[python] 时间序列分析之ARIMA
1 时间序列与时间序列分析
在生产和科学研究中,对某一个或者一组变量 进行观察测量,将在一系列时刻 所得到的离散数字组成的序列集合,称之为时间序列。
时间序列分析是根据系统观察得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法。时间序列分析常用于国民宏观经济控制、市场潜力预测、气象预测、农作物害虫灾害预报等各个方面。
2 时间序列建模基本步骤
- 获取被观测系统时间序列数据;
- 对数据绘图,观测是否为平稳时间序列;对于非平稳时间序列要先进行d阶差分运算,化为平稳时间序列;
- 经过第二步处理,已经得到平稳时间序列。要对平稳时间序列分别求得其自相关系数ACF 和偏自相关系数PACF ,通过对自相关图和偏自相关图的分析,得到最佳的阶层 p 和阶数 q
- 由以上得到的 ,得到ARIMA模型。然后开始对得到的模型进行模型检验。
3 ARIMA实战解剖
原理大概清楚,实践却还是会有诸多问题。相比较R语言,Python在做时间序列分析的资料相对少很多。下面就通过Python语言详细解析后三个步骤的实现过程。
文中使用到这些基础库: 。 对其调用如下
- from __future__ import print_function
- import pandas as pd
- import numpy as np
- from scipy import stats
- import matplotlib.pyplot as plt
- import statsmodels.api as sm
- from statsmodels.graphics.api import qqplot
3.1 获取数据
这里我们使用一个具有周期性的测试数据,进行分析。
数据如下:
dta=[10930,10318,10595,10972,7706,6756,9092,10551,9722,10913,11151,8186,6422,
6337,11649,11652,10310,12043,7937,6476,9662,9570,9981,9331,9449,6773,6304,9355,
10477,10148,10395,11261,8713,7299,10424,10795,11069,11602,11427,9095,7707,10767,
12136,12812,12006,12528,10329,7818,11719,11683,12603,11495,13670,11337,10232,
13261,13230,15535,16837,19598,14823,11622,19391,18177,19994,14723,15694,13248,
