机器学习(4)——PCA与梯度上升法
主成分分析(Principal Component Analysis)
- 一个非监督的机器学习算法
- 主要用于数据的降维
- 通过降维,可以发现更便于人类理解的特征
- 其他应用:可视化、去噪
通过映射,我们可以把数据从二维降到一维:
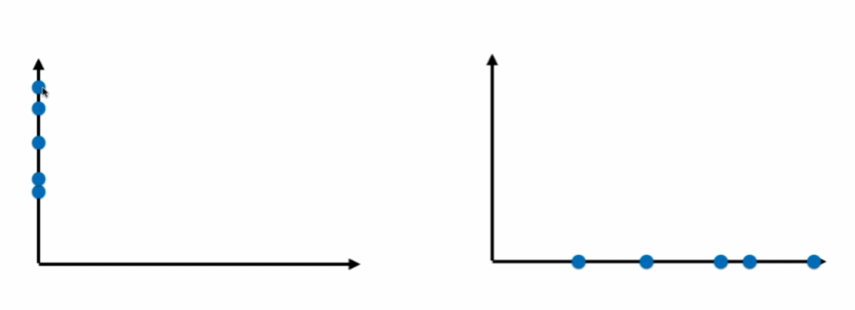
显然,右边的要好一点,因为间距大,更容易看出差距。
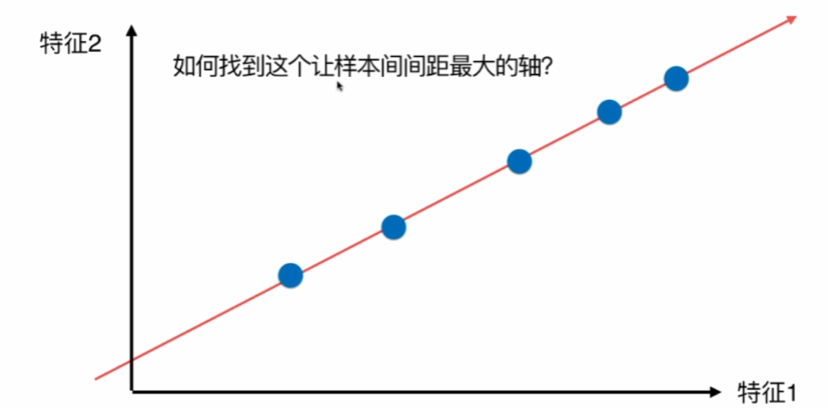
如何定义样本间距?使用方差,因为方差越小,数据月密集,方差越大,数据月分散。
另均值为0:


因为均值为0,w是单位向量,模为1,所以:
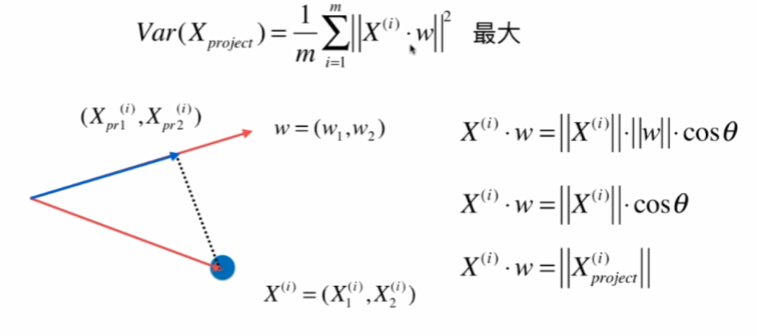

梯度上升法求解PCA问题


分析:X是mn的矩阵,m是样本数,n是特征数,X^(i)是第i个样本,w是n * 1 的矩阵,那么这n个∑X^(i) * w就等于Xw (m行1列)
import numpy as np
import matplotlib.pyplot as plt
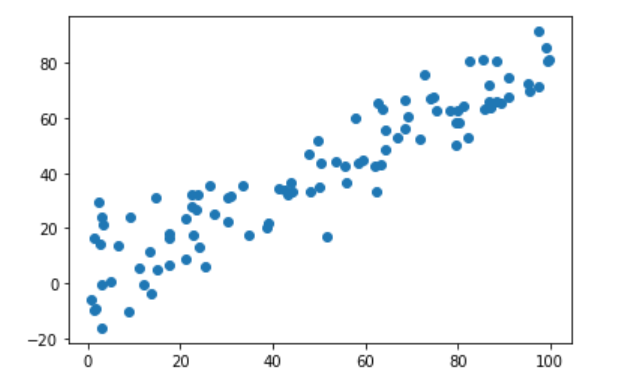
X=np.empty((100,2)) #100行2列
X[:,0]=np.random.uniform(0.,100.,size=100) #100个0~100的均匀分布点
X[:,1]=0.75*X[:,0]+3.+np.random.normal(0,10.,size=100) #100个均值为0,标准差为10的正态分布点
plt.scatter(X[:,0],X[:,1])
plt.show()
demean(每一维的样本均值归0):
def demean(X):
return X-np.mean(X,axis=0)#对X的每一列的每个数减去这一列的均值,即可让X的每一列均值变为0
X_demean=demean(X)
plt.scatter(X_demean[:,0],X_demean[:,1])
plt.show()
np.mean(X_demean[:,0])
np.mean(X_demean[:,1])
发现两个维度的均值都几乎为0。
梯度上升:
def f(w,X):
return np.sum((X.dot(w)**2))/len(X)
def df_math(w,X):
return X.T.dot(X.dot(w))*2./len(X)
def df_debug(w,X,epsilon=0.0001): #调试梯度
res=np.empty(len(w))
for i in range(len(w)):
w_1=w.copy()
w_1[i]+=epsilon
w_2=w.copy()
w_2[i]-=epsilon
res[i]=(f(w_1,X)-f(w_2,X))/(2*epsilon)
return res
def direction(w):#化成单位向量
return w/np.linalg.norm(w) #除以w的模即可
def gradient_ascent(df,X,initial_w,eta,n_iters=1e4,epsilon=1e-8):
#梯度上升法
w=direction(initial_w)
cur_iter=0
while cur_iter < n_iters:
gradient = df(w,X)
last_w=w
w=w+eta*gradient #变成加法
w=direction(w) #注意1:化成单位向量
if(abs(f(w,X)-f(last_w,X))<epsilon):
break
cur_iter+=1
return w
initial_w=np.random.random(X.shape[1]) #注意2:不能用0向量开始,不然求导的时候也是0
eta=0.001
#注意3:不能使用StandardScaler标准化数据,因为我们要使方差最大,而不是为1
gradient_ascent(df_debug,X_demean,initial_w,eta) #调试求出的梯度
gradient_ascent(df_math,X_demean,initial_w,eta)#推导的公式求梯度
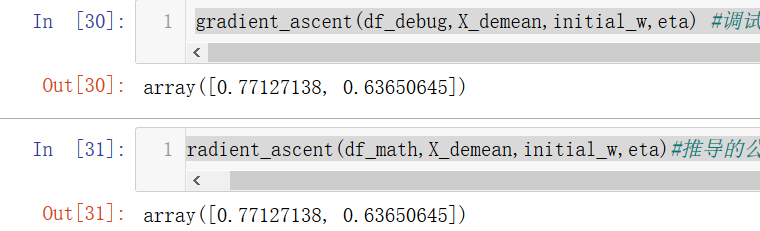
发现一模一样,说明求导公式是正确的。
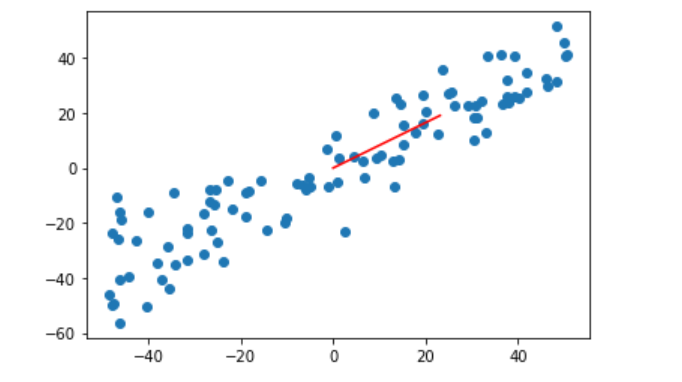
w=gradient_ascent(df_math,X_demean,initial_w,eta)#推导的公式求梯度
plt.scatter(X_demean[:,0],X_demean[:,1])
plt.plot([0,w[0]*30],[0,w[1]*30],color="r")
#第一个参数是横坐标数组,第二个参数是纵坐标数组,因为w是单位向量,太小了,所以*30变大一点
plt.show()
测试一下不加噪音是否正确:
X2=np.empty((100,2)) #100行2列
X2[:,0]=np.random.uniform(0.,100.,size=100) #100个0~100的均匀分布点
X2[:,1]=0.75*X2[:,0]+3.#不加噪音
plt.scatter(X2[:,0],X2[:,1])
plt.show()
X2_demean=demean(X2)
gradient_ascent(df_math,X2_demean,initial_w,eta)
w2=gradient_ascent(df_math,X2_demean,initial_w,eta)
plt.scatter(X2_demean[:,0],X2_demean[:,1])
plt.plot([0,w2[0]*30],[0,w2[1]*30],color="r")
plt.show()
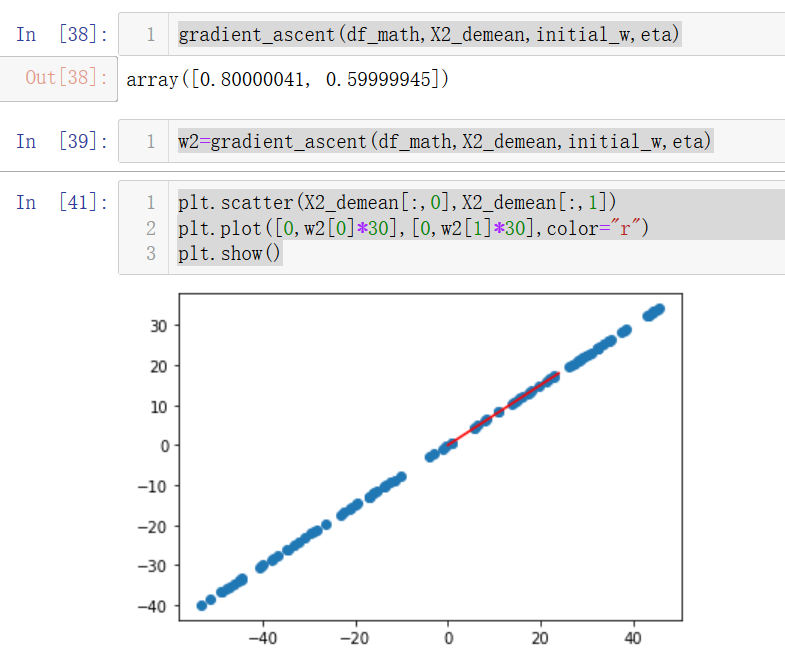
因为我们设置的斜率是0.75,而这里求出的w=[0.8,0.6],对边/斜边=0.75,说明梯度上升是正确的。
