python05-09
一、lambda表达式
def f1():
return 123
f2 = lambda : 123 def f3 = (a1,a2):
return a1+a2
f4 = lambda a1,a2 : a1+a2

二、内置函数
1、 abs()取绝对值
all()所有,需要给我传一个可以迭代的东西,给我的所有的值都为真,返回True
any()只要有一个为真就是真
ascii(对象)去对象的类中,找__repr__方法获取其返回值

ascii的执行过程:ascii对象找到类,找到def函数,使用__repr__方法,最后返回一个hello
2、 bin()#二进制 r = bin(11)十进制转二进制
oct()#八进制
int()#十进制
hex()#十六进制
进制转换:
i = int("0b11",base=2)#二进制转换十进制
i = int("11",base=8)#八进制转换成十进制
.......
3、bool,判断真假,把一个对象转换成布尔值:
4、 bytes 字节
bytearray 字节列表(元素是字节)
字节、字符串转换
bytes("xxxx",encoding="utf-8")
5、chr():c = chr(65) print(c)>>>A;c = chr(66) print(c)>>>B
ord():i = ord("t") print(i)>>>116
#一个字节=8位,共256种可能
随机验证码:
#生成一个随机数,65-91
#数字转换成字母,chr(数字)(数字是随机生成的,所有这个生成的字母也是随机的)
#
import random#导入随机数的模块 temp = ""#temp等于一个空的字符串
for i in range(6):
num = random.randrange(0,10)#随机数0-9
if num == 3 or num ==6:#如果系统产生的随机数是3或者是6则执行if(产生数字),如果不是则执行else产生字母
rad2 = random.randrange(0,10)#rad2是数字类型
temp = temp + str(rad2) else:
rad1 = random.randrange(65, 91) # 生成65到90的随机的数字
c1 = chr(rad1) # 将rad1生成的随机数字转换成一个随机的字母 temp = temp + c1
print(temp)
6、callable()#是否可以被执行
7、divmod()#
r = divmod(10, 3)
print(r)
>>>(3, 1)3余1
8、enumerate参数为可遍历的变量,如字符串,列表等,返回值为enumerate类
函数用于遍历序列中的元素以及他们的下标
例1:
for i,j in enumerate(('a','b','c')):
print(i,j)
结果
0 a
1 b
2 c
例2:
for i,j in enumerate({'a':1,'b':2}):
print(i,j)
结果:
0 a
1 b
注:字典在遍历的时候,循环的是keys,然后通过enumerate方法给每一个key加索引,
9、eval():将字符串当成有效表达式来求值并返回计算结果
ret = eval(" a + 60",{"a" : 99})
print()
>>>159
exec("for i in range(10):print(i)")#执行py代码没有返回值
>>>0
1
2
3
.
.
.
9
10、filter(函数,可以迭代的对象)(过滤)
循环可以迭代的对象,获取每一个参数,并让其执行函数

def f1(x):
if x > 22:
return Ture
else:
return False
ret = filter(f1, [11,22,33,225])
for i in ret:
print(i)
>>>33
225 def f1(x):
return x > 22
ret = filter(lambda x: x > 22, [11,22,33,225])
for i in ret:
print(i)
>>>33
225
map(函数,可以迭代的对象)
def f1(x):
return x + 100
ret = map(f1, [1,2,3,4,5])
print(ret)#直接打印会报错,这里需要用for迭代输出
for i in ret:
print()
>>>101
102
103
104
105 def f1(x):
return x + 100
ret = map(lambda x: x + 100, [1,2,3,4,5])
for i in ret:
print()
11、global()全局变量
local()局部变量
12、isinstance()判断某个对象是否是某个类创建的
li = [11,22]
r = isinstance(li, list)
print(r) >>True
13、iter()
obj = iter([11,22,33,44])
print(obj)
>>>
<list_iterator object at 0x0000000000B59438>
r1 = next(obj)
print(r1)
>>>11
r2 = next(obj)
print(r2)
>>>22
14、 round()四舍五入
15、slice()
16、sum()求和
r = sum([11,22,33,44])
print(r)
>>>110
17zip()