9543,12872,13101,15053,12619,13749,10228,9725,14729,12518,14564,15085,14722,
11999,9390,13481,14795,15845,15271,14686,11054,10395]
- dta=pd.Series(dta)
- dta.index = pd.Index(sm.tsa.datetools.dates_from_range('2001','2100'))
- dta.plot(figsize=(12,8))
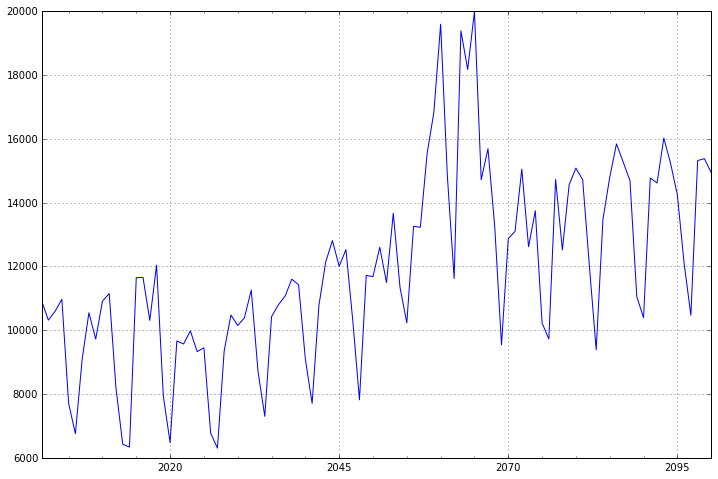
3.2 时间序列的差分
ARIMA 模型对时间序列的要求是平稳型。因此,当你得到一个非平稳的时间序列时,首先要做的即是做时间序列的差分,直到得到一个平稳时间序列。如果你对时间序列做d次差分才能得到一个平稳序列,那么可以使用ARIMA(p,d,q)模型,其中d是差分次数。
- fig = plt.figure(figsize=(12,8))
- ax1= fig.add_subplot(111)
- diff1 = dta.diff(1)
- diff1.plot(ax=ax1)
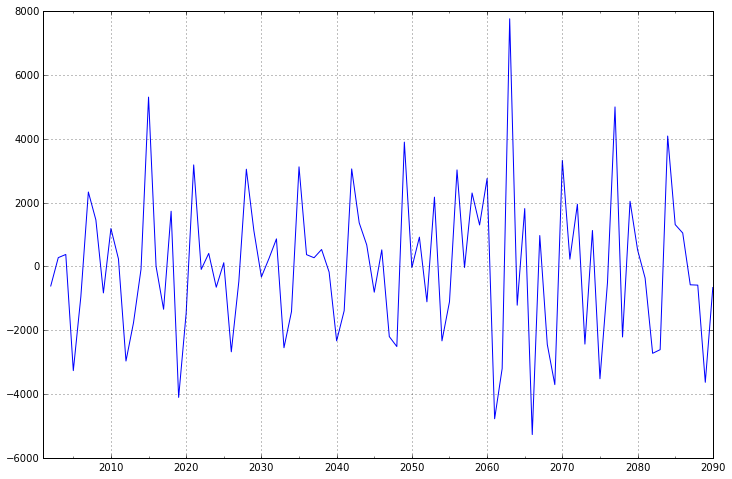
一阶差分的时间序列的均值和方差已经基本平稳,不过我们还是可以比较一下二阶差分的效果
- fig = plt.figure(figsize=(12,8))
- ax2= fig.add_subplot(111)
- diff2 = dta.diff(2)
- diff2.plot(ax=ax2)
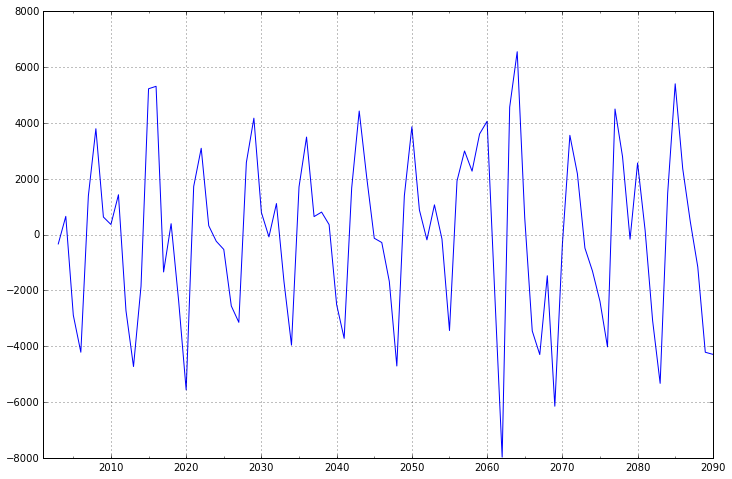
可以看出二阶差分后的时间序列与一阶差分相差不大,并且二者随着时间推移,时间序列的均值和方差保持不变。因此可以将差分次数d设置为1。
其实还有针对平稳的检验,叫“ADF单位根平稳型检验”,以后再更。
3.3 合适的
现在我们已经得到一个平稳的时间序列,接来下就是选择合适的ARIMA模型,即ARIMA模型中合适的。
第一步我们要先检查平稳时间序列的自相关图和偏自相关图。
- dta= dta.diff(1)#我们已经知道要使用一阶差分的时间序列,之前判断差分的程序可以注释掉
- fig = plt.figure(figsize=(12,8))
- ax1=fig.add_subplot(211)
- fig = sm.graphics.tsa.plot_acf(dta,lags=40,ax=ax1)
- ax2 = fig.add_subplot(212)
- fig = sm.graphics.tsa.plot_pacf(dta,lags=40,ax=ax2)
