爬虫之BeautifulSoup库
文档:https://beautifulsoup.readthedocs.io/zh_CN/latest/
一、开始
解析库
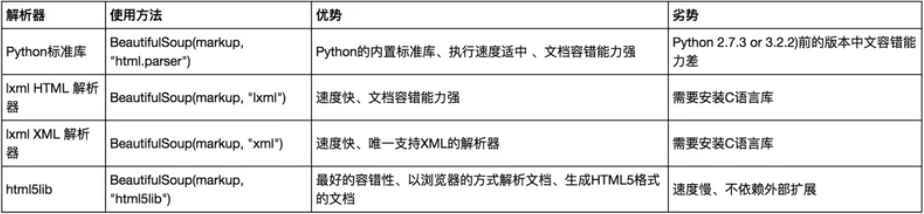
# 安装解析库
pip3 install lxml
pip3 install html5lib
基本使用
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.prettify()) # 格式化代码,自动补全,容错处理
print(soup.title.string) # The Dormouse's story
"""
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
</body>
</html>
"""
二、标签选择器
选择元素
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">
beautifulsoup4
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
</p>
<p class="story">...</p>
</body>
</html>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.title) # <title>The Dormouse's story</title>
print(type(soup.title)) # <class 'bs4.element.Tag'>
print(soup.head)
"""
<head>
<title>The Dormouse's story</title>
</head>
"""
print(soup.p) # <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
获取名称
from bs4 import BeautifulSoup
html = "<html><title>The Dormouse's story</title></html>"
soup = BeautifulSoup(html, "lxml")
print(soup.title.name) # title
获取属性值
from bs4 import BeautifulSoup
html = """
<p class="title" name="pd"><b>The Dormouse's story</b></p>
"""
soup = BeautifulSoup(html, "lxml")
print(soup.p.attrs["name"]) # pd
print(soup.p["name"]) # pd
获取内容
from bs4 import BeautifulSoup
html = """
<p class="title" name="pd"><b>The Dormouse's story</b></p>
"""
soup = BeautifulSoup(html, "lxml")
print(soup.p.string) # The Dormouse's story
嵌套选择
from bs4 import BeautifulSoup
html = """
<head>
<title>The Dormouse's story</title>
</head>
"""
soup = BeautifulSoup(html, "lxml")
print(soup.head.title.string) # The Dormouse's story
子节点和子孙节点
tag的 .contents 属性可以将tag的子节点以列表的方式输出:
from bs4 import BeautifulSoup
html = """
<p class="story">
beautifulsoup4
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
</p>
"""
soup = BeautifulSoup(html, "lxml")
print(soup.p.contents)
# ['\nbeautifulsoup4\n', <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, '\n', <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, '\n', <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, '\n']
通过tag的 .children 生成器,可以对tag的子节点进行循环:
html = """
<html>
<head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.p.children) # <list_iterator object at 0x00000000031F6C88>
for i, child in enumerate(soup.p.children):
print(i, child) # 0 <b>The Dormouse's story</b>
.contents 和 .children 属性仅包含tag的直接子节点。例如,<head>标签只有一个直接子节点<title>;
但是<title>标签也包含一个子节点:字符串 "The Dormouse’s story",这种情况下字符串 "The Dormouse’s story" 也属于<head>标签的子孙节点,.descendants 属性可以对所有tag的子孙节点进行递归循环:
html = """
<html>
<head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.p.descendants) # <generator object descendants at 0x0000000000727200>
for i, child in enumerate(soup.p.descendants):
print(i, child)
"""
0 <b>The Dormouse's story</b>
1 The Dormouse's story
"""
上面的例子中,,<head>标签只有一个子节点,但是有2个子孙节点。
父节点和祖先节点
通过 .parent 属性来获取某个元素的父节点:
html = """
<p class="title"><b>The Dormouse's story</b></p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.b.parent) # <p class="title"><b>The Dormouse's story</b></p>
通过元素的 .parents 属性可以递归得到元素的所有父辈节点:
html = """
<html><head><title>The Dormouse's story</title></head></html>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.title.parents) # <generator object parents at 0x0000000000AA7200>
for i, parent in enumerate(soup.title.parents):
print(i, parent)
"""
0 <head><title>The Dormouse's story</title></head>
1 <html><head><title>The Dormouse's story</title></head></html>
2 <html><head><title>The Dormouse's story</title></head></html>
"""
兄弟节点
html = """
<p class="story">
Once upon a time there were three little sisters
