config]# ls
elasticsearch.yml jvm.options log4j2.properties
[root@localhost config]# cp elasticsearch.yml elasticsearch_bak.yml
[root@localhost config]#
cluster.name: my-cluster #集群名称
node.name: node-1 #节点名称
path.data: /soft/elasticsearch/data #数据路径
path.logs: /soft/elasticsearch/logs #日志路径
network.host: 192.168.72.111 #主机地址
http.port: 9200 #端口
discovery.zen.ping.unicast.hosts: ["192.168.72.111:9200"] # 起订新节点通过主机列表发现
discovery.zen.minimum_master_nodes: 1 #主节点数量 防止集群脑裂问题
http.cors.enabled: true #es跨域配置
http.cors.allow-origin: "*" #es跨域配置
vim /etc/sysctl.conf
#末尾追加否则服务会报错。
vm.max_map_count=655360
sysctl -p #使上述配置生效
创建es启动用户
[root@localhost config]# useradd elasticsearch
[root@localhost config]# chown -R elasticsearch.elasticsearch /soft/elasticsearch/
修改文件句柄数
[root@localhost config]# vim /etc/security/limits.conf
#添加下面内容:
* soft nofile 102400
* hard nofile 102400
* soft nproc 102400
* hard nproc 102400
切换用户后台启动
[root@localhost config]# su - elasticsearch -c 'nohup /soft/elasticsearch/bin/elasticsearch &'
设置开机启动
[root@localhost config]# echo "su - elasticsearch -c 'nohup /soft/elasticsearch/bin/elasticsearch &'" >> /etc/rc.local
查看服务是否启动

简单测试下

安装Logstash
- 上传离线安装包 解压 重命名 (也可以不重命名)
- 增加配置新的测试配置文件 先配置成调试模式测试
[root@localhost config]# vim /soft/logstash/config/test.conf

启动logstash
[root@localhost config]# /soft/logstash/bin/logstash -f /soft/logstash/config/test.conf
安装filebeat
- 上传离线安装包 解压 重命名 (也可以不重命名)
- 修改配置文件
[root@localhost filebeat]# vim filebeat.yml
enabled: True //启用该配置
paths:
- /soft/log/*.log //检测的文件 可以是一个列表
output.logstash:
# The Logstash hosts
hosts: ["192.168.72.111:5044"] //logstash 地址 把信息推送到logstash
启动filebeat
[root@localhost filebeat]# /soft/filebeat/filebeat -c /soft/filebeat/filebeat.yml -e
测试一下 在/soft/log 下面新建log文件 并写入内容
[root@localhost ~]# echo 'test' >> /soft/log/1.log
查看logstash 控制台输出

测试完成,修改logstash 配置elasticsearch 数据库 新建一个配置文件
[root@localhost config]# vim es.conf

