MySQL之查询篇(三)
一:查询
1.创建数据库,数据表
-- 创建数据库
create database python_test_1 charset=utf8; -- 使用数据库
use python_test_1; -- students表
create table students(
id int unsigned primary key auto_increment not null,
name varchar(20) default '',
age tinyint unsigned default 0,
height decimal(5,2),
gender enum('男','女','中性','保密') default '保密',
cls_id int unsigned default 0,
is_delete bit default 0
); -- classes表
create table classes (
id int unsigned auto_increment primary key not null,
name varchar(30) not null
);
2.准备数据
-- 向students表中插入数据
insert into students values
(0,'小明',18,180.00,2,1,0),
(0,'小月月',18,180.00,2,2,1),
(0,'彭于晏',29,185.00,1,1,0),
(0,'刘德华',59,175.00,1,2,1),
(0,'黄蓉',38,160.00,2,1,0),
(0,'凤姐',28,150.00,4,2,1),
(0,'王祖贤',18,172.00,2,1,1),
(0,'周杰伦',36,NULL,1,1,0),
(0,'程坤',27,181.00,1,2,0),
(0,'刘亦菲',25,166.00,2,2,0),
(0,'金星',33,162.00,3,3,1),
(0,'静香',12,180.00,2,4,0),
(0,'郭靖',12,170.00,1,4,0),
(0,'周杰',34,176.00,2,5,0); -- 向classes表中插入数据
insert into classes values (0, "python_01期"), (0, "python_02期");
3.简单查询
(1)查询所有字段
语法:select * from 表名;
select * from students;

(2)使用as 给字段起别名
select id as 序号, name as 名字, gender as 性别 from students;

(3)可以使用as给表起别名
-- 如果是单表查询 可以省略表名
select id, name, gender from students; -- 表名.字段名
select students.id,students.name,students.gender from students; -- 可以通过 as 给表起别名
select s.id,s.name,s.gender from students as s;

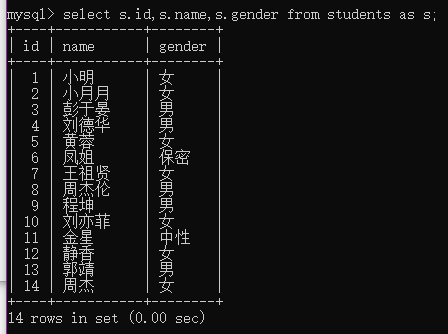
(4)消除重复行
在select后面列前使用distinct可以消除重复的行
select distinct 列1,... from 表名;
select distinct gender from students;
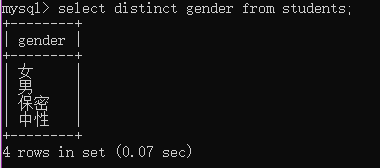
二:条件
使用where子句对表中的数据筛选,结果为true的行会出现在结果集中
1.语法
select * from 表名 where 条件;
select * from students where id=1;