li1 = [11,22,33,44]
li2 = ["a","bb","c","e"]
r = zip(li1,li2)
#print(r)
for i in r:
print(i)
>>>
(11, 'a')
(22, 'bb')
(33, 'c')
(44, 'e')
18、排序
li = [1,211,22,3,4]
print(li)
>>>[1,211,22,3,4]
li.sort()
print(li)
>>>[1,3,4,22,211]
三、文件操作
- 打开文件
- 操作文件
- 关闭文件
open(文件名/文件路径,模式,编码)
1、基本的打开方式(字符串的形式打开的文件)当文件中有汉字会报错要加上文件内容的编码
在基本打开方式是可以加encoding="utf-8"

"+"表示可以同时读写摸个文件
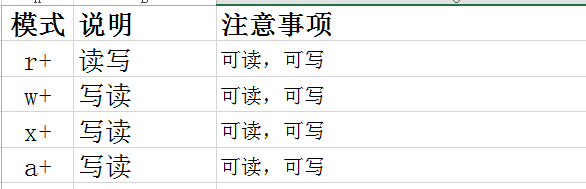
r+的形式打开
从头开始读取内容
w的时候是在末尾追加,指针到最后
注意:
读,从零开始读
写:
先读最后追加
主动seek,写从当前的seek指针到的位置开始写入
w+先清空,再写入,你可以读新写入的内容,写了之后指针到最后
从开始往后读
x+文件存在报错
a+打开的同时,将指针移至最后,写的时候也是在最后追加,指针到最后
2、以字节的方式打开 rb
以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型
f = open("ha.log","rb",encoding="utf-8")
data = f.read()
f.colse()
print(data)
print(type(data))
只写wb
f = open("ha.log","wb")
#f.write("中国")要求以字节的方式写入,给了一个字符串要进行类型转换
f.write(bytes("中国",encoding = "utf-8"))
f.close
注:(带着b的自己转换不带b,python自己转换)
write写入的时候要是字节
data = read()也是字节
普通方式打开
python内部将010101010==》转换成字符串、通过字符串操作
左边010101 中间是python解释器 程序员
二进制方式打开

f.tell()#获取指针位置
f.seek()#调整指针位置
3.2文件操作
class TextIOWrapper(_TextIOBase):
"""
Character and line based layer over a BufferedIOBase object, buffer. encoding gives the name of the encoding that the stream will be
decoded or encoded with. It defaults to locale.getpreferredencoding(False). errors determines the strictness of encoding and decoding (see
help(codecs.Codec) or the documentation for codecs.register) and
defaults to "strict". newline controls how line endings are handled. It can be None, '',
'\n', '\r', and '\r\n'. It works as follows: * On input, if newline is None, universal newlines mode is
enabled. Lines in the input can end in '\n', '\r', or '\r\n', and
these are translated into '\n' before being returned to the
caller. If it is '', universal newline mode is enabled, but line
endings are returned to the caller untranslated. If it has any of
the other legal values, input lines are only terminated by the given
string, and the line ending is returned to the caller untranslated. * On output, if newline is None, any '\n' characters written are
translated to the system default line separator, os.linesep. If
newline is '' or '\n', no translation takes place. If newline is any
of the other legal values, any '\n' characters written are translated
to the given string. If line_buffering is True, a call to flush is implied when a call to
write contains a newline character.
