并查集(Union Find)的基本实现
概念
并查集是一种树形的数据结构,用来处理一些不交集的合并及查询问题。主要有两个操作:
- find:确定元素属于哪一个子集。
- union:将两个子集合并成同一个集合。
所以并查集能够解决网络中节点的连通性问题。
基本实现
package com.yunche.datastructure;
/**
* @ClassName: UF
* @Description: 并查集
* @author: yunche
* @date: 2018/12/30
*/
public class UF {
/**
* 此数组的索引表示节点的编号,数组存储的是对应节点所在的集合编号
*/
private int[] id;
/**
* 节点的个数
*/
private int count;
/**
* 构造函数:构造一个指定大小的并查集
*
* @param n 并查集节点的个数
*/
public UF(int n) {
id = new int[n];
count = n;
for (int i = 0; i < n; i++) {
id[i] = i;
}
}
/**
* 查找指定节点的所属的集合编号
*
* @param p 节点编号
* @return 集合编号
*/
public int find(int p) {
if (p >= 0 && p < count) {
return id[p];
}
return -1;
}
/**
* 将两个节点所属的集合并在一起,即将两个节点连通
*
* @param p 节点编号
* @param q 节点编号
*/
public void union(int p, int q) {
int pId = find(p);
int qId = find(q);
if (pId < 0 || qId < 0) {
return;
}
if (qId == pId) {
return;
}
for (int i = 0; i < count; i++) {
if (id[i] == pId) {
id[i] = qId;
}
}
}
/**
* 判断两个节点是否连通
* @param p 节点编号
* @param q 节点编号
* @return
*/
public boolean isConnected(int p, int q) {
return find(p) != -1 && find(p) == find(q);
}
/**
* 测试用例
* @param args
*/
public static void main(String[] args) {
UF uf= new UF(5);
uf.union(0, 1);
uf.union(0, 2);
uf.union(6, 2);
System.out.println(uf.isConnected(1, 2));
System.out.println(uf.isConnected(0, 3));
System.out.println(uf.isConnected(6, 2));
}
}
对 union 进行 rank 优化
package com.yunche.datastructure;
/**
* @ClassName: UF2
* @Description: 针对union进行rank优化
* @author: yunche
* @date: 2018/12/30
*/
public class UF2 {
/**
* 此数组的索引为节点的编号,数组存储的为对应节点的父节点的编号
*/
private int[] parent;
/**
* 节点的个数
*/
private int count;
/**
* 进一步优化union
* 数组的索引代表集合的根节点
* 数组存储的是每个根节点下的对应的树层数
*/
private int[] rank;
/**
* 构造函数:构造一个指定大小的并查集
*
* @param n 并查集节点的个数
*/
public UF2(int n) {
parent = new int[n];
rank = new int[n];
count = n;
for (int i = 0; i < n; i++) {
parent[i] = i;
rank[i] = 1;
}
}
/**
* 查找指定节点的所属的集合的根节点编号
*
* @param p 节点编号
* @return 根节点编号
*/
public int find(int p) {
if (p >= 0 && p < count) {
while (p != parent[p]) {
p = parent[p];
}
return p;
}
return -1;
}
/**
* 将两个节点所属的集合并在一起,即将两个节点连通
* 时间复杂度O(n)
* @param p 节点编号
* @param q 节点编号
*/
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot < 0 || qRoot < 0) {
return;
}
if (qRoot == pRoot) {
return;
}
//合并两个集合
//重要优化避免构造树的深度太深
if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;
} else if (rank[pRoot] > rank[qRoot]){
parent[qRoot] = pRoot;
} else {
parent[pRoot] = qRoot;
rank[qRoot] += 1;
}
}
/**
* 判断两个节点是否连通
* 时间复杂度O(1)
* @param p 节点编号
* @param q 节点编号
* @return
*/
public boolean isConnected(int p, int q) {
return find(p) != -1 && find(p) == find(q);
}
/**
* 测试用例
* @param args
*/
public static void main(String[] args) {
testUF2(1000000);
}
/**
* 测试方法
* @param n 并差集的个数
*/
public static void testUF2( int n ){
UF2 uf = new UF2(n);