2.where后面支持多种运算符,进行条件的处理
(1)比较运算符
- 等于: =
- 大于: >
- 大于等于: >=
- 小于: <
- 小于等于: <=
- 不等于: != 或 <>
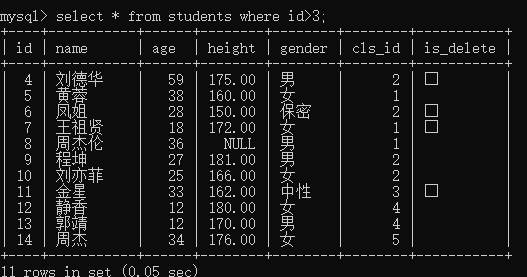
例1:查询编号大于3的学生
select * from students where id>3;
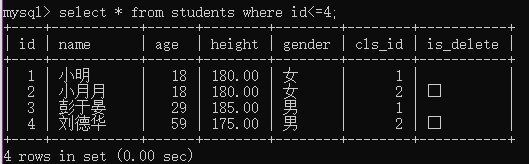
例2:查询编号不大于4的学生
select * from students where id<=4;
例3:查询姓名不是“黄蓉”的学生
select * from students where name !='黄蓉';
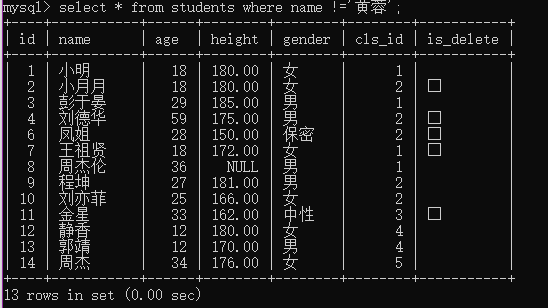
例4:查询没被删除的学生
select * from students where is_delete=0;
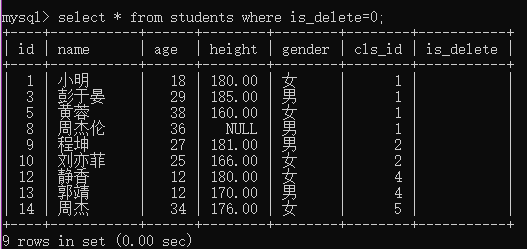
(2)逻辑运算符
- and
- or
- not
例1:查询编号大于3的女学生
select * from students where id>3 and gender='女';

例2:查询编号小于4或没被删除的学生
select * from students where id<4 or is_delete=0;