"""
def close(self, *args, **kwargs): # real signature unknown
关闭文件
pass def fileno(self, *args, **kwargs): # real signature unknown
文件描述符
pass def flush(self, *args, **kwargs): # real signature unknown
刷新文件内部缓冲区
pass def isatty(self, *args, **kwargs): # real signature unknown
判断文件是否是同意tty设备
pass def read(self, *args, **kwargs): # real signature unknown
读取指定字节数据
pass def readable(self, *args, **kwargs): # real signature unknown
是否可读
pass def readline(self, *args, **kwargs): # real signature unknown
仅读取一行数据
pass def seek(self, *args, **kwargs): # real signature unknown
指定文件中指针位置
pass def seekable(self, *args, **kwargs): # real signature unknown
指针是否可操作
pass def tell(self, *args, **kwargs): # real signature unknown
获取指针位置
pass def truncate(self, *args, **kwargs): # real signature unknown
截断数据,仅保留指定之前数据
pass def writable(self, *args, **kwargs): # real signature unknown
是否可写
pass def write(self, *args, **kwargs): # real signature unknown
写内容
pass def __getstate__(self, *args, **kwargs): # real signature unknown
pass def __init__(self, *args, **kwargs): # real signature unknown
pass @staticmethod # known case of __new__
def __new__(*args, **kwargs): # real signature unknown
""" Create and return a new object. See help(type) for accurate signature. """
pass def __next__(self, *args, **kwargs): # real signature unknown
""" Implement next(self). """
pass def __repr__(self, *args, **kwargs): # real signature unknown
""" Return repr(self). """
pass buffer = property(lambda self: object(), lambda self, v: None, lambda self: None) # default closed = property(lambda self: object(), lambda self, v: None, lambda self: None) # default encoding = property(lambda self: object(), lambda self, v: None, lambda self: None) # default errors = property(lambda self: object(), lambda self, v: None, lambda self: None) # default line_buffering = property(lambda self: object(), lambda self, v: None, lambda self: None) # default name = property(lambda self: object(), lambda self, v: None, lambda self: None) # default newlines = property(lambda self: object(), lambda self, v: None, lambda self: None) # default _CHUNK_SIZE = property(lambda self: object(), lambda self, v: None, lambda self: None) # default _finalizing = property(lambda self: object(), lambda self, v: None, lambda self: None) # default 3.x
文件操作源码
- truncate()方法截取该文件的大小,如果可选尺寸参数存在,该文件将被截断(最多)的大小
大小默认为当前的位置,当前文件位置不改变,注意:如果一个指定的大小超过了文件的当前大小,其结果依赖于平台
此方法不会在当前文件工作在只读模式打开。
fileObject.truncate([size])
size--如果可选参数存在,文件被截断(最多)的大小
没有返回值
#!/usr/bin/python # Open a file
fo = open("foo.txt", "rw+")
print "Name of the file: ", fo.name # Assuming file has following 5 lines
# This is 1st line
# This is 2nd line
# This is 3rd line
# This is 4th line
# This is 5th line line = fo.readline()
print "Read Line: %s" % (line) # Now truncate remaining file.
fo.truncate() # Try to read file now
line = fo.readline()
print "Read Line: %s" % (line) # Close opend file
fo.close()
truncate
结果:
Name of the file: foo.txt
Read Line: This is 1st line Read Line:
a = open("5.log","r+",encoding="utf-8")
a.close() #关闭
a.flush() #强行加入内存
a.read() #读
a.readline() #只读取第一行
a.seek(0) #指针
a.tell() #当前指针位置
a.write() #写
- 管理上下文
1、代码简便,可以通过管理上下文来解决
with open (文件名,打开方式) as f:
#这个方法,通过with代码执行完毕之后,内部会自动关闭并释放文件资源
2、支持打开两个文件
#关闭文件with
with open("5.log","r") as a:
a.read() #同事打开两个文件,把a复制到b中,读一行写一行,直到写完
with open("5.log","r",encoding="utf-8") as a,open("6.log","w",encoding="utf-8") as b:
for line in a:
b.write(line)
实例:
线上优雅的修改配置文件:
global
log 127.0.0.1 local2
daemon
maxconn 256
log 127.0.0.1 local2 info
defaults
log global
mode http
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
option dontlognull listen stats :8888
stats enable
stats uri /admin
stats auth admin:1234 frontend oldboy.org
bind 0.0.0.0:80
option httplog
