[数据结构 - 第3章] 线性表之单链表(C++实现)
一、类定义
单链表类的定义如下:
#ifndef SIGNALLIST_H
#define SIGNALLIST_H
typedef int ElemType; /* "ElemType类型根据实际情况而定, 这里假设为int */
/* 线性表的单链表存储结构 */
typedef struct node
{
ElemType data; // 数据域
struct node *next; // 指针域
}Node, LinkList;
class SignalList
{
public:
SignalList(int size = 0); // 构造函数
~SignalList(); // 析构函数
void clearList(); // 清空顺序表操作
bool isEmpty(); // 判断是否为空操作
int getLength(); // 获取顺序表长度操作
bool insertList(int i, const ElemType e); // 插入元素操作
bool deleteList(int i, ElemType *e); // 删除元素操作
bool getElem(int i, ElemType *e); // 获取元素操作
bool insertListHead(const ElemType e); // 头部后插入元素操作
bool insertListTail(const ElemType e); // 尾部后插入元素操作
void traverseList(); // 遍历顺序表
int locateElem(const ElemType e); // 查找元素位置操作
private:
LinkList *m_pList; // 单链表指针
};
#endif
二、构造函数
为头结点m_pList申请内存,数据域置为 0,指针域指向空。
// 构造函数
SignalList::SignalList(int size)
{
// 初始化单链表
m_pList = new Node;
m_pList->data = 0;
m_pList->next = NULL;
}
三、析构函数
调用清空单链表方法,并且销毁头结点。
// 析构函数
SignalList::~SignalList()
{
clearList(); // 清空单链表
delete m_pList;
m_pList = NULL;
}
四、清空链表操作
循环销毁除头结点外的各结点。
// 清空链表操作
void SignalList::clearList()
{
Node *cur; // 当前结点
Node *temp; // 事先保存下一结点,防止释放当前结点后导致“掉链”
cur = m_pList->next; //指向第一个结点
while (cur)
{
temp = cur->next; // 事先保存下一结点,防止释放当前结点后导致“掉链”
delete cur; // 释放当前结点
cur = temp; // 将下一结点赋给当前结点
}
cur->next = NULL; // 注意还要将头结点的指针域指向空
}
清空链表和析构函数的区别:清空链表是循环销毁除头结点外的各结点,析构函数是销毁所有结点,包括头结点。
五、判空和获取顺序表长度操作
// 判断是否为空操作
bool SignalList::isEmpty()
{
return m_pList->next == NULL ? true : false;
}
// 获取链表长度操作
int SignalList::getLength()
{
Node *cur = m_pList;
int length = 0;
while (cur->next)
{
cur = cur->next;
length++;
}
return length;
}
六、插入元素操作
注意这里是有头结点,头结点作为位置 0,所以只能在位置 1 以及后面插入,所以 i 至少为1。
// 插入元素操作
bool SignalList::insertList(int i, const ElemType e)
{
// 判断链表是否存在
if (!m_pList)
{
cout << "list not exist!" << endl;
return false;
}
// 只能在位置1以及后面插入,所以i至少为1
if (i < 1)
{
cout << "i is invalid!" << endl;
return false;
}
// 找到i位置所在的前一个结点
Node *front = m_pList; // 这里是让front与i不同步,始终指向j对应的前一个结点
for (int j = 1; j < i; j++) // j为计数器,赋值为1,对应front指向的下一个结点,即插入位置结点
{
front = front->next;
if (front == NULL)
{
printf("dont find front!\n");
return false;
}
}
// 创建一个空节点,存放要插入的新元素
Node *temp = new Node;
temp->data = e;
temp->next = NULL;
// 插入结点s
temp->next = front->next;