(3)模糊查询
- like
- %表示任意多个任意字符
- _表示一个任意字符
例1:查询姓小的学生;
select * from students where name like '小%';
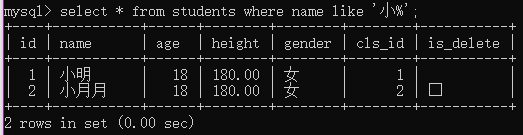
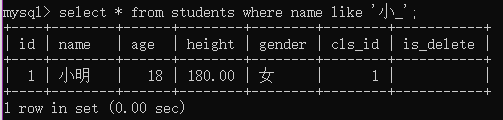
例2:查询姓'小'并且“名”是一个字的学生
select * from students where name like '小_';
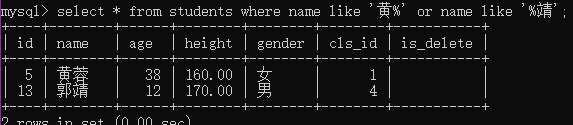
例3:查询姓黄或叫靖的学生
select * from students where name like '黄%' or '%靖';
(4)范围查询
- in表示在一个非连续的范围内
- between ... and ...表示在一个连续的范围内
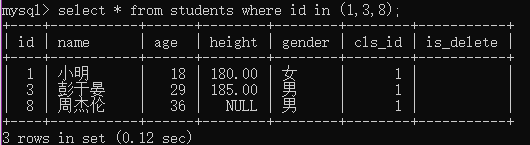
例1:查询编号是1,3或8的学生;
select * from students where id in (1,3,8);
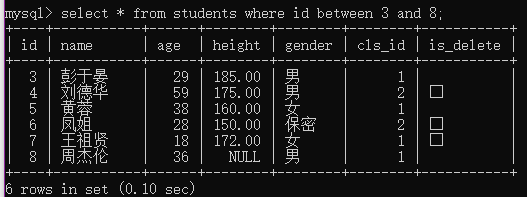
例2:查询编号在3至8之间的学生;
select * from students where id between 3 and 8;
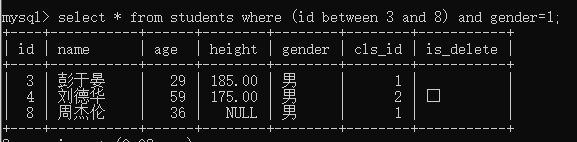
例3:查询编号在3至8之间所有的男生;
select * from students where (id betweent 3 and 8) and gender=1;
(5)空判断
- 判空is null (注意:null与‘’是不同的)
- 判非空is not null
例1:查询没有填写身高的学生;
select * from students where height is null;
例2:查询填写了身高的学生
select * from students where height is not null;
例3:查询填写了身高的男生
select * from students where height is not null and gender='男';
(6)优先级
- 优先级由高到低的顺序为:小括号,not,比较运算符,逻辑运算符
- and比or先运算,如果同时出现并希望先算or,需要结合()使用
三:排序
为了方便查看数据,可以对数据进行排序
1.语法
select * from 表名 order by 列1 asc|desc [,列2 asc|desc,...]
2.说明
- 将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
- 默认按照列值从小到大排列(asc)
- asc从小到大排列,即升序
- desc从大到小排序,即降序
例1:查询未删除男生信息,按学号降序
select * from students where gender='' and is_delete=0 order by id desc;
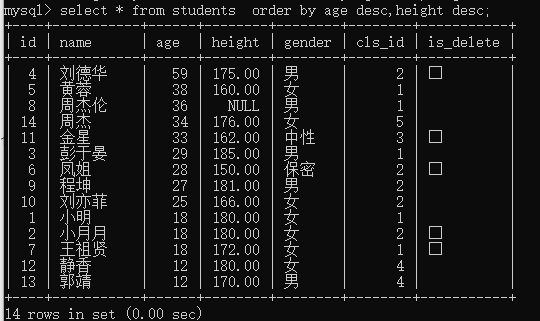
例2:查询未删除学生信息,按名称升序
select * from students where is_delete=0 order by name;
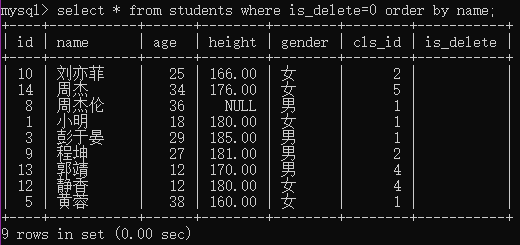
例3:显示所有的学生信息,先按照年龄从大-->小排序,当年龄相同时 按照身高从高-->矮排序
select * from students order by age desc, height desc;
四:聚合函数
1.总数
- count(*)表示计算总行数,括号中写星与列名,结果是相同的
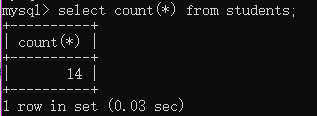
例1:查询学生总数
select count(*) from students;
2.最大值
- max(列)表示求此列的最大值
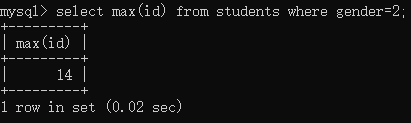
例1:查询女生的编号最大值
select max(id) from students where gender=2;
3.最小值
- min(列)表示求此列的最小值
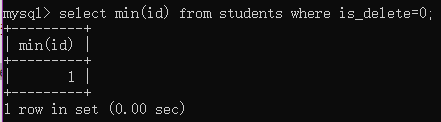
例1:查询未删除的学生最小编号
select min(id) from students where is_delete=0;
4求和
- sum(列)表示求此列的和
例1:查询男生的总年龄
select sum(age) from students where gender=1;

