python bs4库
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you.
BeautifulSoup库是解析、遍历、维护 “标签树” 的功能库(遍历,是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问)。https://www.crummy.com/software/BeautifulSoup
BeautifulSoup库我们常称之为bs4,导入该库为:from bs4 import BeautifulSoup。其中,import BeautifulSoup即主要用bs4中的BeautifulSoup类。
bs4库解析器
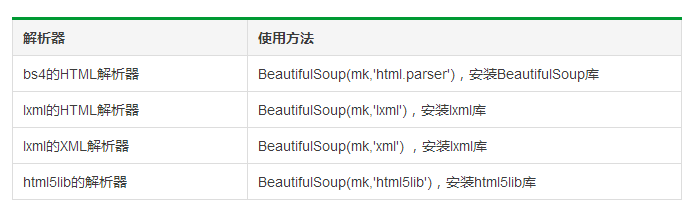
BeautifulSoup类的基本元素
1 import requests
2 from bs4 import BeautifulSoup
3
4 res = requests.get('http://www.pmcaff.com/site/selection')
5 soup = BeautifulSoup(res.text,'lxml')
6 print(soup.a)
7 # 任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。
8
9 print(soup.a.name)
10 # 每个<tag>都有自己的名字,可以通过<tag>.name获取,字符串类型
11
12 print(soup.a.attrs)
13 print(soup.a.attrs['class'])
14 # 一个<tag>可能有一个或多个属性,是字典类型
15
16 print(soup.a.string)
17 # <tag>.string可以取到标签内非属性字符串
18
19 soup1 = BeautifulSoup('<p><!--这里是注释--></p>','lxml')
20 print(soup1.p.string)
21 print(type(soup1.p.string))
22 # comment是一种特殊类型,也可以通过<tag>.string取到
运行结果:
<a class="no-login" href="">登录</a>
a
{'href': '', 'class': ['no-login']} ['no-login']
登录
这里是注释
<class 'bs4.element.Comment'>
bs4库的HTML内容遍历
HTML的基本结构

标签树的下行遍历
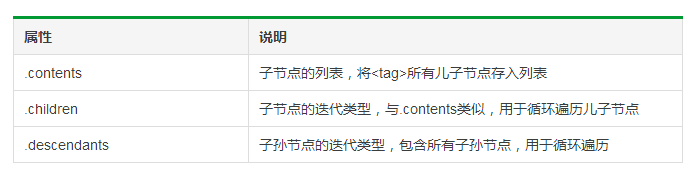
其中,BeautifulSoup类型是标签树的根节点。
1 # 遍历儿子节点
2 for child in soup.body.children:
3 print(child.name)
4
5 # 遍历子孙节点
6 for child in soup.body.descendants:
7 print(child.name)
标签树的上行遍历

1 # 遍历所有先辈节点时,包括soup本身,所以要if...else...判断
2 for parent in soup.a.parents:
3 if parent is None:
4 print(parent)
5 else:
6 print(parent.name)
运行结果:
div
div
body
html
[document]
标签树的平行遍历
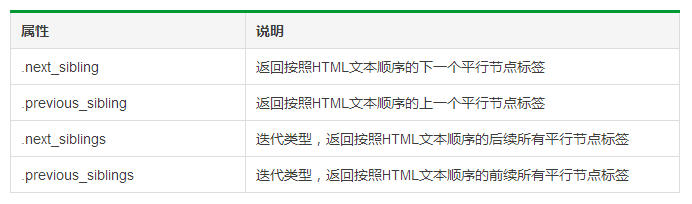
1 # 遍历后续节点
2 for sibling in soup.a.next_sibling:
3 print(sibling)
4
5 # 遍历前续节点
6 for sibling in soup.a.previous_sibling:
7 print(sibling)
bs4库的prettify()方法
prettify()方法可以将代码格式搞的标准一些,用soup.prettify()表示。在PyCharm中,用print(soup.prettify())来输出。
python bs4库的更多相关文章
- Python 每日提醒写博客小程序,使用pywin32、bs4库
死循环延迟调用方法,使用bs4库检索博客首页文章的日期是否与今天日期匹配,不匹配则说明今天没写文章,调用pywin32库进行弹窗提醒我写博客.