front->next = temp;
return true;
}
七、删除元素操作
注意提前保存要删除的结点,避免删除结点后丢失。
// 删除元素操作
bool SignalList::deleteList(int i, ElemType *e)
{
// 判断链表是否存在
if (!m_pList)
{
cout << "list not exist!" << endl;
return false;
}
// 只能删除位置1以及后面的结点
if (i < 1)
{
cout << "i is invalid!" << endl;
return false;
}
// 找到i位置所在的前一个结点
Node *front = m_pList; // 这里是让front与i不同步,始终指向j对应的前一个结点
for (int j = 1; j < i; j++) // j为计数器,赋值为1,对应front指向的下一个结点,即插入位置结点
{
front = front->next;
if (front->next == NULL)
{
printf("dont find front!\n");
return false;
}
}
// 提前保存要删除的结点
Node *temp = front->next;
*e = temp->data; // 将要删除结点的数据赋给e
// 删除结点
front->next = front->next->next;
// 销毁结点
delete temp;
temp = NULL;
return true;
}
八、遍历操作
遍历前需要判断链表是否存在。
// 遍历链表
void SignalList::traverseList()
{
// 判断链表是否存在
if (!m_pList)
{
cout << "list not exist!" << endl;
return;
}
Node *cur = m_pList->next;
while (cur)
{
cout << cur->data << " ";
cur = cur->next;
}
}
九、主函数执行
在主函数中执行的代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include "signalList.h"
using namespace std;
int main()
{
// 初始化链表
SignalList signleList(20);
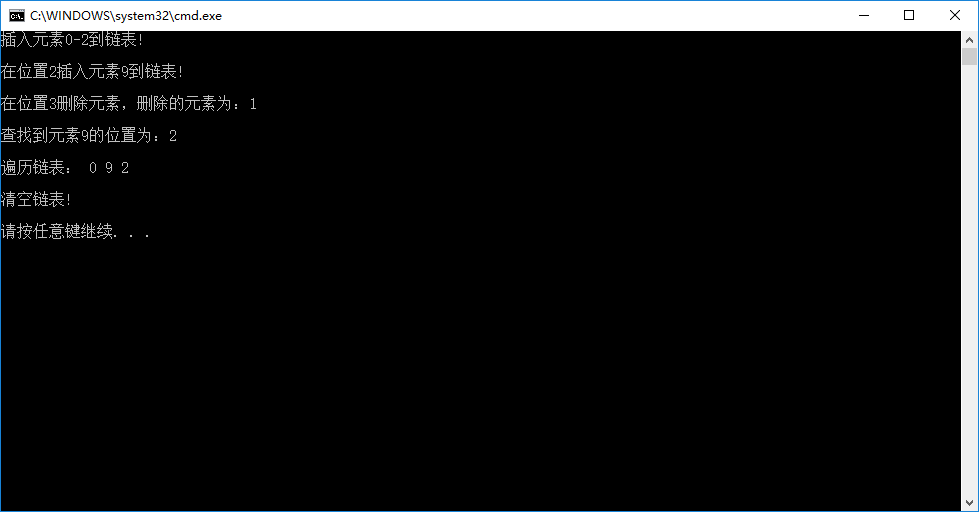
cout << "插入元素0-2到链表!" << endl;
for (int i = 0; i<3; i++)
{
signleList.insertList(i+1, i);
}
cout << endl;
// 在位置2插入元素9到链表
cout << "在位置2插入元素9到链表!" << endl << endl;
signleList.insertList(2, 9);
// 在位置3删除元素
int value1;
if (signleList.deleteList(3, &value1) == false)
{
cout << "delete error!" << endl;
return -1;
}
else
{
cout << "在位置3删除元素,删除的元素为:" << value1 << endl << endl;
}
// 查找元素位置
int index = signleList.locateElem(9);
if (index == -1)
{
cout << "locate error!" << endl;
return -1;
}
else
{
cout << "查找到元素9的位置为:" << index << endl << endl;
}
// 遍历链表
cout << "遍历链表: ";
signleList.traverseList();
cout << endl << endl;
// 清空链表
cout << "清空链表!" << endl << endl;
signleList.clearList();
return 0;
}
输出结果如下图所示(编译器为VS2013):
[数据结构 - 第3章] 线性表之单链表(C++实现)的更多相关文章
- 线性表之单链表C++实现
线性表之单链表 一.头文件:LinkedList.h //单链表是用一组任意的存储单元存放线性表的元素,这组单元可以是连续的也可以是不连续的,甚至可以是零散分布在内存中的任意位置. //单链表头文件 ...
- 【Java】 大话数据结构(2) 线性表之单链表
本文根据<大话数据结构>一书,实现了Java版的单链表. 每个结点中只包含一个指针域的链表,称为单链表. 单链表的结构如图所示: 单链表与顺序存储结构的对比: 实现程序: package ...
- [数据结构 - 第3章] 线性表之双向链表(C语言实现)
一.什么是双向链表? 双向链表(double linked list)是在单链表的每个结点中,再设置一个指向其前驱结点的指针域.所以在双向链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前 ...