求数据的前n个主成分
求出第一个主成分以后,如何求出下一个主成分?
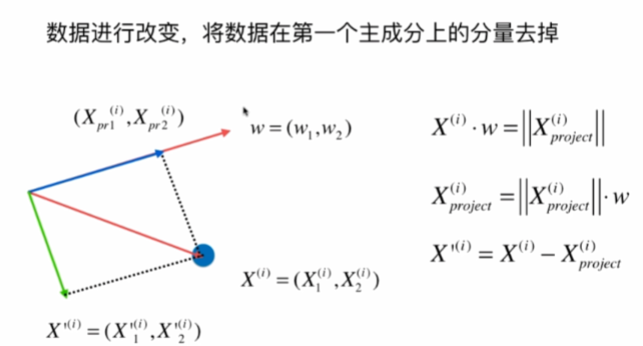
数据进行改变,将数据在第一个主成分上的分量去掉,再在新的数据求第一主成分。
numpy中一维数组的运算的一些奇妙的地方:
https://blog.csdn.net/xo3ylAF9kGs/article/details/78623276
import numpy as np
import matplotlib.pyplot as plt
X=np.empty((100,2)) #100行2列
X[:,0]=np.random.uniform(0.,100.,size=100) #100个0~100的均匀分布点
X[:,1]=0.75*X[:,0]+3.+np.random.normal(0,10.,size=100) #100个均值为0,标准差为10的正态分布点
def demean(X):
return X-np.mean(X,axis=0)#对X的每一列的每个数减去这一列的均值,即可让X的每一列均值变为0
X=demean(X)
def f(w,X):
return np.sum((X.dot(w)**2))/len(X)
def df(w,X):
return X.T.dot(X.dot(w))*2./len(X)
def direction(w):#化成单位向量
return w/np.linalg.norm(w) #除以w的模即可
def first_component(X,initial_w,eta,n_iters=1e4,epsilon=1e-8):
#梯度上升法
w=direction(initial_w)
cur_iter=0
while cur_iter < n_iters:
gradient = df(w,X)
last_w=w
w=w+eta*gradient #变成加法
w=direction(w) #注意1:化成单位向量
if(abs(f(w,X)-f(last_w,X))<epsilon):
break
cur_iter+=1
return w
initial_w=np.random.random(X.shape[1])
eta=0.01
w=first_component(X,initial_w,eta)
X2=X-X.dot(w).reshape(-1,1)*w #点积后变成m行1列再和w数组(n个元素)每个元素对应相乘,形成m行n列的矩阵
plt.scatter(X2[:,0],X2[:,1])
plt.show()
对第二维主成分分析的结果:

w2=first_component(X2,initial_w,eta)
w2
w.dot(w2)

点积之后几乎为0,说明是正确的,因为两个方向是垂直的。
求前n个主成分:
def first_n_components(n,X,eta=0.01,n_iters=1e4,epsilon=1e-8):
X_pca=X.copy()
X_pca=demean(X_pca)
res=[]
for i in range(n):
initial_w=np.random.random(X_pca.shape[1])
w=first_component(X_pca,initial_w,eta)
res.append(w)
X_pca=X_pca-X_pca.dot(w).reshape(-1,1)*w
return res
first_n_components(2,X)

高维数据向低维数据映射
将n为数据映射到k维
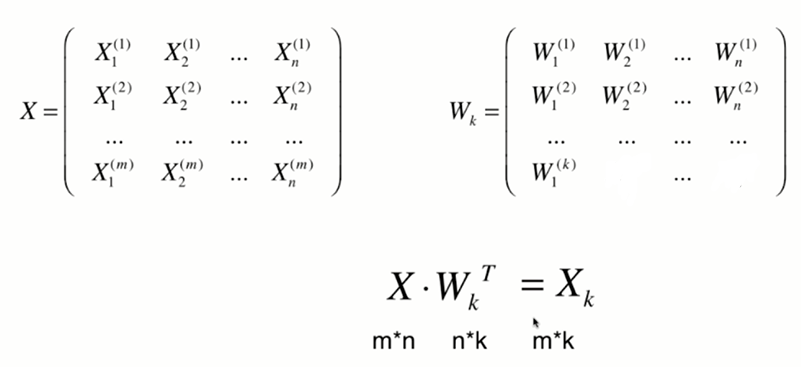
将k维数据恢复到n维:
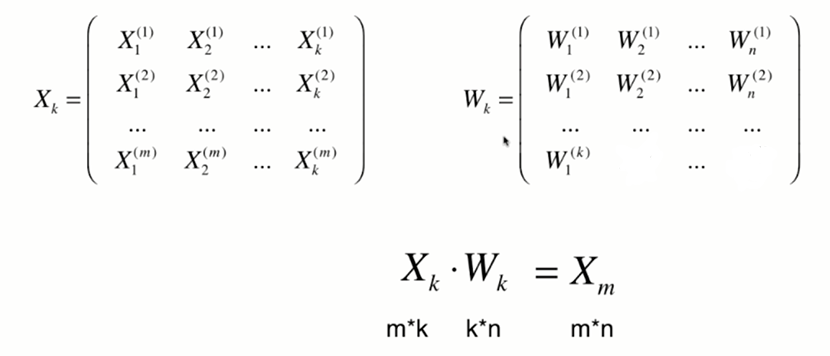
import numpy as np
class PCA:
def __init__(self, n_components):
"""初始化PCA"""
assert n_components >= 1, "n_components must be valid"
self.n_components = n_components
self.components_ = None
def fit(self, X, eta=0.01, n_iters=1e4):
"""获得数据集X的前n个主成分"""
assert self.n_components <= X.shape[1], \
"n_components must not be greater than the feature number of X"
def demean(X):
return X - np.mean(X, axis=0)
def f(w, X):
return np.sum((X.dot(w) ** 2)) / len(X)
def df(w, X):
return X.T.dot(X.dot(w)) * 2. / len(X)
def direction(w):
return w / np.linalg.norm(w)
def first_component(X, initial_w, eta=0.01, n_iters=1e4, epsilon=1e-8):
w = direction(initial_w)
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w)
if (abs(f(w, X) - f(last_w, X)) < epsilon):
break
cur_iter += 1
return w
X_pca = demean(X)
self.components_ = np.empty(shape=(self.n_components, X.shape[1]))
for i in range(self.n_components):
initial_w = np.random.random(X_pca.shape[1])
w = first_component(X_pca, initial_w, eta, n_iters)
self.components_[i,:] = w
X_pca = X_pca - X_pca.dot(w).reshape(-1, 1) * w
return self
def transform(self, X):
"""将给定的X,映射到各个主成分分量中"""
assert X.shape[1] == self.components_.shape[1]
return X.dot(self.components_.T)
def inverse_transform(self, X):
"""将给定的X,反向映射回原来的特征空间"""
assert X.shape[1] == self.components_.shape[0]
return X.dot(self.components_)
def __repr__(self):
return "PCA(n_components=%d)" % self.n_components
import numpy as np
import matplotlib.pyplot as plt
X=np.empty((100,2)) #100行2列
X[:,0]=np.random.uniform(0.,100.,size=100) #100个0~100的均匀分布点
X[:,1]=0.75*X[:,0]+3.+np.random.normal(0,10.,size=100) #100个均值为0,标准差为10的正态分布点
%run f:\python3玩转机器学习\PCA与梯度上升法\PCA.py
pca=PCA(n_components=2)
pca.fit(X)
pca=PCA(n_components=1)
pca.fit(X)
X_reduction=pca.transform(X)
X_restore=pca.inverse_transform(X_reduction)

plt.scatter(X[:,0],X[:,1],color="b",alpha=0.5)
plt.scatter(X_restore[:,0],X_restore[:,1],color='r',alpha=0.5)
plt.show()
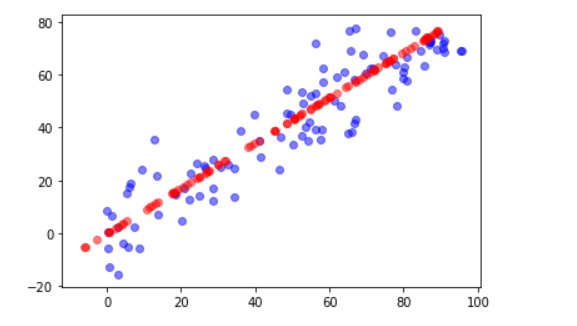
红色的线是恢复后的数据,可见丢失了一些信息。
scikit-learn中的PCA
先接着用上面的数据,
from sklearn.decomposition import PCA
pca = PCA(n_components=1)
pca.fit(X)
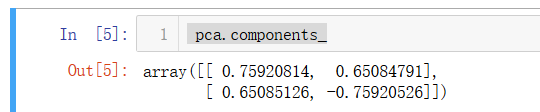
pca.components_