5平均值
- avg(列)表示求此列的平均值
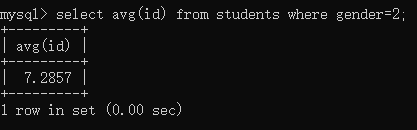
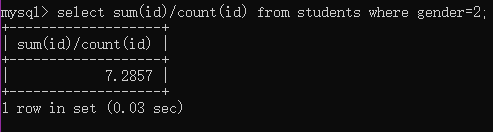
例1:查询未删除女生的编号平均值
select avg(id) from students where gender=2; / select sum(id)/count(id) from students where gender=2;
五:分组
1.group by
说明:
group by的含义:将查询结果按照1个或多个字段进行分组,字段值相同的为一组
group by可用于单个字段分组,也可用于多个字段分组
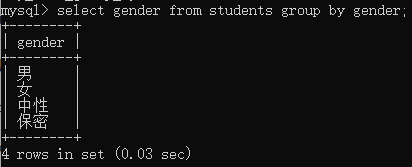
根据gender字段来分组,gender字段全部值有四个,分别是“男”,“女”,“中性”,“保密”,所以分了四组,当group by单独使用时,只显示出每组的第一条记录,所以单独使用group by的意义不大。
2.group by + group_concat()
说明:
group_concat(字段名)可以作为一个输出字段来使用
表示分组之后,根据分组结果,使用group_concat()来放置每一组的某字段的值的集合
例1:根据性别分组,并获取每个分组中有哪些人
select gender,group_concat(name) from students group by gender;
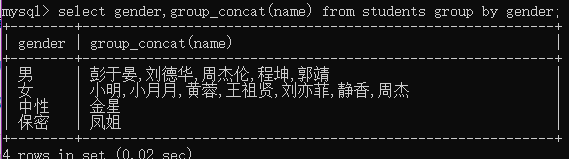
例2:根据性别分组,并获取每个分组中的id
select gender,group_concat(id) from students group by gender;

3.group by + 集合函数
说明:
通过group_concat()的启发,我们既然可以统计出每个分组的某字段的值的集合,那么我们也可以通过集合函数来对这个值的集合做一些操作
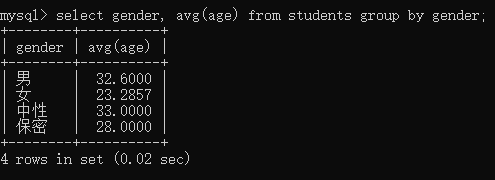
例1:以性别分组,统计年龄平均值
select gender, avg(age) from students group by gender;
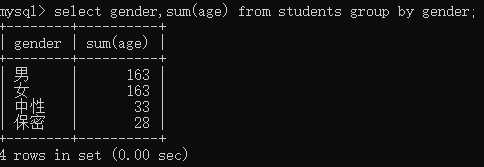
例2:以性别分组,统计年龄的总和
select gender,sum(age) from students group by gender;
4.group by + having
说明:
1.having条件表达式:用来分组查询后,指定一些条件,来输出查询结果
2.having效果和where效果一样,但是having只能用于group by后
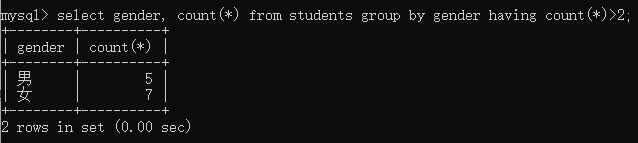
例1:以性别分组,获取分组内数量大于2的结果
select gender, count(*) from students group by gender having count(*)>2;
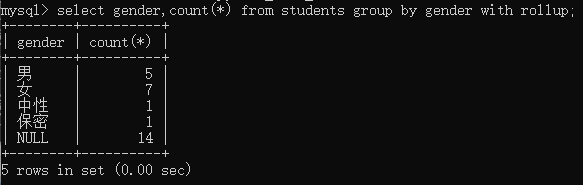
5:group by + with rollup
说明:
with rollup的作用是:在最后新增一行,来记录当前列里所有记录的总和
select gender,group_concat(name) from students group by gender with rollup;