long startTime = System.currentTimeMillis();
// 进行n次操作, 每次随机选择两个元素进行合并操作
for( int i = 0 ; i < n ; i ++ ){
int a = (int)(Math.random()*n);
int b = (int)(Math.random()*n);
uf.union(a,b);
}
// 再进行n次操作, 每次随机选择两个元素, 查询他们是否同属一个集合
for(int i = 0 ; i < n ; i ++ ){
int a = (int)(Math.random()*n);
int b = (int)(Math.random()*n);
uf.isConnected(a,b);
}
long endTime = System.currentTimeMillis();
// 打印输出对这2n个操作的耗时
System.out.println("UF2, " + 2*n + " ops, " + (endTime-startTime) + "ms");
}
}
对 find 进行路径压缩
1、第一种方式
图示

代码
package com.yunche.datastructure;
/**
* @ClassName: UF3
* @Description: 对find操作进行路径压缩,第一种路径压缩,过程如图所示
* @author: yunche
* @date: 2018/12/30
*/
public class UF3 {
/**
* 此数组的索引为节点的编号,数组存储的为对应节点的父节点编号
*/
private int[] parent;
/**
* 节点的个数
*/
private int count;
/**
* 进一步优化union
* 数组的索引代表集合的根节点
* 数组存储的是每个根节点下的对应的树深度
* 在后续的代码中, 我们并不会维护rank的语意, 也就是rank的值在路径压缩的过程中, 有可能不再是树的层数值
* 这也是我们的rank不叫height或者depth的原因, 它只是作为比较的一个标准
*/
private int[] rank;
/**
* 构造函数:构造一个指定大小的并查集
*
* @param n 并查集节点的个数
*/
public UF3(int n) {
parent = new int[n];
rank = new int[n];
count = n;
for (int i = 0; i < n; i++) {
parent[i] = i;
rank[i] = 1;
}
}
/**
* 查找指定节点的所属的集合的根节点编号
* 路径压缩
* @param p 节点编号
* @return 根节点编号
*/
public int find(int p) {
if (p >= 0 && p < count) {
while (p != parent[p]) {
// 根据图示,p的父节点应该指向p的父节点的父节点
parent[p] = parent[parent[p]];
//继续从此时p的父节点开始循环
p = parent[p];
}
return p;
}
return -1;
}
/**
* 将两个节点所属的集合并在一起,即将两个节点连通
* 时间复杂度O(n)
* @param p 节点编号
* @param q 节点编号
*/
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot < 0 || qRoot < 0) {
return;
}
if (qRoot == pRoot) {
return;
}
//合并两个集合
//重要优化避免构造树的深度太深
if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;
} else if (rank[pRoot] > rank[qRoot]){
parent[qRoot] = pRoot;
} else {
parent[pRoot] = qRoot;
rank[qRoot] += 1;
}
}
/**
* 判断两个节点是否连通
* 时间复杂度O(1)
* @param p 节点编号
* @param q 节点编号
* @return
*/
public boolean isConnected(int p, int q) {
return find(p) != -1 && find(p) == find(q);
}
/**
* 测试用例
* @param args
*/
public static void main(String[] args) {
UF2.testUF2(1000000);
testUF3(1000000);
}/*Output:
UF2, 2000000 ops, 856ms
UF3, 2000000 ops, 579ms
*/
/**
* 测试方法
* @param n 并查集的个数
*/
public static void testUF3( int n ){
UF3 uf = new UF3(n);
long startTime = System.currentTimeMillis();
// 进行n次操作, 每次随机选择两个元素进行合并操作
for( int i = 0 ; i < n ; i ++ ){
int a = (int)(Math.random()*n);
int b = (int)(Math.random()*n);
uf.union(a,b);
}
// 再进行n次操作, 每次随机选择两个元素, 查询他们是否同属一个集合
for(int i = 0 ; i < n ; i ++ ){
int a = (int)(Math.random()*n);
int b = (int)(Math.random()*n);
uf.isConnected(a,b);
}
long endTime = System.currentTimeMillis();
// 打印输出对这2n个操作的耗时
System.out.println("UF3, " + 2*n + " ops, " + (endTime-startTime) + "ms");
}
}
2、第二种方式
在明白了第一种压缩路径的方法后,我们可能会疑惑:是否这就是最短的路径了?我们仔细思考后会发现,这并不是最短的路径,最短的路径形成的树应该只有2层,第一层为根节点,其余所有节点都在第二层指向根节点,如下图所示。要实现这种压缩路径的方式也简单,使用递归即可。