咦?怎么跟我们上面求的第一主成分不太一样,但是斜率是差不多的,这是因为scikit-learn中的PCA是通过数学推导的,不是我们上面用的梯度上升法。
X_reduction=pca.transform(X)
X_restore=pca.inverse_transform(X_reduction)
plt.scatter(X[:,0],X[:,1],color="b",alpha=0.5)
plt.scatter(X_restore[:,0],X_restore[:,1],color="r",alpha=0.5)
plt.show()
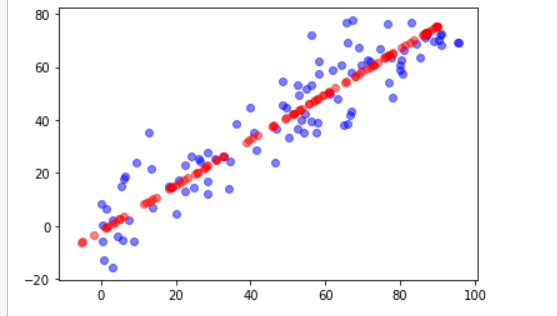
最后绘制出来的图跟上面的方法是差不多的。
再玩一下手写字母识别这个数据集:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
digits=datasets.load_digits()
X=digits.data
y=digits.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=666)
%%time
from sklearn.neighbors import KNeighborsClassifier
knn_clf=KNeighborsClassifier()
knn_clf.fit(X_train,y_train)

knn_clf.score(X_test,y_test)

直接降到二维试试(斜眼笑):
from sklearn.decomposition import PCA
pca=PCA(n_components=2) #从64维降到2维
pca.fit(X_train)
X_train_reduction=pca.transform(X_train)
X_test_reduction=pca.transform(X_test)
%%time
knn_clf=KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)

哇!居然只用了1ms。
knn_clf.score(X_test_reduction,y_test)

但这正确率也太低了吧。。。虽然运行速度提高了,但精度低了。
pca.explained_variance_ratio_ #这两维显示所占的方差比,大概只有28%,所以精度很低

先直接算一下64维各维方差占比的情况:
pca=PCA(n_components=X_train.shape[1])
pca.fit(X_train)
pca.explained_variance_ratio_ #从大到小排序的
plt.plot([i for i in range(X_train.shape[1])],
[np.sum(pca.explained_variance_ratio_[:i+1]) for i in range(X_train.shape[1])])
plt.show()
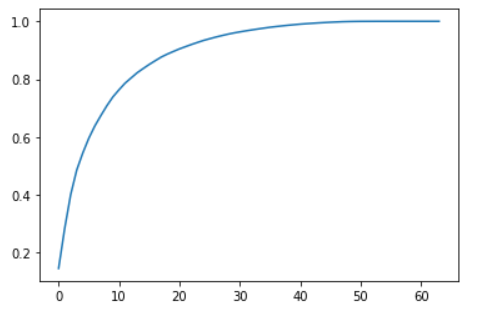
横轴为维度,纵轴为我们需要的方差占比。
如果我们想要方差占比0.95:
pca=PCA(0.95)
pca.fit(X_train)
pca.n_components_
输出28,所以我们要用PCA降到28维:
X_train_reduction=pca.transform(X_train)
X_test_reduction=pca.transform(X_test)
%%time
knn_clf=KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)

好快啊!
knn_clf.score(X_test_reduction,y_test)