安装kibana
- 上传离线安装包 解压 重命名 (也可以不重命名)
- 修改配置文件
- [root@localhost config]# vim kibana.yml
server.port: 5601
- server.host: "192.168.72.111"
elasticsearch.url: "http://192.168.72.111:9200"
- 启动kibana
[root@localhost kibana]# bin/kibana
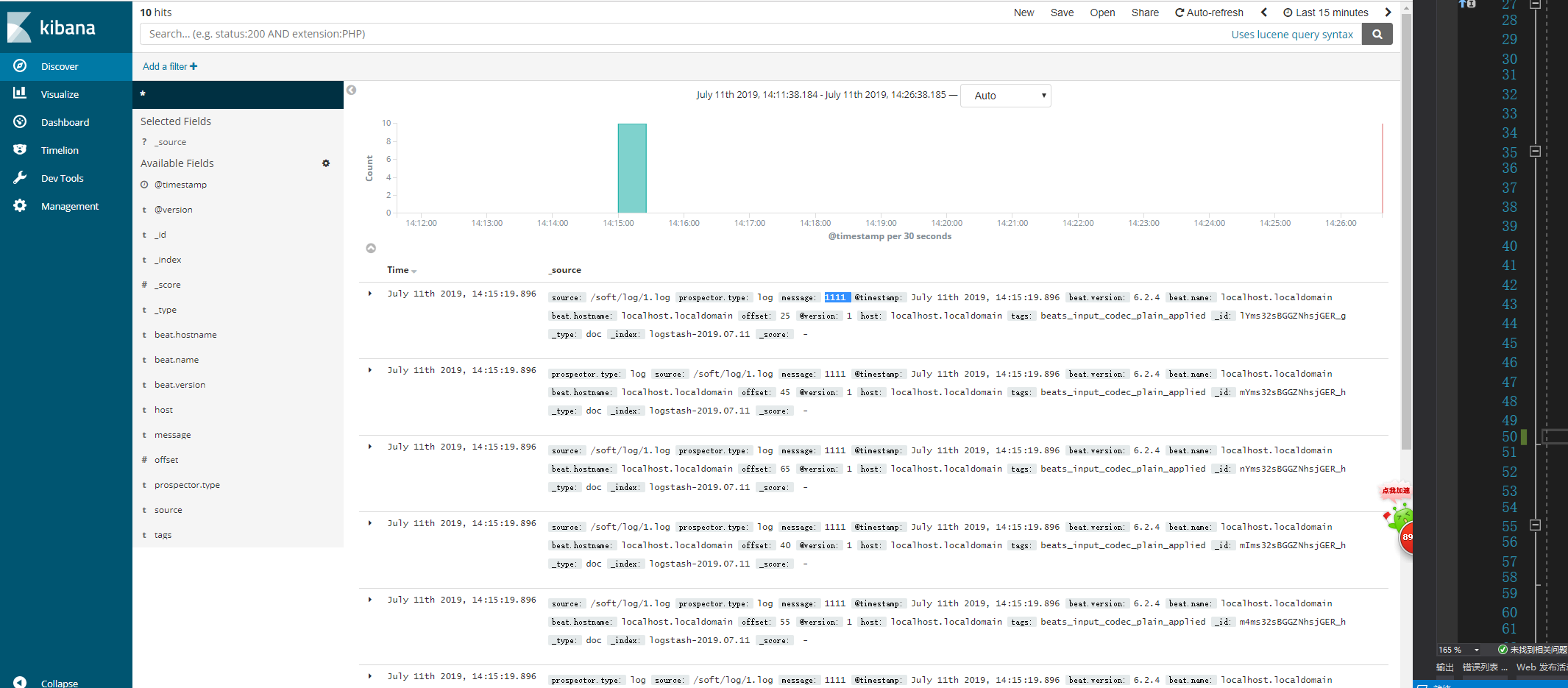
logstash的filter 功能
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
修改配置文件
- input {
- beats {
- host=>"172.16.101.10"
- port => ""
- }
- }
- filter {
- grok {
- patterns_dir=>"/soft/logstash/patterns"
- match => {
- "message" => "(?<date>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\s-\s(%{IP:client})\s-\s(?<level>[\S]*)"
- }
- }
- geoip{
- source=>"client"
- }
- mutate{
- remove_field => "host"
- }
- }
- output {
- elasticsearch {
- hosts => ["172.16.101.10:9200"]
- }
- }
grok 表达式 在线调试
ELK部署配置使用记录的更多相关文章
- ELK环境配置+log4j日志记录
ELK环境配置+log4j日志记录 1. 背景介绍 在大数据时代,日志记录和管理变得尤为重要. 以往的文件记录日志的形式,既查询起来又不方便,又造成日志在服务器上分散存储,管理起来相当麻烦, 想根据一 ...
- [原创]CI持续集成系统环境---部署Jenkins完整记录
Jenkins通过脚本任务触发,实现代码的自动化分发,是CI持续化集成环境中不可缺少的一个环节. 下面对Jenkins环境的部署做一记录. ------------------------------ ...
- HAproxy部署配置
HAproxy部署配置 拓扑图 说明: haproxy服务器IP:172.16.253.200/16 (外网).192.168.29.140/24(内网) 博客服务器组IP:192.168.29.13 ...
- Logstash+Kibana部署配置
Logstash是一个接收,处理,转发日志的工具.支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型. 典型的使用场景下(ELK): 用Elasticsearc ...
- 分布式实时日志分析解决方案ELK部署架构
一.概述 ELK 已经成为目前最流行的集中式日志解决方案,它主要是由Beats.Logstash.Elasticsearch.Kibana等组件组成,来共同完成实时日志的收集,存储,展示等一站式的解决 ...
- Centos7.2 下DNS+NamedManager高可用部署方案完整记录
Centos7.2 下DNS+NamedManager高可用部署方案完整记录 之前说到了NamedManager单机版的配置,下面说下DNS+NamedManager双机高可用的配置方案: 1)机器环 ...
- office web apps安装部署,配置https,负载均衡(六)配置负载均衡
owa可以采用任何的负载均衡方案,我们这里采用阿里云提供的负载均衡解决方案 前提条件,你已经配置了一台域控制器,两台域服务器[即安装了owa相关软件,并将计算机隶属于域]: 如果您不清楚怎么做,那么请 ...