其中lags 表示滞后的阶数,以上分别得到acf 图和pacf 图 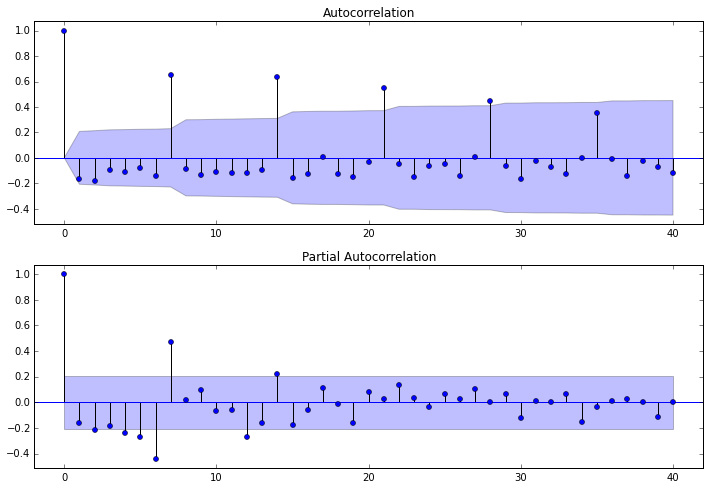
通过两图观察得到:
* 自相关图显示滞后有三个阶超出了置信边界;
* 偏相关图显示在滞后1至7阶(lags 1,2,…,7)时的偏自相关系数超出了置信边界,从lag 7之后偏自相关系数值缩小至0
则有以下模型可以供选择:
1. ARMA(0,1)模型:即自相关图在滞后1阶之后缩小为0,且偏自相关缩小至0,则是一个阶数q=1的移动平均模型;
2. ARMA(7,0)模型:即偏自相关图在滞后7阶之后缩小为0,且自相关缩小至0,则是一个阶层p=3的自回归模型;
3. ARMA(7,1)模型:即使得自相关和偏自相关都缩小至零。则是一个混合模型。
4. …还可以有其他供选择的模型
现在有以上这么多可供选择的模型,我们通常采用ARMA模型的AIC法则。我们知道:增加自由参数的数目提高了拟合的优良性,AIC鼓励数据拟合的优良性但是尽量避免出现过度拟合(Overfitting)的情况。所以优先考虑的模型应是AIC值最小的那一个。赤池信息准则的方法是寻找可以最好地解释数据但包含最少自由参数的模型。不仅仅包括AIC准则,目前选择模型常用如下准则:
* AIC=-2 ln(L) + 2 k 中文名字:赤池信息量 akaike information criterion
* BIC=-2 ln(L) + ln(n)*k 中文名字:贝叶斯信息量 bayesian information criterion
* HQ=-2 ln(L) + ln(ln(n))*k hannan-quinn criterion
构造这些统计量所遵循的统计思想是一致的,就是在考虑拟合残差的同时,依自变量个数施加“惩罚”。但要注意的是,这些准则不能说明某一个模型的精确度,也即是说,对于三个模型A,B,C,我们能够判断出C模型是最好的,但不能保证C模型能够很好地刻画数据,因为有可能三个模型都是糟糕的。
- arma_mod20 = sm.tsa.ARMA(dta,(7,0)).fit()
- print(arma_mod20.aic,arma_mod20.bic,arma_mod20.hqic)
- arma_mod30 = sm.tsa.ARMA(dta,(0,1)).fit()
- print(arma_mod30.aic,arma_mod30.bic,arma_mod30.hqic)
- arma_mod40 = sm.tsa.ARMA(dta,(7,1)).fit()
- print(arma_mod40.aic,arma_mod40.bic,arma_mod40.hqic)
- arma_mod50 = sm.tsa.ARMA(dta,(8,0)).fit()