select gender,count(*) from studnets group by gender with rollup;
六:分页
1.获取部分行
当数据量过大时,在一页中查看数据是一件非常麻烦的事
语法:
select * from 表名 limit start,count;
说明:
从start 开始,获取count条数据
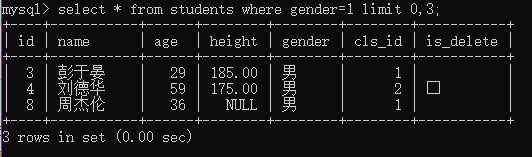
例1:查看前三行的男生信息
select * from students where gender=1 limit 0 3;
2.分页
后续补充,先欠着
七:连接查询
当查询结果的列来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的列返回
mysql支持三种类型的连接查询,分别为:内连接查询,左外连接查询,右外连接查询
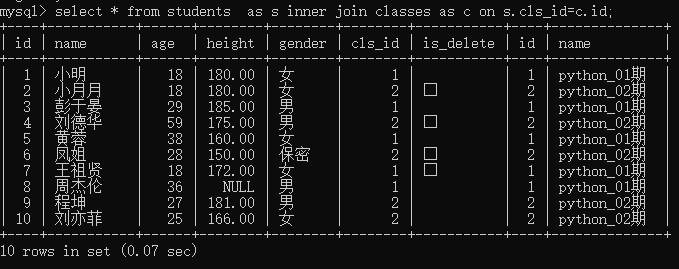
1.内连接查询 inner join
查询的结果为两个表匹配到的结果

例1:使用内连接查询学生表与班级表
select * from students as s inner join classes as c on s.cls_id on c.id;
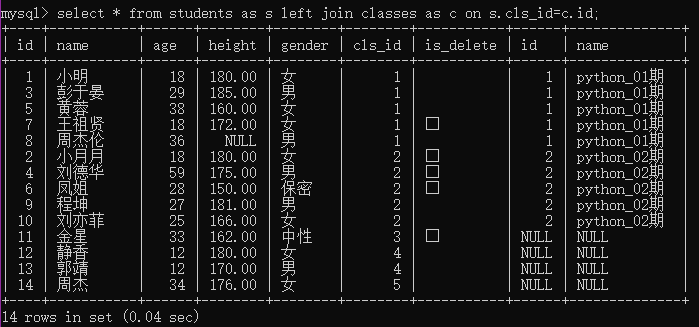
2.左外连接查询 left join
查询的结果为两个表匹配到的数据,左表特有的数据,对于右表中不存在的数据使用null填充

例2:使用左连接查询班级表与学生表
select * from students as s left join classes as c on s.cls_id=c.id;
3.右外连接查询 right join
查询的结果为两个表匹配到的数据,右表特有的数据,对于左表中不存在的数据使用null填充

例3:使用右连接查询班级表与学生表
select * from students as s right join classes as c on s.cls_id=c.id;