- office web apps安装部署,配置https,负载均衡(五)配置服务器场
前提条件:您已经完成了域控制器的配置,拥有域账号,并且已经安装了OWA启动所需要的必要软件: 具体步骤可以参考: office web apps安装部署,配置https,负载均衡(一)背景介绍 off ...
- 部署Jenkins完整记录
Jenkins通过脚本任务触发,实现代码的自动化分发,是CI持续化集成环境中不可缺少的一个环节.下面对Jenkins环境的部署做一记录.-------------------------------- ...
随机推荐
- debian 系统修改密码
1.在Grub的引导装载程序菜单上,选择你要进入的条目,键入 “e” 来进入编辑模式.2.在第二行(类似于kernel /vmlinuz-2.6.15 ro root=/dev/hda2 ),键入”e ...
- properties文件属性值通过xml文件为 java entity属性赋值
一.通过xml配置文件进行赋值: 举个栗子,一目了然: 1.1 properties文件: 1.2 xml配置文件,将properties属性与java entity属性相关联:(这是一个新建的xml ...
- Alipay支付宝支付 报错 invalid [default store dir]: /tmp/
1.如果使用支付宝sdk,首先lotusphp_runtime 文件也要一起使用 支付宝现在的php sdk中有lotus框架可以和aop文件. 2.保证AopSdk.php文件中的方法可以走到这个 ...
- vue使用swiper模块滑动时报错:[Intervention] Ignored attempt to cancel a touchmove event with cancelable=false, for example becaus
报错: vue报这个错 [Intervention] Ignored attempt to cancel a touchmove event with cancelable=false, for ex ...
- HashMap、HashTable 区别
区别项 HashMap HashTable 继承和实现 public class HashMap<K,V> extends AbstractMap<K,V> implement ...
- Django API 自定义状态码
class BaseResponse(object): def __init__(self): self.code = 1000 self.data = None self.error = None ...
- Django 购物车模板
url from django.contrib import admin from django.urls import path, re_path from django.urls import i ...
- Java Map常用操作
Java之map常用操作 package basic; import java.util.HashMap; import java.util.Map; /** *Map常用操作方法 */ public ...
- 食物链【NOI2001】(信息学奥赛一本通 1390)
[题目描述] 动物王国中有三类动物A,B,C,这三类动物的食物链构成了有趣的环形.A吃B, B吃C,C吃A. 现有N个动物,以1-N编号.每个动物都是A,B,C中的一种,但是我们并不知道它到底是哪一种 ...
- dnsperf
github 地址:https://github.com/DNS-OARC/dnsperf mac安装:brew install dnsperf 参数详解 Dnsperf 支持下面的这些命令行参数: ...