图示
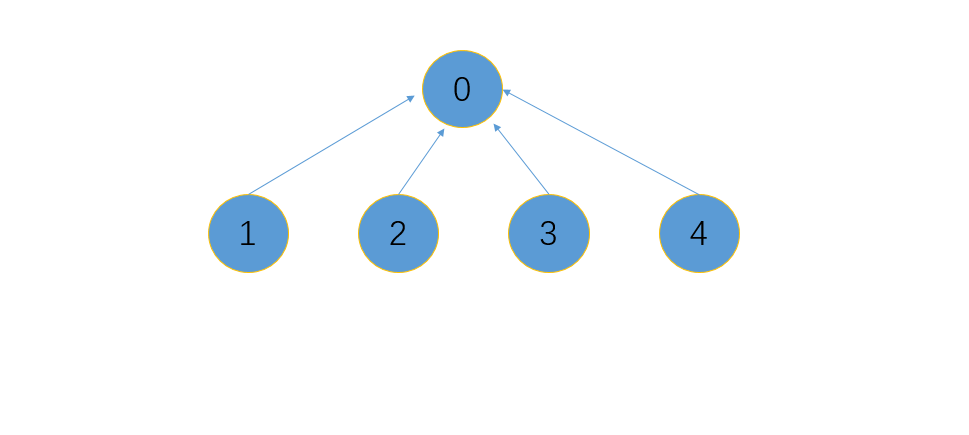
代码
package com.yunche.datastructure;
/**
* @ClassName: UF4
* @Description: 对find操作进行路径压缩,第二种路径的递归压缩
* @author: yunche
* @date: 2018/12/30
*/
public class UF4 {
/**
* 此数组的索引为节点的编号,数组存储的为对应节点的父节点编号
*/
private int[] parent;
/**
* 节点的个数
*/
private int count;
/**
* 进一步优化union
* 数组的索引代表集合的根节点
* 数组存储的是每个根节点下的对应的树层数
* 在后续的代码中, 我们并不会维护rank的语意, 也就是rank的值在路径压缩的过程中, 有可能不再是树的层数值
* 这也是我们的rank不叫height或者depth的原因, 它只是作为比较的一个标准
*/
private int[] rank;
/**
* 构造函数:构造一个指定大小的并查集
*
* @param n 并查集节点的个数
*/
public UF4(int n) {
parent = new int[n];
rank = new int[n];
count = n;
for (int i = 0; i < n; i++) {
parent[i] = i;
rank[i] = 1;
}
}
/**
* 压缩路径递归实现 递归算法
* @param p 节点编号
* @return 返回节点当前的根节点编号
*/
public int find(int p) {
if (p >= 0 && p < count) {
// 递归边界
if (p == parent[p]) {
return p;
}
//想象此时有 3 层:分别是 0, 1, 2,最开始p = 2
// 那么第一次执行到这个位置 parent[2] = findRecursive(1)
//第二次执行到这个位置 parent[1] = findRecursive(0)
//当再一次递归此时,到不到这一步,因为触发递归边界,返回0
//那么,向上 parent[1] = 0
//再向上,parent[2] = parent[1] = 0
parent[p] = find(parent[p]);
return parent[p];
}
return -1;
}
/**
* 将两个节点所属的集合并在一起,即将两个节点连通
* 时间复杂度O(n)
* @param p 节点编号
* @param q 节点编号
*/
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot < 0 || qRoot < 0) {
return;
}
if (qRoot == pRoot) {
return;
}
//合并两个集合
//重要优化避免构造树的深度太深
if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;
} else if (rank[pRoot] > rank[qRoot]){
parent[qRoot] = pRoot;
} else {
parent[pRoot] = qRoot;
rank[qRoot] += 1;
}
}
/**
* 判断两个节点是否连通
* 时间复杂度O(1)
* @param p 节点编号
* @param q 节点编号
* @return
*/
public boolean isConnected(int p, int q) {
return find(p) != -1 && find(p) == find(q);
}
/**
* 测试用例
* @param args
*/
public static void main(String[] args) {
UF2.testUF2(1000000);
UF3.testUF3(1000000);
UF4.testUF4(1000000);
}/*Output:
UF2, 2000000 ops, 918ms
UF3, 2000000 ops, 586ms
UF4, 2000000 ops, 631ms
*/
/**
* 测试方法 -
* @param n 并查集的个数
*/
public static void testUF4( int n ){
UF4 uf = new UF4(n);
long startTime = System.currentTimeMillis();
// 进行n次操作, 每次随机选择两个元素进行合并操作
for( int i = 0 ; i < n ; i ++ ){
int a = (int)(Math.random()*n);
int b = (int)(Math.random()*n);
uf.union(a,b);
}
// 再进行n次操作, 每次随机选择两个元素, 查询他们是否同属一个集合
for(int i = 0 ; i < n ; i ++ ){
int a = (int)(Math.random()*n);
int b = (int)(Math.random()*n);
uf.isConnected(a,b);
}
long endTime = System.currentTimeMillis();
// 打印输出对这2n个操作的耗时
System.out.println("UF4, " + 2*n + " ops, " + (endTime-startTime) + "ms");
}
}
3、 两种压缩路径的比较
从理论上说,第二种压缩路径算法应该比第一种快,但上面的测试方法的结果却是第一种压缩路径算法更快,这是因为第二种压缩算法有递归上的开销,结果上也表面这两种算法效率是差别不大的,所以采取哪种方法要实际测试下。
并查集(Union Find)的基本实现的更多相关文章
- 并查集(Union/Find)模板及详解
概念: 并查集是一种非常精巧而实用的数据结构,它主要用于处理一些不相交集合的合并问题.一些常见的用途有求连通子图.求最小生成树的Kruskal 算法和求最近公共祖先等. 操作: 并查集的基本操作有两个 ...