- Java数据结构-线性表之单链表LinkedList
线性表的链式存储结构,也称之为链式表,链表:链表的存储单元能够连续也能够不连续. 链表中的节点包括数据域和指针域.数据域为存储数据元素信息的域,指针域为存储直接后继位置(一般称为指针)的域. 注意一个 ...
- [C++]数据结构:线性表之(单)链表
一 (单)链表 ADT + Status InitList(LinkList &L) 初始化(单)链表 + void printList(LinkList L) 遍历(单)链表 + int L ...
- 数据结构(java版)学习笔记(三)——线性表之单链表
单链表的优点: 长度不固定,可以任意增删. 单链表的缺点: 存储密度小,因为每个数据元素,都需要额外存储一个指向下一元素的指针(双链表则需要两个指针). 要访问特定元素,只能从链表头开始,遍历到该元素 ...
- 续上文----线性表之单链表(C实现)
本文绪上文线性表之顺序表(C实现) 本文将继续使用单链表实现线性表的另外一种存储结构.这种使用链表实现的存储结构在内存中是不连续的. C实现代码如下: #include<stdio.h> ...
- 线性表 (单链表、循环链表-python实现)
一.线性表 线性表的定义: 线性表是具有相同数据类型的有限数据的序列. 线性表的特点: 出了第一个元素外,每个元素有且仅有一个直接前驱,除最后一个元素外有且只有一个后继. 线性表是一种逻辑结构,表示元 ...
- [数据结构 - 第3章] 线性表之顺序表(C++实现)
一.类定义 顺序表类的定义如下: #ifndef SEQLIST_H #define SEQLIST_H typedef int ElemType; /* "ElemType类型根据实际情况 ...
随机推荐
- MySQL中的内连接、左连接、右连接、全连接、交叉连接
创建两个表(a_table.b_table),两个表的关联字段分别为:a_table.a_id和b_table.b_id CREATE TABLE a_table ( a_id int NOT NUL ...
- cf1191 解题报告
cf1191 解题报告 A-简单模拟 脑内算出来让计算机输出 #include <bits/stdc++.h> #define ll long long using namespace s ...
- NOI2019 Day1游记
Day1挂了,没什么好说的... 开场T1想到70分暴力就走人了,后来发现可以写到85...(听说有人写dfs过了95?233333) T2刚了2个多小时,得到每次只在中间填最大值的结论后不会区间DP ...
- 大厂HR面试必备ES6中的深入浅出面试题知识点
ESMAScript6简介,ES6是JavaScript语言的下一代标准,目的是让JavaScript语言可以写复杂的大型应用程序,成为企业级语言.那么ECMAScript和JavaScript的关系 ...
- 设置Git--在Git中设置您的用户名--创建一个回购--Fork A Repo--社会化
设置Git GitHub的核心是名为Git的开源版本控制系统(VCS).Git负责计算机上本地发生的所有GitHub相关的事情. 要在命令上使用Git,您需要在计算机上下载,安装和配置Git. 如果要 ...
- Mongoose 两个表关联查询aggregate 以及 Mongoose中获取ObjectId
Mongoose 两个表关联查询aggregate 通常两个表关联查询的时候,是一种一对多的关系,比如订单与订单详情就是一对多的关系,一个订单下面有多个商品 数据模拟 首先我们先将数据模拟出来,先选择 ...
- node解析修改ngix配置文件
主要是通过nginx-conf这个工具. git地址:https://github.com/tmont/nginx-conf 具体用法: npm install -S nginx-conf 安装工具 ...
- CAP原则 (阿里)
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency).可用性(Availability).分区容错性(Partition tolerance).CAP 原则指的是,这三 ...
- Excel填坑[0]
Excel填坑[0] 本着一天水一贴的原则(放p),我又来填坑了.今天做一个很简单的排队图,虽然不难,但因为手机显示问题折腾了半天.感觉做图做表格不仅仅是靠技术,更重要的是思维. 就是这张图,看起来平 ...
- 七年老运维实战中的 Shell 开发经验总结【转】
无论是系统运维,还是应用运维,均可分为“纯手工”—> “脚本化”—> “自动化”—>“智能化”几个阶段,其中自动化阶段,主要是将一些重复性人工操作和运维经验封装为程序或脚本,一方面避 ...