C#主要字典集合性能对比[转]
A post I made a couple days ago about the side-effect of concurrency (the concurrent collections in the .Net 4.0 Parallel Extensions) allowing modifications to collections while enumerating them has been quite popular, with a lot of attention coming from www.dotnetguru.org, what appears to be a French-language news/aggregation site (I only know enough French to get my face slapped, so it’s hard for me to tell). I’m not sure why the post would be so popular in France, but the Internet’s weird that way … things take off for unexpected reasons.
Regardless, it occurred to me that some further research might be in order, before folks get all hot for .Net 4.0 and want to change their collections so they can be modified while enumerating. The question is: what’s the performance penalty for these threadsafe collections? If I use one in a single-threaded environment, just to get that modification capability, is the performance-price something I’m willing to pay?
So I set up a simple test to satisfy my curiosity – but first the test platform (your mileage may vary):
- The test was done using the Visual Studio 2010 CTP, converted to run under Windows Server 2008 Hyper-V.
- The virtual server was set to use all four cores on the test machine and have 3GB of RAM.
- The host CPU was a Q9100 quad-core, 2.26 GHz, with 4GB.
It’s also important to note that the Dictionary class has been around for a while and my guess is it’s been optimized once or twice, while the ConcurrentDictionary is part of a CTP.
The test is set up as two loops – the first a for that adds a million items to a Dictionary; the second a foreach that enumerates them:
1: static void Main(string[] args)
2: {
3: var dictionary = new Dictionary<int, DateTime>();
4:
5: var watch = Stopwatch.StartNew();
6:
7: for (int i = 0; i < 1000000; i++)
8: {
9: dictionary.Add(i, DateTime.Now);
10: }
11:
12: watch.Stop();
13: Console.WriteLine("Adding: {0}", watch.ElapsedMilliseconds);
14:
15: int count = 0;
16: watch.Reset();
17: watch.Start();
18: foreach (var item in dictionary)
19: {
20: count += item.Key;
21: }
22:
23: watch.Stop();
24: Console.WriteLine("Enumerating: {0}", watch.ElapsedMilliseconds);
25: Console.ReadLine();
26:
27: }
Not the most scientific of tests, nor the most comprehensive, but enough to sate my curious-bone until I have time to do a more thorough analysis. Running this nine times, I got the following results:
| Adding: | Enumerating: | |
| 2235 | 41 | |
| 1649 | 39 | |
| 1781 | 39 | |
| 1587 | 45 | |
| 2001 | 46 | |
| 1895 | 40 | |
| 1540 | 39 | |
| 1587 | 40 | |
| 2081 | 46 | |
| Average: | 1817 | 41 |
Then I changed to a ConcurrentDictionary (also note the change from Add() to TryAdd() on line 9):
1: static void Main(string[] args)
2: {
3: var dictionary = new ConcurrentDictionary<int, DateTime>();
4:
5: var watch = Stopwatch.StartNew();
6:
7: for (int i = 0; i < 1000000; i++)
8: {
9: dictionary.TryAdd(i, DateTime.Now);
10: }
11:
12: watch.Stop();
13: Console.WriteLine("Adding: {0}", watch.ElapsedMilliseconds);
14:
15: int count = 0;
16: watch.Reset();
17: watch.Start();
18: foreach (var item in dictionary)
19: {
20: count += item.Key;
21: }
22:
23: watch.Stop();
24: Console.WriteLine("Enumerating: {0}", watch.ElapsedMilliseconds);
25: Console.ReadLine();
26:
27: }
This change resulted in the following times:
| Adding: | Enumerating: | |
| 4332 | 80 | |
| 3795 | 80 | |
| 4560 | 77 | |
| 5489 | 75 | |
| 4283 | 76 | |
| 3734 | 74 | |
| 4288 | 79 | |
| 4904 | 96 | |
| 3591 | 83 | |
| Average: | 4330 | 80 |
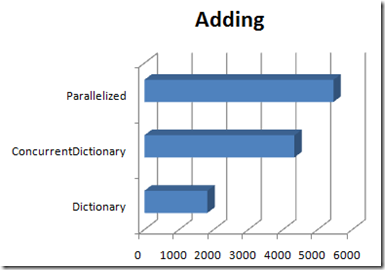
So there’s clearly a performance difference, with the ConcurrentDictionary being slower, but keep in mind a few key facts:
- Again, we’re running the CTP of .Net 4.0, so ConcurrentDictionary is new code that hasn’t been optimized yet, while Dictionary is probably unchanged from previous framework versions;
- We’re dealing with a million-item collection here, and the enumeration time-difference is an average of 39-milliseconds, or 0.000000039-seconds per item in the collection;
The time necessary to do the adding is more troublesome to me, but in dealing with a million-item set, is it really that unreasonable? That’s a design decision you’d have to make for your application.