- python标准库Beautiful Soup与MongoDb爬喜马拉雅电台的总结
Beautiful Soup标准库是一个可以从HTML/XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,Beautiful Soup将会节省数小 ...
- python BeautifulSoup库的基本使用
Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree). 它提供简单又常用的导航(navigating),搜索以 ...
- python BeautifulSoup库用法总结
1. Beautiful Soup 简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- python3.4学习笔记(八) Python第三方库安装与使用,包管理工具解惑
python3.4学习笔记(八) Python第三方库安装与使用,包管理工具解惑 许多人在安装Python第三方库的时候, 经常会为一个问题困扰:到底应该下载什么格式的文件?当我们点开下载页时, 一般 ...
- Python BeautifulSoup库的用法
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的Python库,它通过解析器把文档解析为利于人们理解的文档导航模式,有利于查找和修改文档. BeautifulSoup3目前已经 ...
- python第三方库地址
python第三方库的地址: requests: http://docs.python-requests.org/zh_CN/latest/user/quickstart.html beautifus ...
- windows下python常用库的安装
windows下python常用库的安装,前提安装了annaconda 的python开发环境.只要已经安装了anaconda,要安装别的库就很简单了.只要使用pip即可,正常安装好python,都会 ...
- Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)
Python:requests库.BeautifulSoup4库的基本使用(实现简单的网络爬虫) 一.requests库的基本使用 requests是python语言编写的简单易用的HTTP库,使用起 ...
随机推荐
- ubuntu12.04安装NVIDIA显卡驱动和CUDA
1.安装显卡驱动 vim /etc/modprobe.d/blacklist.conf #编辑该文件 blacklist nouveau #行末添加,禁用原来的显卡驱动 apt-get install ...
- HDU 4850 Wow! Such String!(欧拉道路)
HDU 4850 Wow! Such String! 题目链接 题意:求50W内的字符串.要求长度大于等于4的子串,仅仅出现一次 思路:须要推理.考虑4个字母的字符串,一共同拥有26^4种,这些由这些 ...
- Centos7 防火墙firewalld配置
开启80端口 firewall-cmd --zone=public --add-port=80/tcp --permanent 出现success表明添加成功 移除某个端口 firewall-cmd ...
- android 制作9.png图片
什么叫.9.PNG呢,这是安卓开发里面的一种特殊的图片 这种格式的图片在android 环境下具有自适应调节大小的能力. (1)允许开发人员定义可扩展区域,当需要延伸图片以填充比图片本身更大区 ...
- 【POJ 3352】 Road Construction
[题目链接] 点击打开链接 [算法] tarjan算法求边双联通分量 [代码] #include <algorithm> #include <bitset> #include ...
- 第十四周 Leetcode 315. Count of Smaller Numbers After Self(HARD) 主席树
Leetcode315 题意很简单,给定一个序列,求每一个数的右边有多少小于它的数. O(n^2)的算法是显而易见的. 用普通的线段树可以优化到O(nlogn) 我们可以直接套用主席树的模板. 主席树 ...
- MVC post 方法导出word文档
View code: function ExportWord(){ var html = $("#div_workInfo").html(); $("#hidWord&q ...
- 如何给mysql用户分配权限+增、删、改、查mysql用户
在mysql中用户权限是一个很重析 参数,因为台mysql服务器中会有大量的用户,每个用户的权限需要不一样的,下面我来介绍如何给mysql用户分配权限吧,有需要了解的朋友可参考. 1,Mysql下创建 ...
- Spring Theme简单应用
Spring MVC特性里由一个是关于Spring Theme主题的应用,所以写了个Demo 1.这里先看项目结构(Meven项目) 2.所需的POM依赖 <dependency> < ...
- bzoj 1672: [Usaco2005 Dec]Cleaning Shifts 清理牛棚【dp+线段树】
设f[i]为i时刻最小花费 把牛按l升序排列,每头牛能用f[l[i]-1]+c[i]更新(l[i],r[i])的区间min,所以用线段树维护f,用排完序的每头牛来更新,最后查询E点即可 #includ ...