- print(arma_mod50.aic,arma_mod50.bic,arma_mod50.hqic)
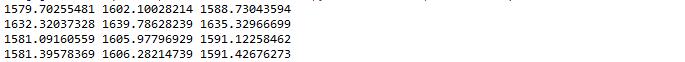
可以看到ARMA(7,0)的aic,bic,hqic均最小,因此是最佳模型。
3.4 模型检验
在指数平滑模型下,观察ARIMA模型的残差是否是平均值为0且方差为常数的正态分布(服从零均值、方差不变的正态分布),同时也要观察连续残差是否(自)相关。
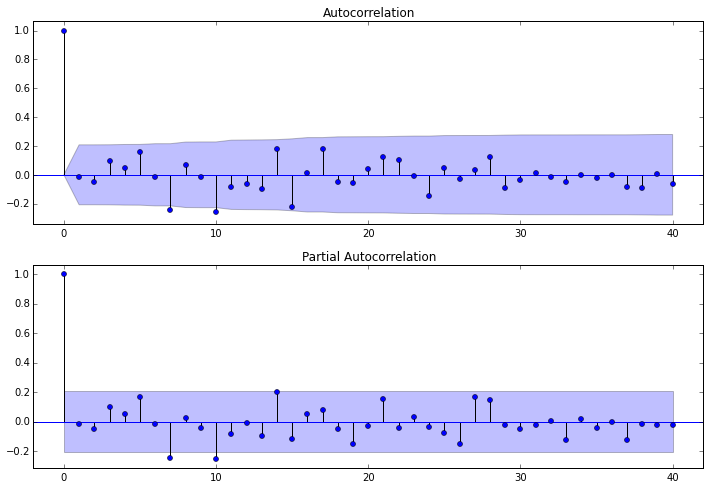
3.4.1 我们对ARMA(7,0)模型所产生的残差做自相关图
- fig = plt.figure(figsize=(12,8))
- ax1 = fig.add_subplot(211)
- fig = sm.graphics.tsa.plot_acf(resid.values.squeeze(), lags=40, ax=ax1)
- ax2 = fig.add_subplot(212)
- fig = sm.graphics.tsa.plot_pacf(resid, lags=40, ax=ax2)
3.4.2 做D-W检验
德宾-沃森(Durbin-Watson)检验。德宾-沃森检验,简称D-W检验,是目前检验自相关性最常用的方法,但它只使用于检验一阶自相关性。因为自相关系数ρ的值介于-1和1之间,所以 0≤DW≤4。并且DW=O=>ρ=1 即存在正自相关性
DW=4<=>ρ=-1 即存在负自相关性
DW=2<=>ρ=0 即不存在(一阶)自相关性
因此,当DW值显著的接近于O或4时,则存在自相关性,而接近于2时,则不存在(一阶)自相关性。这样只要知道DW统计量的概率分布,在给定的显著水平下,根据临界值的位置就可以对原假设H0进行检验。
print(sm.stats.durbin_watson(arma_mod20.resid.values))
检验结果是2.02424743723,说明不存在自相关性。
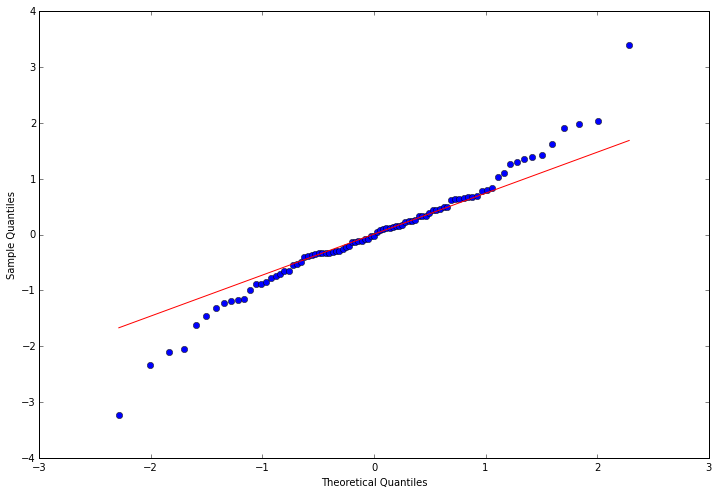
3.4.3 观察是否符合正态分布
这里使用QQ图,它用于直观验证一组数据是否来自某个分布,或者验证某两组数据是否来自同一(族)分布。在教学和软件中常用的是检验数据是否来自于正态分布。QQ图细节,下次再更。
- resid = arma_mod20.resid#残差
- fig = plt.figure(figsize=(12,8))
- ax = fig.add_subplot(111)
- fig = qqplot(resid, line='q', ax=ax, fit=True)
3.4.4 Ljung-Box检验
