python爬取豆瓣小组700+话题加回复啦啦啦python open file with a variable name
需求:爬取豆瓣小组所有话题(话题title,内容,作者,发布时间),及回复(最佳回复,普通回复,回复_回复,翻页回复,0回复)

解决:1. 先爬取小组下,所有的主题链接,通过定位nextpage翻页获取总过700+条话题;
2. 访问700+ 链接,在内页+start=0中,获取话题相关的四部分(话题title,内容,作者,发布时间),及最佳回复、回复;
3. 在2的基础上,判断是否有回复,如果有回复才进一步判断是否有回复翻页,回复翻页通过nextpage 获取start=100、start=200的页;
4. 进入下一个爬取函数,将抓取的回复 续写 到2 中的文件;
解决思路:
Before:一开始建立2个文件,article.txt 用来存储所有话题相关的内容(700+话题、作者信息);
同时,建立以title命名的回复文件;
After: 统一建立以话题title命名的文章,先写入文章相关内容,再续写回复;这样方便读取;
遇到的坑:
1. 要获取某个div下直接的text,div.span下的text,div.h下的text:
——有2个解决方法:
A. 通过xpath //text,意思是获取div 下的所有text文件;

B. 通过css 拼接,逗号隔开即可:
2. 巩固了不同函数之间通过meta传递参数的方法:

3. python open file with a variable name
f = open('%s.txt' % title_end,'a')
a: 续写

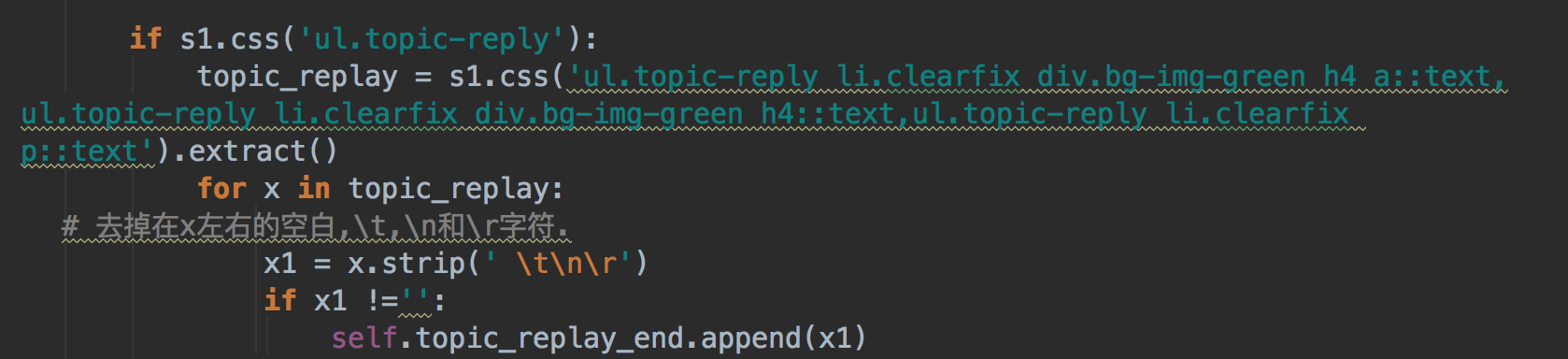
4.去掉 str 中的空格,换行等符号
# 去掉在x左右的空白,\t,\n和\r字符.
x1 = x.strip(' \t\n\r')
5 . strip 去掉数据中的\r,''.join 将列表转回字符串;
# 先将文章中的\r 都去掉,有些单独的'\r' 就变成了空的列表元素:'',再用if 来判断下就好了
artical_end = []
for x in article:
x1 = x.replace('\r','')
if x1 != '':
artical_end.append(x1)
# 将artical_end 列表 转为字符串
ar =''.join(artical_end)
python爬取豆瓣小组700+话题加回复啦啦啦python open file with a variable name的更多相关文章
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
- Python 爬取单个网页所需要加载的地址和CSS、JS文件地址
Python 爬取单个网页所需要加载的URL地址和CSS.JS文件地址 通过学习Python爬虫,知道根据正式表达式匹配查找到所需要的内容(标题.图片.文章等等).而我从测试的角度去使用Python爬 ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- python 爬取豆瓣书籍信息
继爬取 猫眼电影TOP100榜单 之后,再来爬一下豆瓣的书籍信息(主要是书的信息,评分及占比,评论并未爬取).原创,转载请联系我. 需求:爬取豆瓣某类型标签下的所有书籍的详细信息及评分 语言:pyth ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
随机推荐
- bzoj 1702: [Usaco2007 Mar]Gold Balanced Lineup 平衡的队列【hash】
我%&&--&()&%????? 双模hashWA,unsigned long longAC,而且必须判断hash出来的数不能为0???? 我可能学了假的hash 这个 ...
- Django day 34 过滤课程,登录,redis,python操作redis
一:过滤课程, 二:登录 三:redis, 四:python操作redis
- 洛谷 P1074 靶形数独(剪枝)
//人生中第一道蓝题(3.5h) 题目描述 小城和小华都是热爱数学的好学生,最近,他们不约而同地迷上了数独游戏,好胜的他们想用数独来一比高低.但普通的数独对他们来说都过于简单了,于是他们向 Z 博士请 ...
- hdu61272017杭电多校第七场1008Hard challenge
Hard challenge Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 524288/524288 K (Java/Others) ...
- Android 性能优化(21)*性能工具之「GPU呈现模式分析」Profiling GPU Rendering Walkthrough:分析View显示是否超标
Profiling GPU Rendering Walkthrough 1.In this document Prerequisites Profile GPU Rendering $adb shel ...
- WebForm vs MVC
What is ASP.NET? ASP.NET is a Microsoft’s Web application framework built on Common language runtime ...
- DatePickerDialog日期对话框以及回调函数的用法
DatePickerDialog类的实例化需要用到回调接口,如下定义: android.app.DatePickerDialog.DatePickerDialog(Context context, O ...
- 继续C#开发or转做产品
本人今年大四,C#开发,在一家公司实习了一年后,面临一个选择,是继续C#开发还是转做产品?我C#开发能力目前还一般,但很有兴趣.也喜欢设计与创意,做过产品专员.求大婶们指导!
- 最优化方法系列:SGD、Adam
整理一下资源,不过最好还是根据书上的理论好好推导一下..... 文章链接:Deep Learning 最优化方法之SGD 72615436 本文是Deep Learning 之 最优化方法系列文章 整 ...
- java继承问题
代码: 父类: public class Father { public Father() { System.out.println("基类构造函数{"); show(); new ...