option httpclose
option forwardfor
log global
acl www hdr_reg(host) -i www.oldboy.org
use_backend www.oldboy.org if www backend www.oldboy.org
server 100.1.7.9 100.1.7.9 weight 20 maxconn 3000 原配置文件
原文件
1、查
输入:www.oldboy.org
获取当前backend下的所有记录 2、新建
输入:
arg = {
'bakend': 'www.oldboy.org',
'record':{
'server': '100.1.7.9',
'weight': 20,
'maxconn': 30
}
} 3、删除
输入:
arg = {
'bakend': 'www.oldboy.org',
'record':{
'server': '100.1.7.9',
'weight': 20,
'maxconn': 30
}
} 需求
需求
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import json
import os def fetch(backend):
backend_title = 'backend %s' % backend
record_list = []
with open('ha') as obj:
flag = False
for line in obj:
line = line.strip()
if line == backend_title:
flag = True
continue
if flag and line.startswith('backend'):
flag = False
break if flag and line:
record_list.append(line) return record_list def add(dict_info):
backend = dict_info.get('backend')
record_list = fetch(backend)
backend_title = "backend %s" % backend
current_record = "server %s %s weight %d maxconn %d" % (dict_info['record']['server'], dict_info['record']['server'], dict_info['record']['weight'], dict_info['record']['maxconn'])
if not record_list:
record_list.append(backend_title)
record_list.append(current_record)
with open('ha') as read_file, open('ha.new', 'w') as write_file:
flag = False
for line in read_file:
write_file.write(line)
for i in record_list:
if i.startswith('backend'):
write_file.write(i+'\n')
else:
write_file.write("%s%s\n" % (8*" ", i))
else:
record_list.insert(0, backend_title)
if current_record not in record_list:
record_list.append(current_record) with open('ha') as read_file, open('ha.new', 'w') as write_file:
flag = False
has_write = False
for line in read_file:
line_strip = line.strip()
if line_strip == backend_title:
flag = True
continue
if flag and line_strip.startswith('backend'):
flag = False
if not flag:
write_file.write(line)
else:
if not has_write:
for i in record_list:
if i.startswith('backend'):
write_file.write(i+'\n')
else:
write_file.write("%s%s\n" % (8*" ", i))
has_write = True
os.rename('ha','ha.bak')
os.rename('ha.new','ha') def remove(dict_info):
backend = dict_info.get('backend')
record_list = fetch(backend)
backend_title = "backend %s" % backend
current_record = "server %s %s weight %d maxconn %d" % (dict_info['record']['server'], dict_info['record']['server'], dict_info['record']['weight'], dict_info['record']['maxconn'])
if not record_list:
return
else:
if current_record not in record_list:
return
else:
del record_list[record_list.index(current_record)]
if len(record_list) > 0:
record_list.insert(0, backend_title)
with open('ha') as read_file, open('ha.new', 'w') as write_file:
flag = False
has_write = False
for line in read_file:
line_strip = line.strip()
if line_strip == backend_title:
flag = True
continue
if flag and line_strip.startswith('backend'):
flag = False
if not flag:
write_file.write(line)
else:
if not has_write:
for i in record_list:
if i.startswith('backend'):
write_file.write(i+'\n')
else:
write_file.write("%s%s\n" % (8*" ", i))
has_write = True
os.rename('ha','ha.bak')
os.rename('ha.new','ha') if __name__ == '__main__':
"""
print '1、获取;2、添加;3、删除'
num = raw_input('请输入序号:')
data = raw_input('请输入内容:')
if num == '1':
fetch(data)
else:
dict_data = json.loads(data)
if num == '2':
add(dict_data)
elif num == '3':
remove(dict_data)
else:
pass
"""
#data = "www.oldboy.org"
#fetch(data)
#data = '{"backend": "tettst.oldboy.org","record":{"server": "100.1.7.90","weight": 20,"maxconn": 30}}'
#dict_data = json.loads(data)
#add(dict_data)
#remove(dict_data) demo
操作步骤
python05-09的更多相关文章
- Windows7WithSP1/TeamFoundationServer2012update4/SQLServer2012
[Info @09:03:33.737] ====================================================================[Info @ ...