Ljung-Box test是对randomness的检验,或者说是对时间序列是否存在滞后相关的一种统计检验。对于滞后相关的检验,我们常常采用的方法还包括计算ACF和PCAF并观察其图像,但是无论是ACF还是PACF都仅仅考虑是否存在某一特定滞后阶数的相关。LB检验则是基于一系列滞后阶数,判断序列总体的相关性或者说随机性是否存在。
时间序列中一个最基本的模型就是高斯白噪声序列。而对于ARIMA模型,其残差被假定为高斯白噪声序列,所以当我们用ARIMA模型去拟合数据时,拟合后我们要对残差的估计序列进行LB检验,判断其是否是高斯白噪声,如果不是,那么就说明ARIMA模型也许并不是一个适合样本的模型。
- r,q,p = sm.tsa.acf(resid.values.squeeze(), qstat=True)
- data = np.c_[range(1,41), r[1:], q, p]
- table = pd.DataFrame(data, columns=['lag', "AC", "Q", "Prob(>Q)"])
- print(table.set_index('lag'))
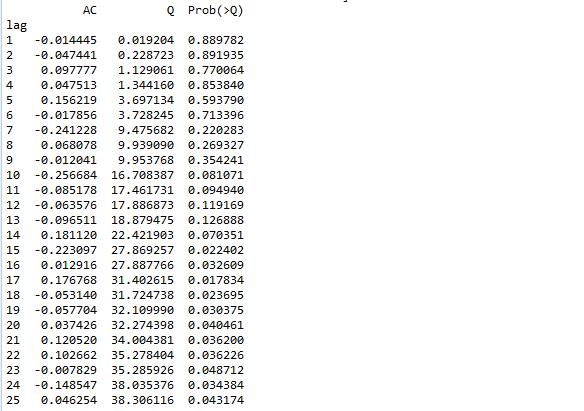
检验的结果就是看最后一列前十二行的检验概率(一般观察滞后1~12阶),如果检验概率小于给定的显著性水平,比如0.05、0.10等就拒绝原假设,其原假设是相关系数为零。就结果来看,如果取显著性水平为0.05,那么相关系数与零没有显著差异,即为白噪声序列。
3.5 模型预测
模型确定之后,就可以开始进行预测了,我们对未来十年的数据进行预测。
- predict_sunspots = arma_mod20.predict('2090', '2100', dynamic=True)
- print(predict_sunspots)
- fig, ax = plt.subplots(figsize=(12, 8))
- ax = dta.ix['2001':].plot(ax=ax)
- predict_sunspots.plot(ax=ax)
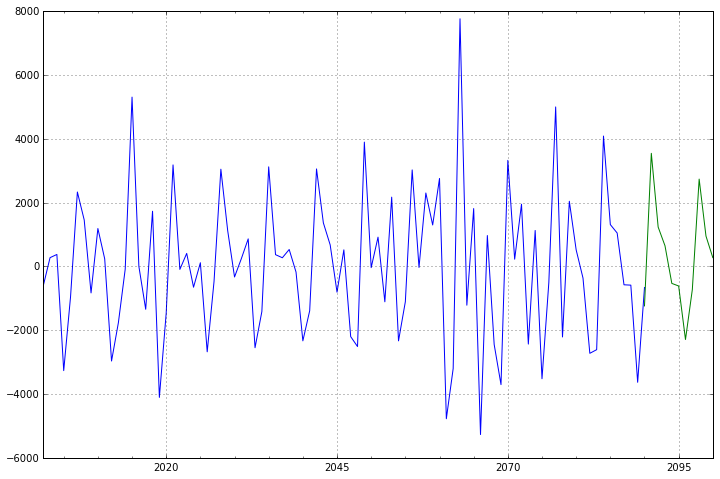
前面90个数据为测试数据,最后10个为预测数据;从图形来,预测结果较为合理。至此,本案例的时间序列分析也就结束了。
参考文献与推荐阅读
[python] 时间序列分析之ARIMA的更多相关文章
- 【R实践】时间序列分析之ARIMA模型预测___R篇
时间序列分析之ARIMA模型预测__R篇 之前一直用SAS做ARIMA模型预测,今天尝试用了一下R,发现灵活度更高,结果输出也更直观.现在记录一下如何用R分析ARIMA模型. 1. 处理数据 1.1. ...