<a id="link1">Elsie</a>
<a id="link2">Lacie</a>
<a id="link3">Tillie</a>
they lived at the bottom of a well
</p> """
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(list(soup.a.next_siblings))
print(list(soup.a.previous_siblings))
"""
['\n', <a id="link2">Lacie</a>, '\n', <a id="link3">Tillie</a>, '\nthey lived at the bottom of a well\n']
['\nOnce upon a time there were three little sisters\n']
"""
三、标准选择器
find_all(name , attrs , recursive , text , **kwargs)
name参数
html = """
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.find_all("ul"))
"""
[<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>, <ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>]
"""
for ul in soup.find_all("ul"):
print(ul.find_all("li"))
"""
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>]
[<li class="element">Foo</li>, <li class="element">Bar</li>]
"""
print(type(soup.find_all("ul")[0])) # <class 'bs4.element.Tag'>
attrs参数
html = """
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.find_all(attrs={"id": "list-1"}))
"""
[<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>]
"""
或者不使用attrs
html = """
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.find_all(id="list-1"))
"""
[<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>]
"""
print(soup.find_all(class_="element"))
# [<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>]
text参数:不是返回标签,而是返回内容
html = """
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.find_all(text="Foo")) # ['Foo', 'Foo']
find( name , attrs , recursive , text , **kwargs )
find返回单个元素,find_all返回所有元素。
html = """
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.find("ul"))
"""
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
"""
print(soup.find("page")) # None
find_parents() 和 find_parent()
find_parents()返回所有祖先节点,find_parent()返回直接父节点。
find_next_siblings() 和 find_next_sibling()
find_next_siblings()返回后面所有兄弟节点,find_next_sibling()返回后面第一个兄弟节点。
find_previous_siblings() 和 find_previous_sibling()
find_previous_siblings()返回前面所有兄弟节点,find_previous_sibling()返回前面第一个兄弟节点。
find_all_next() 和 find_next()
find_all_next()返回节点后所有符合条件的节点,find_next()返回第一个符合条件的节点。
find_all_previous() 和 find_previous()
find_all_previous()返回节点后所有符合条件的节点,find_previous()返回第一个符合条件的节点。
四、CSS选择器
通过select()直接传入CSS选择器即可完成选择。
html = """
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
print(soup.select(".panel .panel-heading"))
"""
[<div class="panel-heading">
<h4>Hello</h4>
</div>]
"""
print(soup.select("ul li"))
# [<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>]
print(soup.select("#list-2 .element"))
# [<li class="element">Foo</li>, <li class="element">Bar</li>]
print(soup.select("ul")[1])
"""
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
"""
html = """
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
for ul in soup.select("ul"):
print(ul.select("li"))
"""
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>]
[<li class="element">Foo</li>, <li class="element">Bar</li>]
"""
获取属性:
html = """
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
for ul in soup.select("ul"):
print(ul["id"])
print(ul.attrs["id"])
"""
list-1
list-1
list-2
list-2
"""
获取内容:
html = """
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "lxml")
for li in soup.select("li"):
print(li.get_text())
"""
Foo
Bar
Jay
Foo
Bar
"""
五、总结
- 推荐使用lxml解析库,必要时使用html.parser
- 标签选择筛选功能弱但是速度快
- 建议使用find()、find_all() 查询匹配单个结果或者多个结果
- 如果对CSS选择器熟悉建议使用select()
- 记住常用的获取属性和文本值的方法
爬虫之BeautifulSoup库的更多相关文章
- 爬虫入门 beautifulsoup库(一)
先贴一个beautifulsoup的官方文档,https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id12 requ ...