- POJ 1611 The Suspects 并查集 Union Find
本题也是个标准的并查集题解. 操作完并查集之后,就是要找和0节点在同一个集合的元素有多少. 注意这个操作,须要先找到0的父母节点.然后查找有多少个节点的额父母节点和0的父母节点同样. 这个时候须要对每 ...
- Java 并查集Union Find
对于一组数据,主要支持两种动作: union isConnected public interface UF { int getSize(); boolean isConnected(int p,in ...
- 最小生成树(Minimum Spanning Tree)——Prim算法与Kruskal算法+并查集
最小生成树——Minimum Spanning Tree,是图论中比较重要的模型,通常用于解决实际生活中的路径代价最小一类的问题.我们首先用通俗的语言解释它的定义: 对于有n个节点的有权无向连通图,寻 ...
- bzoj1854 [Scoi2010]游戏【构图 并查集】
传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=1854 没想到怎么做真是不应该,看到每个武器都有两个属性,应该要想到连边构图的!太不应该了! ...
- [leetcode] 并查集(Ⅰ)
预备知识 并查集 (Union Set) 一种常见的应用是计算一个图中连通分量的个数.比如: a e / \ | b c f | | d g 上图的连通分量的个数为 2 . 并查集的主要思想是在每个连 ...
- 并查集 (Union Find ) P - The Suspects
Severe acute respiratory syndrome (SARS), an atypical pneumonia of unknown aetiology, was recognized ...
- 并查集(Disjoint Set Union,DSU)
定义: 并查集是一种用来管理元素分组情况的数据结构. 作用: 查询元素a和元素b是否属于同一组 合并元素a和元素b所在的组 优化方法: 1.路径压缩 2.添加高度属性 拓展延伸: 分组并查集 带权并查 ...
- 第三十一篇 玩转数据结构——并查集(Union Find)
1.. 并查集的应用场景 查看"网络"中节点的连接状态,这里的网络是广义上的网络 数学中的集合类的实现 2.. 并查集所支持的操作 对于一组数据,并查集主要支持两种操作:合并两 ...
随机推荐
- 昆石VOS3000_2.1.2.4完整安装包及安装脚本
安装包下载地址:http://www.51voip.org/post/56.html 安装教程: 上传安装包 ·给整个目录授权 chmod 777 /root/vosintsall `核实 关闭sel ...
- P4244 [SHOI2008]仙人掌图 II
传送门 仙人掌直径,以前好像模拟赛的时候做到过一道基环树的直径,打了个很麻烦的然而还错了--今天才发现那就是这个的弱化版啊-- 如果是树的话用普通的dp即可,记\(f[u]\)表示\(u\)往下最长能 ...
- MySQL索引使用以及优化
优化后台业主评价服务人员运行缓慢. 案发现场:后台业主评价服务人员列表页以及搜索页运行缓慢.运行时间为24074ms. 排查过程: 1.代码开头加时间,结束加时间.看运行了多少秒. 2.给评价 ...
- Hadoop回收站及fs.trash参数详解
前言: Linux系统里,个人觉得最大的不方便之一就是没有回收站的概念.rm -rf很容易造成极大的损失.而在Hadoop或者说HDFS里面,有trash(回收站)的概念,可以使得数据被误删以后,还可 ...
- 微信小程序setData的使用,通过[...]进行动态key赋值
首先先介绍一下微信小程序Page.prototype.setData(Object data, Function callback)的讲解: setData函数用于将数据从逻辑层发送到视图层(异步), ...
- Java多线程(四)isAlive
isAlive 活动状态:线程处于正在运行或准备开始运行的状态 public class ISLiveDemo extends Thread { public void run() { System. ...
- 生成 Guid
//生成Guid function getGuidGenerator() { var S4 = function () { return (((1 + Mat ...
- 【转】Linux系统编程---dup和dup2详解
正常的文件描述符: 在linux下,通过open打开以文件后,会返回一个文件描述符,文件描述符会指向一个文件表,文件表中的节点指针会指向节点表.看下图: 打开文件的内核数据结构 dup和dup2两个函 ...
- 洛谷 P2881 [USACO07MAR]排名的牛Ranking the Cows
题应该是假的...先不做了 https://www.cnblogs.com/Blue233333/p/7249057.html 比如输入5 0,答案是10,但可以比较8次就出来.就是在一个已知有序数列 ...
- KMP POJ 2752 Seek the Name, Seek the Fame
题目传送门 /* 题意:求出一个串的前缀与后缀相同的字串的长度 KMP:nex[]就有这样的性质,倒过来输出就行了 */ /************************************** ...