- python时间序列分析
题记:毕业一年多天天coding,好久没写paper了.在这动荡的日子里,也希望写点东西让自己静一静.恰好前段时间用python做了一点时间序列方面的东西,有一丁点心得体会想和大家 ...
- 用R做时间序列分析之ARIMA模型预测
昨天刚刚把导入数据弄好,今天迫不及待试试怎么做预测,网上找的帖子跟着弄的. 第一步.对原始数据进行分析 一.ARIMA预测时间序列 指数平滑法对于预测来说是非常有帮助的,而且它对时间序列上面连续的值之 ...
- 时间序列分析之ARIMA模型预测__R篇
http://www.cnblogs.com/bicoffee/p/3838049.html
- 时间序列模式(ARIMA)---Python实现
时间序列分析的主要目的是根据已有的历史数据对未来进行预测.如餐饮销售预测可以看做是基于时间序列的短期数据预测, 预测的对象时具体菜品的销售量. 1.时间序列算法: 常见的时间序列模型; 2.时序模 ...
- SPSS时间序列分析
时间序列分析必须建立在预处理的基础上…… 今天看了一条新闻体会到了网络日志的重要性…… 指数平滑法(Exponential Smoothing,ES)是布朗(Robert G..Brown)所提出,布 ...
- 时间序列分析算法【R详解】
简介 在商业应用中,时间是最重要的因素,能够提升成功率.然而绝大多数公司很难跟上时间的脚步.但是随着技术的发展,出现了很多有效的方法,能够让我们预测未来.不要担心,本文并不会讨论时间机器,讨论的都是很 ...
- pandas小记:pandas时间序列分析和处理Timeseries
http://blog.csdn.net/pipisorry/article/details/52209377 其它时间序列处理相关的包 [P4J 0.6: Periodic light curve ...
- 时间序列分析工具箱——sweep
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/kMD8d5R/article/details/81977856 作者:徐瑞龙.量化分析师,R语言中文 ...
随机推荐
- 前端之html第二天
一.内容
- CentOS 6.6实现永久修改DNS地址的方法
本文实例讲述了CentOS 6.6实现永久修改DNS地址的方法. 百牛信息技术bainiu.ltd整理发布于博客园 分享给大家供大家参考,具体如下:1.配置ip地址文件 /etc/sysconfig/ ...
- appium学习【一】:pycharm运行不生成HtmlTestRunner测试报告
参考文章和解决办法:http://blog.csdn.net/xie_0723/article/details/50825310 http://jingyan.bai ...
- word-break word-wrap
work-break:break-all CJK超出的部分自动换行 word-wrap:break-word CJK如果有分隔符,当前分隔符之后与下一个分隔符之间的内容不能在这一行全部显示的话,在当前 ...
- null、undefined和NaN的简洁比较
Null 类型也只有一个值,即null.null用来表示尚未存在的对象,常用来表示函数企图返回一个不存在的对象.Undefined 类型只有一个值,即undefined.当声明的变量还未被初始化时,变 ...
- phpstorm最新破解办法(2016-10-30)
还是选择license server.然后复制http://jetbrains.tencent.click/ 这个地址进去就可以啦.不行的时候欢迎留言告知,更新破解方法
- springboot(十一)SpringBoot任务
github地址: https://github.com/showkawa/springBoot_2017/tree/master/spb-demo/spb-brian-query-service 1 ...
- Unix\Linux | 总结笔记 | man帮助
0.目录 手册页分类说明 man手册中的段落说明 1. man手册页分类 man1 普通用户可以执行的命令帮助 man2 系统调用.内核函数的说明帮助 man3 库函数说明帮助 ma ...
- [Usaco2013 Jan]Island Travels
Description Farmer John has taken the cows to a vacation out on the ocean! The cows are living on N ...
- Poj 2112 Optimal Milking (多重匹配+传递闭包+二分)
题目链接: Poj 2112 Optimal Milking 题目描述: 有k个挤奶机,c头牛,每台挤奶机每天最多可以给m头奶牛挤奶.挤奶机编号从1到k,奶牛编号从k+1到k+c,给出(k+c)*(k ...