使用mapreduce清洗简单日志文件并导入hive数据库
Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
文件部分如下:
1.192.25.84 2016-11-10-00:01:14 10 54 video 5551
1.194.144.222 2016-11-10-00:01:20 10 54 video 3589
1.194.187.2 2016-11-10-00:01:05 10 54 video 2212
1.203.177.243 2016-11-10-00:01:18 10 6050 video 7361
1.203.177.243 2016-11-10-00:01:19 10 72 video 7361
1.203.177.243 2016-11-10-00:01:22 10 6050 video 7361
1.30.162.63 2016-11-10-00:01:46 10 54 video 3639
1.84.205.195 2016-11-10-00:01:12 10 54 video 1412
1.85.61.18 2016-11-10-00:01:31 10 54 video 6578
1.85.61.37 2016-11-10-00:01:36 10 54 video 7212
101.200.101.13 2016-11-10-00:01:06 10 524288 video 11938
101.200.101.201 2016-11-10-00:01:03 10 4468 article 4779
101.200.101.204 2016-11-10-00:01:10 10 4468 article 11325
101.200.101.207 2016-11-10-00:01:08 10 4468 article 11325
流程:
数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
(2)第二阶段:根据提取出来的信息做精细化操作
ip--->城市 city(IP)
date--> time:2016-11-10 00:01:03
day: 10
traffic:62
type:article/video
id:11325
(3)hive数据库表结构:(将清洗出来的文件导入hive表中)
create table if not exists data(
mip string,
mtime string,
mday string,
mtraffic bigint,
mtype string,
mid string)
row format delimited fields terminated by '\t' lines terminated by '\n';//导入数据以'\t'分隔,'\n'换行
源代码:
import java.lang.String;
import java.util.*;
import java.text.SimpleDateFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public static final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); //原时间格式
String day=parseDay(line);//天数
return new String[] { ip, time,day,traffic,type,id};
private static String parseIP(String line) { //ip
return ip;
private static String parseTime(String line) { //时间
private static String parseDay(String line) { //天数
return day;
private static String parseTraffic(String line) { //流量,转为int型
return traffic;
private static String parseType(String line) {
return day;
private static String parseId(String line) {
return day;
public static class Map extends Mapper<Object, Text, Text, NullWritable> {
public static Text word = new Text();
public void map(Object key, Text value, Context context)throws IOException, InterruptedException {
String line = value.toString();
String arr[] = parse(line);
word.set(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"\t"+arr[4]+"\t"+arr[5]+"\t");//一定用'\t',空格容易乱会有意想不到的问题
context.write(word,NullWritable.get());
}
}
public static class Reduce extends Reducer<Text, NullWritable, Text, NullWritable> {
}
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
System.out.println("start");
Job job=Job.getInstance(conf);
job.setJarByClass(Dataclean.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);//设置map的输出格式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in = new Path("hdfs://localhost:9000/mapReduce/mymapreduce1/result.txt");
Path out = new Path("hdfs://localhost:9000/mapReduce/mymapreduce1/out");
FileInputFormat.addInputPath(job,in );
FileOutputFormat.setOutputPath(job,out);
boolean flag = job.waitForCompletion(true);
System.out.println(flag);
System.exit(flag? 0 : 1);
}
}
清洗所得部分结果如下:
1.192.25.84 2016-11-10-00:01:14 10 54 video 5551
1.194.144.222 2016-11-10-00:01:20 10 54 video 3589
1.194.187.2 2016-11-10-00:01:05 10 54 video 2212
1.203.177.243 2016-11-10-00:01:18 10 6050 video 7361
1.203.177.243 2016-11-10-00:01:19 10 72 video 7361
1.203.177.243 2016-11-10-00:01:22 10 6050 video 7361
1.30.162.63 2016-11-10-00:01:46 10 54 video 3639
1.84.205.195 2016-11-10-00:01:12 10 54 video 1412
1.85.61.18 2016-11-10-00:01:31 10 54 video 6578
1.85.61.37 2016-11-10-00:01:36 10 54 video 7212
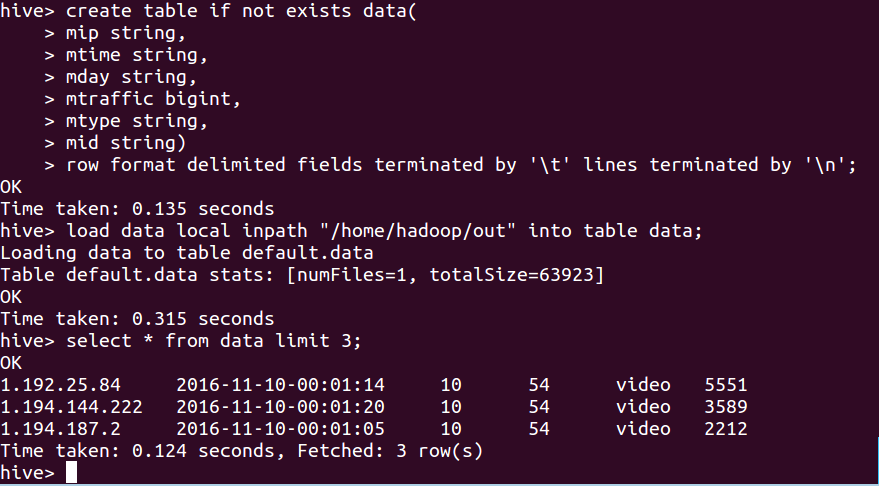
将清洗文件导入hive数据库表:
hive> create table if not exists data(
> mip string,
> mtime string,
> mday string,
> mtraffic bigint,
> mtype string,
> mid string)
> row format delimited fields terminated by '\t' lines terminated by '\n';
OK
Time taken: 0.135 seconds
hive> load data local inpath "/home/hadoop/out" into table data; //注:table后边的data是表名,前一个data不用动
Loading data to table default.data
Table default.data stats: [numFiles=1, totalSize=63923]
OK
Time taken: 0.315 seconds
hive> select * from data limit 3;
OK
1.192.25.84 2016-11-10-00:01:14 10 54 video 5551
1.194.144.222 2016-11-10-00:01:20 10 54 video 3589
1.194.187.2 2016-11-10-00:01:05 10 54 video 2212
Time taken: 0.124 seconds, Fetched: 3 row(s)
hive>
查看数据库表数据:
使用mapreduce清洗简单日志文件并导入hive数据库的更多相关文章
- Weka里如何将arff文件或csv文件批量导入MySQL数据库(六)
这里不多说,直接上干货! 前提博客是 Weka中数据挖掘与机器学习系列之数据格式ARFF和CSV文件格式之间的转换(四) 1.将arff文件批量导入MySQL数据库 我在这里,arff文件以Weka安 ...