- 《HelloGitHub月刊》第09期
<HelloGitHub>第09期 兴趣是最好的老师,<HelloGitHub>就是帮你找到兴趣! 前言 转眼就到年底了,月刊做到了第09期,感谢大家一路的支持和帮助
- js正则表达式校验非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- iOS系列 基础篇 09 开关、滑块和分段控件
iOS系列 基础篇 09 开关.滑块和分段控件 目录: 案例说明 开关控件Switch 滑块控件Slider 分段控件Segmented Control 1. 案例说明 开关控件(Switch).滑块 ...
- http://www.cnblogs.com/Lawson/archive/2012/09/03/2669122.html
http://www.cnblogs.com/Lawson/archive/2012/09/03/2669122.html
- u-boot-2010.09移植(A)
第一阶段 1.开发环境 系统:centOS6.5 linux版本:2.6.32 交叉编译器:buildroot-2012.08 以上工具已经准备好,具体安装步骤不再 ...
- u-boot-2010.09移植(B)
前面我们的u-boot只是在内存中运行,要想在nandflash中运行,以达到开机自启的目的,还需作如下修改 一.添加DM9000网卡支持 1.修改board/fl2440/fl2440.c中的boa ...
- Linux JDK 安装及卸载 http://www.cnblogs.com/benio/archive/2010/09/14/1825909.html
参考:http://www.cnblogs.com/benio/archive/2010/09/14/1825909.html
- c#用正则表达式判断字符串是否全是数字、小数点、正负号组成 Regex reg = new Regex(@"^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$");
Regex reg = new Regex(@"^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][ ...
- JavaScript学习09 函数本质及Function对象深入探索
JavaScript学习09 函数本质及Function对象深入探索 在JavaScript中,函数function就是对象. JS中没有方法重载 在JavaScript中,没有方法(函数)重载的概念 ...
随机推荐
- Android Studio集成crashlytics后无法编译的问题
http://blog.csdn.net/zhuobattle/article/details/50555393 问题描述: 在用fabric集成后编译出现如下错误, Error:Cause: hos ...
- springboot @test 使用
@RunWith(SpringRunner.class) @SpringBootTest(classes = Application.class) public class Springtest { ...
- WEB 前端模块化,读文笔记
文章链接 WEB 前端模块化都有什么? 知识点 根据平台划分 浏览器 AMD.CMD 存在网络瓶颈,使用异步加载 非浏览器 CommonJS 直接操作 IO,同步加载 浏览器 AMD 依赖前置 req ...
- luogu P1205 方块转换
题目描述 一块N x N(1<=N<=10)正方形的黑白瓦片的图案要被转换成新的正方形图案.写一个程序来找出将原始图案按照以下列转换方法转换成新图案的最小方式: 1:转90度:图案按顺时针 ...
- SONP 是什么
JSONP 是什么 说实话,我学了这么久,其实也没有好好了解这个东西,当然平常自己在前端方面也涉猎较浅. 1) jsonp 是什么 JSONP(JSON with Padding)是JSON的一种&q ...
- Python能干啥?
Python之py9 Python之py9-录音自动下载 Python之py9-py9作业检查 Python之py9-py9博客情况获取 Python之py9-微信监控获取mp3_url Python ...
- 剑指Offer(书):数组中重复的数字
题目:找出数组中重复的数字. 说明:在一个长度为n的数组里的所有数字都在0~n-1的范围内,数组中某些数字是重复的,但是不知道有几个数字重复了,也不知道每个数字重复了几次.请找出数组中任意一个重复的数 ...
- LeetCode(20)Valid Parentheses
题目 Given a string containing just the characters '(', ')', '{', '}', '[' and ']', determine if the i ...
- Huffman codes
05-树9 Huffman Codes(30 分) In 1953, David A. Huffman published his paper "A Method for the Const ...
- 关于shell中常见功能的实现方式总结
一.shell脚本中连接数据库 二.