- Python爬虫之BeautifulSoup库
1. BeautifulSoup 1.1 解析库 1)Python标准库 # 使用方法 BeautifulSoup(markup, "html.parser") # 优势 Pyth ...
- Python爬虫小白入门(三)BeautifulSoup库
# 一.前言 *** 上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- python爬虫学习(一):BeautifulSoup库基础及一般元素提取方法
最近在看爬虫相关的东西,一方面是兴趣,另一方面也是借学习爬虫练习python的使用,推荐一个很好的入门教程:中国大学MOOC的<python网络爬虫与信息提取>,是由北京理工的副教授嵩天老 ...
- Python爬虫利器:BeautifulSoup库
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you. BeautifulSoup ...
- $python爬虫系列(2)—— requests和BeautifulSoup库的基本用法
本文主要介绍python爬虫的两大利器:requests和BeautifulSoup库的基本用法. 1. 安装requests和BeautifulSoup库 可以通过3种方式安装: easy_inst ...
- Python爬虫-- BeautifulSoup库
BeautifulSoup库 beautifulsoup就是一个非常强大的工具,爬虫利器.一个灵活又方便的网页解析库,处理高效,支持多种解析器.利用它就不用编写正则表达式也能方便的实现网页信息的抓取 ...
- python爬虫入门四:BeautifulSoup库(转)
正则表达式可以从html代码中提取我们想要的数据信息,它比较繁琐复杂,编写的时候效率不高,但我们又最好是能够学会使用正则表达式. 我在网络上发现了一篇关于写得很好的教程,如果需要使用正则表达式的话,参 ...
随机推荐
- Minimizing Maximizer
题意: 最少需要多少个区间能完全覆盖整个区间[1,n] 分析: dp[i]表示覆盖[1,i]最少需要的区间数,对于区间[a,b],dp[b]=min(dp[a...b-1])+1;用线段树来维护区间最 ...
- 5 Application 对象
5.1鸟瞰Application对象 5.2 必须了解的面向显示特性 5.2.1 使用ScreenUpdating改进和完善执行性能 代码清单5.1:实现屏幕更新的性能 '代码清单5.1: 实现屏幕更 ...
- python 获取当前文件夹路径及父级目录的几种方法
获取当前文件夹路径及父级目录: import os current_dir = os.path.abspath(os.path.dirname(__file__)) print(current_dir ...
- 基于Flink的视频直播案例(上)
目录 数据产生 Logstash部分 Kafka部分 Flink部分 配置/准备代码 视频核心指标监控 本案例参考自阿里云的视频直播解决方案之视频核心指标监控和视频直播解决方案之直播数字化运营. 基于 ...
- Java中的super关键字何时使用
子类的构造函数中不是必须使用super,在构造函数中,如果第一行没有写super(),编译器会自动插入.但是如果父类没有不带参数的构造函数,或这个函数被私有化了(用private修饰).此时你必须加入 ...
- [Shell学习笔记] read命令从键盘或文件中获取标准输入(转载)
转自:http://www.1987.name/151.html read命令是用于从终端或者文件中读取输入的内部命令,read命令读取整行输入,每行末尾的换行符不被读入.在read命令后面,如果没有 ...
- bzoj 4198: [Noi2015]荷马史诗【哈夫曼树+贪心】
和合并果子类似(但是是第一次听说哈夫曼树这种东西) 做法也类似,就是因为不用知道树的形态,所以贪心的把最小的k个点合为一个节点,然后依次向上累加即可,具体做法同合并果子(但是使用优先队列 注意这里可能 ...
- 什么是GFW
GFW(Great Firewall of China)中文名:中国国家防火墙,建立于1998年.我们平常所说的“被墙了”,是指网站内容或服务被防火墙屏蔽了.而“FQ”是指突破防火墙去浏览那些被屏蔽的 ...
- linux rpm 安装
1.rpm 安装rpm -ivh package_name-i:install的意思-v:查看更详细的安装信息-h:以安装信息栏显示安装进度rpm -ivh package_name --test 2 ...
- Oracle取查询结果数据的第一条记录SQL
Oracle取查询结果数据的第一条记录SQL: ; ;