- 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
虚拟机: hadoop:3.2.0 hive:3.1.2 win10: eclipse 两阶段数据清洗: (1)第一阶段:把需要的信息从原始日志中提取出来 ip: 199.30.25.88 ti ...
- SQL Server日志文件过大 大日志文件清理方法 不分离数据库
SQL Server日志文件过大 大日志文件清理方法 ,网上提供了很多分离数据库——〉删除日志文件-〉附加数据库 的方法,此方法风险太大,过程也比较久,有时候也会出现分离不成功的现象.下面的方式 ...
- mariadb审计日志通过 logstash导入 hive
我们使用的 mariadb, 用的这个审计工具 https://mariadb.com/kb/en/library/mariadb-audit-plugin/ 这个工具一点都不考虑后期对数据的处理, ...
- 【转】SQL Server日志文件过大 大日志文件清理方法 不分离数据库
https://blog.csdn.net/slimboy123/article/details/54575592 还未测试 USE[master] GO ALTER DATABASE 要清理的数据库 ...
- SQL Server清理大日志文件方法 不分离数据库 执行SQL语句即可
SQL 2008清空日志的SQL语句如下: USE[master] GO ALTER DATABASE 要清理的数据库名称 SET RECOVERY SIMPLE WITH NO_WAIT GO AL ...
- 误删SQL Server日志文件后怎样附加数据库
SQL Server日志文件因为误操作被删除,当附加数据库的时候提示:附加数据库失败. 解决办法如下: 1.新建一个同名数据库. 2.停止数据库服务,覆盖新建的数据库主文件(小技巧:最好放在同一个磁盘 ...
- .frm文件怎么导入到数据库
如题想搞个私服游戏,但是数据库文件按文档的操作方法行不通.只能自行导入. 其实.frm文件就是mysql表结构文件,你拷贝data那一块的文件到你电脑安装的mysql的data文件下就行了. 一.首先 ...
- sql文件批量导入mysql数据库
有一百多个sql文件肿么破?一行一行地导入数据库肯定是极其愚蠢的做法,但是我差点就这么做了... 网上首先找到的方法是:写一个xxx.sql文件,里边每一行都是source *.sql ...,之后再 ...
随机推荐
- tomcat端口修改后在Eclipse中启动无效问题解决
原文:https://blog.csdn.net/yangyiqian/article/details/40262039 问题:在conf目录修改了server.xml配置中的节点 <Conn ...
- display:grid
使用grid布局 参考资料http://www.ruanyifeng.com/blog/2019/03/grid-layout-tutorial.html flex布局还没完全用利索,但这个grid布 ...
- 2019 第一视频java面试笔试题 (含面试题解析)
本人5年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.第一视频等公司offer,岗位是Java后端开发,因为发展原因最终选择去了第一视频,入职一年时间了,也成为了面 ...
- dubbo循序渐进 - 什么是RPC
RPC的核心并不在于使用什么协议.RPC的目的是让你在本地调用远程的方法,而对你来说这个调用是透明的,你并不知道这个调用的方法是部署哪里.通过RPC能解耦服务,这才是使用RPC的真正目的.RPC的原理 ...
- 20、解决Vue使用bus兄弟组件间传值,第一次监听不到数据
1.新建bus.js文件: import Vue from 'vue' export default new Vue; 2.在需要通信组件A,B中引入bus: A组件: import Bus from ...
- html5调用手机震动
在h5里面里面,浏览器对象有个vibrate属性.顾名思义,翻译过来就是震动的意思,这个api属性方法如下: 要调用的例子 if (window.navigator.vibrate) window.n ...
- android studio打印
写入打印语句 System.out.println("hello furong"); 添加打印过滤 指定过滤规则 Filter Name:随便写 Log Tag:日志标志 Log ...
- Java JDBC事务
JDBC默认是自动提交,事务是关闭的,statement|preparedStatement.executeUpdate()或excute()执行增删改,执行一次就提交一次(自动同步到数据库). JD ...
- APP开发基础知识(转载)
来源:https://www.cnblogs.com/wangsea/p/9413672.html 本文针对小白用户对App做一个简单的介绍,首先要了解App都有哪些类型,不同的类型适用于哪些需求,用 ...
- Python卸载不干净?苹果电脑卸载python教程
如今,Pyhon越来越火,屡次超越Java.C++成为编程语言排行榜第一的语言,国内的公司和程序员们也越来越喜欢使用Python.但是Python安装之后,散落在电脑各处,删除起来比较麻烦,很多小伙伴 ...