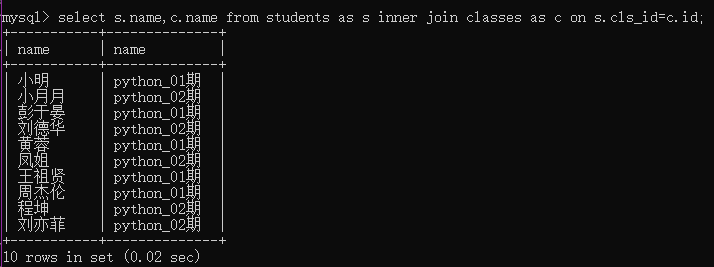
例4:查询学生姓名及班级名称
select s.name,c.name from students as s inner join classes as c on s.cls_id=c.id;
八:自关联查询
1.设计省信息的表结构provinces
id
ptitle
2.设计市信息的表结构citys
id
ctitle
proid
3.citys表的proid表示城市所属的省,对应着provinces表的id值
4.问题:能不能将两张表合为一张表?
5.思考:观察两张表发现,citys表比provinces表多一个列proid,其它列的类型都是一样的
存储的都是地区信息,而且每种信息的数据量有限,没必要增加一个新表,或者将来还要存储区、乡镇信息,都增加新表的开销太大
6.结论:定义表areas,结构如下
id
atitle
pid
7.说明:
(1)因为省没有所属的省份,所以可以填写为null
(2)城市所属的省份pid,填写省所对应的编号id
(3)这就是自关联,表中的某一列,关联了这个表中的另外一列,但是它们的业务逻辑含义是不一样的,城市信息的pid引用的是省信息的id,在这个表中,结构不变,可以添加区县、乡镇街道、村社区等信息
8:实战
(1)建表
create table areas(
aid int primary key,
atitle varchar(20),
pid int
(2)准备数据
insert into areas
values ('', '河北省', NULL),
('', '石家庄市', ''),
('', '邯郸市', ''),
('', '保定市', ''),
('', '张家口市', ''),
('', '承德市', ''),
('', '河南省', NULL),
('', '郑州市', ''),
('', '洛阳市', ''),
('', '安阳市', ''),
('', '新乡市', ''),
('', '焦作市', ''),
('410101', '中原区', '410100'),
('410102', '二七区', '410100'),
('410103', '金水区', '410100');
(3)查询
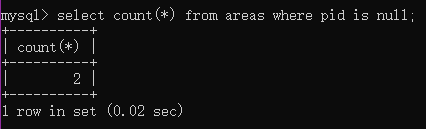
例1:查询一共有多少个省
select count(*) from areas where pid is null;
例2:查询省的名称为“河南省”的所有城市
select city.* from areas as city
inner join areas as province on city.pid=province.aid
where province.atitle='河南省'; 
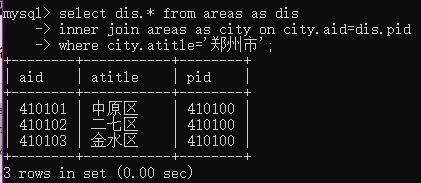
例3:查询市的名称为“广州市”的所有区县
select dis.* from areas as dis
inner join areas as city on city.aid=dis.pid
where city.atitle='郑州市';
九:子查询
1.子查询
在一个select 语句中,嵌入另外一个select 语句,那么嵌入的select 语句就是子查询语句
2.主查询
主要查询的对象,第一个select 语句
3.主查询和子查询的关系
子查询是嵌入到主查询中
子查询是辅助主查询的,要么充当条件,要么充当数据源
子查询是可以独立的语句,是一条完整的select 语句
4.子查询分类
标量子查询: 子查询返回的结果是一个数据(一行一列)
列子查询: 返回的结果是一列(一列多行)
行子查询: 返回的结果是一行(一行多列)
(1)标量子查询
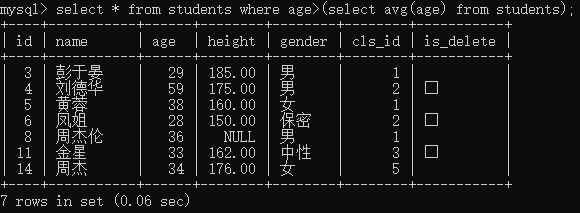
a.查询班级学生的平均年龄
b.查询大于平均年龄的学生
select * from students where age>(select avg(age) from students);
(2)列级子查询
查询还有学生在班的所有班级名字
select name from classes where id in (select cls_id from students);
(3)行级子查询
查询班级年龄最大,身高最高的学生
行元素: 将多个字段合成一个行元素,在行级子查询中会使用到行元素
select * from students where (height,age) = (select max(height),max(age) from students);
十、总结
1.查询完整格式
SELECT select_expr [,select_expr,...] [
FROM tb_name
[WHERE 条件判断]
[GROUP BY {col_name | postion} [ASC | DESC], ...]
[HAVING WHERE 条件判断]
[ORDER BY {col_name|expr|postion} [ASC | DESC], ...]
[ LIMIT {[offset,]rowcount | row_count OFFSET offset}]
]
(1)完整的select语句
select distinct *
from 表名
where ....
group by ... having ...
order by ...
limit start,count
(2)执行顺序
- from 表名
- where ....