正确率也好高啊!!!
看来28维足以兼并精度和时间~
我们再看看PCA降到二维可视化:
pca=PCA(n_components=2)
pca.fit(X)
X_reduction=pca.transform(X)
for i in range(10):
plt.scatter(X_reduction[y==i,0],X_reduction[y==i,1],alpha=0.8)#每次循环自动换颜色
plt.show()
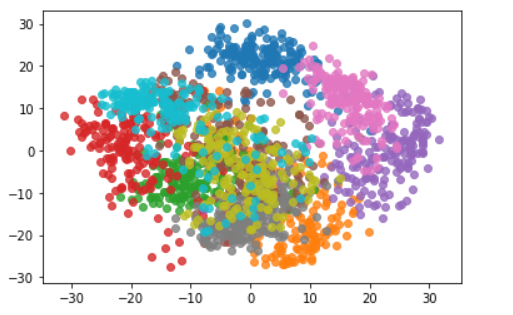
可以发现不同的类别降到二维后还是可以区分的,比如我们需要区分粉色和紫色,那么降到二维就足够应对了。
MNIST数据集
下载MNIST数据集可能会出现超时状况,解决办法:https://blog.csdn.net/qq_41312839/article/details/86671939
import numpy as np
from sklearn.datasets import fetch_mldata
mnist=fetch_mldata("MNIST original")
X,y=mnist['data'],mnist['target']
X_train=np.array(X[:60000],dtype=float)#mnist数据集前60000个是训练数据
y_train=np.array(y[:60000],dtype=float)
X_test=np.array(X[60000:],dtype=float)
y_test=np.array(y[60000:],dtype=float)
from sklearn.neighbors import KNeighborsClassifier
knn_clf=KNeighborsClassifier() #scikit-learn中的KNN对于数据大时会使用KD-tree或BALL-tree来加速
%time knn_clf.fit(X_train,y_train)
%time knn_clf.score(X_test,y_test)
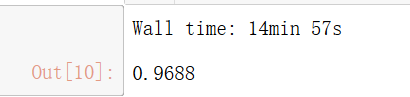
预测时间是真的太长了。。我们再看看PCA降维的结果吧:
from sklearn.decomposition import PCA
pca=PCA(0.9)#保留90%的信息
pca.fit(X_train)
X_train_reduction=pca.transform(X_train)
knn_clf=KNeighborsClassifier()
%time knn_clf.fit(X_train_reduction,y_train)
X_test_reduction=pca.transform(X_test)
%time knn_clf.score(X_test_reduction,y_test)
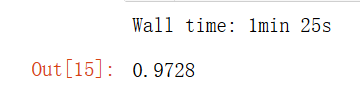
可以发现,降维后时间提高了很多,准确率居然也上升了,这是因为PCA具有降噪的功能。
PCA还可以应用于手写识别、人脸识别领域。
机器学习(4)——PCA与梯度上升法的更多相关文章
- 机器学习(七) PCA与梯度上升法 (上)
一.什么是PCA 主成分分析 Principal Component Analysis 一个非监督学的学习算法 主要用于数据的降维 通过降维,可以发现更便于人类理解的特征 其他应用:可视化:去噪 第一 ...
- 机器学习(七) PCA与梯度上升法 (下)
五.高维数据映射为低维数据 换一个坐标轴.在新的坐标轴里面表示原来高维的数据. 低维 反向 映射为高维数据 PCA.py import numpy as np class PCA: def __ini ...
- 4.pca与梯度上升法
(一)什么是pca pca,也就是主成分分析法(principal component analysis),主要是用来对数据集进行降维处理.举个最简单的例子,我要根据姓名.年龄.头发的长度.身高.体重 ...
- 第7章 PCA与梯度上升法
主成分分析法:主要作用是降维 疑似右侧比较好? 第三种降维方式: 问题:????? 方差:描述样本整体分布的疏密的指标,方差越大,样本之间越稀疏:越小,越密集 第一步: 总结: 问题:????怎样使其 ...
- 机器学习:PCA(使用梯度上升法求解数据主成分 Ⅰ )
一.目标函数的梯度求解公式 PCA 降维的具体实现,转变为: 方案:梯度上升法优化效用函数,找到其最大值时对应的主成分 w : 效用函数中,向量 w 是变量: 在最终要求取降维后的数据集时,w 是参数 ...
- 机器学习:PCA(高维数据映射为低维数据 封装&调用)
一.基础理解 1) PCA 降维的基本原理 寻找另外一个坐标系,新坐标系中的坐标轴以此表示原来样本的重要程度,也就是主成分:取出前 k 个主成分,将数据映射到这 k 个坐标轴上,获得一个低维的数据集. ...
- 机器学习:PCA(基础理解、降维理解)
PCA(Principal Component Analysis) 一.指导思想 降维是实现数据优化的手段,主成分分析(PCA)是实现降维的手段: 降维是在训练算法模型前对数据集进行处理,会丢失信息. ...
- 机器学习算法-PCA降维技术
机器学习算法-PCA降维 一.引言 在实际的数据分析问题中我们遇到的问题通常有较高维数的特征,在进行实际的数据分析的时候,我们并不会将所有的特征都用于算法的训练,而是挑选出我们认为可能对目标有影响的特 ...
- 机器学习算法的调试---梯度检验(Gradient Checking)
梯度检验是一种对求导结果进行数值检验的方法,该方法可以验证求导代码是否正确. 1. 数学原理 考虑我们想要最小化以 θ 为自变量的目标函数 J(θ)(θ 可以为标量和可以为矢量,在 Numpy 的 ...
随机推荐
- STL关联容器的基本操作
关联容器 map,set map map是一种关联式容器包含 键/值 key/value 相当于python中的字典不允许有重复的keymap 无重复,有序 Map是STL的一个关联容器,它提供一对一 ...
- java的加载与运行
jdk中有一个javac.exe(java编译器) *Java程序的运行包括两非常重要的阶段 -编译阶段 -运行阶段 *编译阶段 -主要任务是检查Java源程序是否符合Java语法 符合Java语法则 ...
- RFM模型的应用 - 电商客户细分(转)
RFM模型是网点衡量当前用户价值和客户潜在价值的重要工具和手段.RFM是Rencency(最近一次消费),Frequency(消费频率).Monetary(消费金额) 消费指的是客户在店铺消费最近一次 ...
- Special-Judge模板
SPJ模板 放一篇\(SPJ\)(\(Special-Judge\))的模板. 注意,仅适用于\(Lemon\). 并不适用于洛谷. 代码:@zcs0724 #include <bits/std ...
- Vue 变异方法splice删除评论功能
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Codeforces Round #553 (Div. 2) C 等差数列求和 + 前缀和
https://codeforces.com/contest/1151/problem/C 题意 有两个等差数列(1,3,5,..),(2,4,6,...),两个数列轮流取1,2,4,...,\(2^ ...
- Paper | A novel deep learning-based method of improving coding efficiency from the decoder-end for HEVC
目录 精彩叙述 细节 发表在2017年DCC. 这篇文章立意很简单,方法也很简单,但是做得早.效果好.引用量也不错(40+). 指标:在HEVC的intra.LDP.LDB和RA模式下,BDBR平均可 ...
- 第02组 Beta冲刺(2/5)
队名:無駄無駄 组长博客 作业博客 组员情况 张越洋 过去两天完成了哪些任务 数据库实践 提交记录(全组共用) 接下来的计划 加快校园百科的进度 还剩下哪些任务 学习软工的理论课 学习代码评估.测试 ...
- C++中enum(转载)
原文地址:http://www.cnblogs.com/ForFreeDom/archive/2012/03/22/2412055.html 1.为什么要用enum 写程序时,我们常常需要 ...
- java.util.concurrent各组件分析 一 sun.misc.Unsafe
java.util.concurrent各组件分析 一 sun.misc.Unsafe 说到concurrent包也叫并发包,该包下主要是线程操作,方便的进行并发编程,提到并发那么锁自然是不可缺少的, ...