- group by ...
- select distinct *
- having ...
- order by ...
- limit start,count
MySQL之查询篇(三)的更多相关文章
- MYSQL之查询篇
2. 数据库操作 数据库在创建以后最常见的操作便是查询 2.1 查询 为了便于学习和理解,我们预先准备了两个表分别是stduents表和classes表两个表的内容和结构如下所示 students表的 ...
- MySQL 子查询(三) 派生表、子查询错误
From MySQL 5.7 ref:13.2.10.8 Derived Tables 八.派生表 派生表是一个表达式,用于在一个查询的FROM子句的范围内生成表. 例如,在一个SELECT查询的FR ...
- mysql第四篇:数据操作之多表查询
mysql第四篇:数据操作之多表查询 一.多表联合查询 #创建部门 CREATE TABLE IF NOT EXISTS dept ( did int not null auto_increment ...
- mysql第四篇--SQL逻辑查询语句执行顺序
mysql第四篇--SQL逻辑查询语句执行顺序 一.SQL语句定义顺序 SELECT DISTINCT <select_list> FROM <left_table> < ...
- 第三章 MySQL高级查询(一)
第三章 MySQL高级查询(一) 一.SQL语言的四个分类 1. DML(Data Manipulation Language)(数据操作语言):用来插入,修改和删除表中的数据,如INSE ...
- ElasticSearch查询 第三篇:词条查询
<ElasticSearch查询>目录导航: ElasticSearch查询 第一篇:搜索API ElasticSearch查询 第二篇:文档更新 ElasticSearch查询 第三篇: ...
- Mysql慢查询 [第二篇]
一.简介 pt-query-digest是用于分析mysql慢查询的一个工具,它可以分析binlog.General log.slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdu ...
- mysql 开发进阶篇系列 23 应用层优化与查询缓存
一.概述 前面章节介绍了很多数据库的优化措施,但在实际生产环境中,由于数据库服务器本身的性能局限,就必须要对前台的应用来进行优化,使得前台访问数据库的压力能够减到最小. 1. 使用连接池 对于访问数据 ...
- MySQL - 日常操作三 mysql慢查询;
sql语句使用变量 use testsql; set @a=concat('my',weekday(curdate())); # 组合时间变量 set @sql := concat('CREATE T ...
随机推荐
- vue - 基础(2)
<div id="content"> {{ msg }} <div v-text="msg"></div> <div ...
- destoon搜索伪静态失败解决办法
今天给一个朋友调试DT6.0内核的站点,搜索中文出现http 403 forbidden,找了半天,很纳闷,最后一个一个查看源代码总算找到,在此分享给大家! 解决的方法: 1.找到include/sa ...
- 资源管理(Resource Management),知识点
资料 网址 资源管理(Resource Management)服务 包含一系列支持企业IT治理的资源管理产品集合,主要包括资源组和资源目录.通过资源管理服务,您可以按照业务需要搭建合适的资源组织关系, ...
- mobx 学习笔记
Mobx 笔记 Mobx 三板斧,observable.observer.action. observable: 通过 observable(state) 定义组件的状态,包装后的状态是一个可观察数据 ...
- 1. vue 的安装
兼容性 Vue 不支持 IE8 及以下版本,因为 Vue 使用了 IE8 无法模拟的 ECMAScript 5 特性.但它支持所有兼容 ECMAScript 5 的浏览器. 安装: 1.直接用 < ...
- django -- web框架的本质
web框架本质 我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端. 这样我们就可以自己实现Web框架了. 下面代码是一个简单的socket服 ...
- 浅谈BST(二叉查找树)
目录 BST的性质 BST的建立 BST的检索 BST的插入 BST求前驱/后继 BST的节点删除 复杂度 平衡树 BST的性质 树上每个节点上有个值,这个值叫关键码 每个节点的关键码大于其任意左侧子 ...
- 使Jackson和Mybatis支持JSR310标准
1.首先要确保Jackson和Mybatis正确地整合进项目了 2.添加额外的依赖 <dependency> <groupId>org.mybatis</groupId& ...
- Salesforce 开发整理(三)权限共享
Salesforce提供对象的访问权限可以通过 安全性控制 → 共享设置,可以查看每个对象在系统内部默认的访问权限 共用读写:对象的记录任何用户都可以进行读写操作 公用只读:对象的记录任何用户都可以查 ...
- python: int to unicode string
>>> import types >>> print type(str(2)) <type 'str'> >>> ')) <ty ...