Having satisfied the curiosity-beast to a certain extent, yet another question arose (curiosity is like that): Since this post came about from the ability to alter a collection while enumerating it, what effect would that have on the numbers? So I changed the code to remove each item from the collection as it enumerates:
1: var dictionary = new ConcurrentDictionary<int, DateTime>();
2:
3: var watch = Stopwatch.StartNew();
4:
5: for (int i = 0; i < 1000000; i++)
6: {
7: dictionary.TryAdd(i, DateTime.Now);
8: }
9:
10: watch.Stop();
11: Console.WriteLine("Adding: {0}", watch.ElapsedMilliseconds);
12:
13: int count = 0;
14: watch.Reset();
15: watch.Start();
16: foreach (var item in dictionary)
17: {
18: count += item.Key;
19: DateTime temp;
20: dictionary.TryRemove(item.Key, out temp);
21: }
22:
23: watch.Stop();
24: Console.WriteLine("Enumerating: {0}", watch.ElapsedMilliseconds);
25: Console.WriteLine("Items in Dictionary: {0}", dictionary.Count);
26: Console.ReadLine();
Which added significantly to the enumeration time:
| Adding: | Enumerating: | |
| 4162 | 258 | |
| 4124 | 201 | |
| 4592 | 239 | |
| 3959 | 333 | |
| 4155 | 252 | |
| 4026 | 269 | |
| 4573 | 283 | |
| 4471 | 204 | |
| 5434 | 258 | |
| Average: | 4388 | 255 |
Removing the current item from the collection during enumeration triples the time spent in the foreach loop – a disturbing development, but we’re still talking about a total of a quarter-second to process a million items, so maybe not worrisome? Depends on your application and how many items you actually have to process – and other processing that you may have to do.
Now, with the whole purpose of the concurrent collections being parallel development, you have to know that I couldn’t leave it without doing one more test. After all, those two loops have been sitting there this entire post fairly screaming to try parallelizing them with Parallel.For and Parallel.ForEach:
1: var dictionary = new ConcurrentDictionary<int, DateTime>();
2:
3: var watch = Stopwatch.StartNew();
4:
5: Parallel.For(0, 1000000, (i) =>
6: {
7: dictionary.TryAdd(i, DateTime.Now);
8: }
9: );
10:
11: watch.Stop();
12: Console.WriteLine("Adding: {0}", watch.ElapsedMilliseconds);
13:
14: int count = 0;
15: watch.Reset();
16: watch.Start();
17:
18: Parallel.ForEach(dictionary, (item) =>
19: {
20: // count += item.Key;
21: DateTime temp;
22: dictionary.TryRemove(item.Key, out temp);
23: }
24: );
25:
26: watch.Stop();
27: Console.WriteLine("Enumerating: {0}", watch.ElapsedMilliseconds);
28: Console.WriteLine("Items in Dictionary: {0}", dictionary.Count);
29: Console.ReadLine();
| Adding: | Enumerating: | |
| 7550 | 482 | |
| 4433 | 464 | |
| 7534 | 482 | |
| 4452 | 464 | |
| 4216 | 393 | |
| 3441 | 264 | |
| 6094 | 483 | |
| 5953 | 676 | |
| 5462 | 446 | |
| Average: | 5459 | 462 |
Not good numbers at all, but not unexpected when you think about it. Each iteration of the two loops would become a Task when parallelized, which means we’re incurring the overhead of instantiating two million Task objects, scheduling them and executing them – but each Task consists of very little code; code that doesn’t take that long to begin with, so any performance improvement we gain by executing in parallel is offset (and more) by the overhead of managing the Tasks. Something to keep in mind as you’re looking for parallelization candidates in a real application.
So what about the more traditional way of handling this – the situation where we make the decision to remove an item from a collection while enumerating over it. Typically we’d probably make a list of the items to be removed, then remove them after the first enumeration was complete.
1: var dictionary = new Dictionary<int, DateTime>();
2:
3: var watch = Stopwatch.StartNew();
4:
5: for (int i = 0; i < 1000000; i++)
6: {
7: dictionary.Add(i, DateTime.Now);
8: }
9:
10: watch.Stop();
11: Console.WriteLine("Adding: {0}", watch.ElapsedMilliseconds);
12:
13: watch.Reset();
14: watch.Start();
15: var toRemove = new List<int>();
16:
17: foreach (var item in dictionary)
18: {
19: toRemove.Add(item.Key);
20: }
21: foreach (var item in toRemove)
22: {
23: dictionary.Remove(item);
24: }
25:
26: watch.Stop();
27: Console.WriteLine("Enumerating: {0}", watch.ElapsedMilliseconds);
| Enumerating: | |
| 190 | |
| 266 | |
| 106 | |
| 113 | |
| 129 | |
| 105 | |
| 107 | |
| 142 | |
| 117 | |
| Average: | 141 |
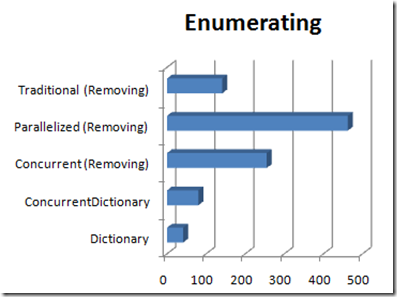
Based on this limited test, the traditional method of waiting until the first enumeration of a collection is complete before removing items from it appears to still be the most efficient.
Adding to a Dictionary is faster than adding to a ConcurrentDictionary, even if the adding is parallelized … provided the parallelized code is so brief that the overhead of parallelization outweighs the benefits. That last bit is important, because if the parallelized example had done significantly more than just add an item to a Dictionary, the results would likely be different.
When enumerating the items in a collection, the simple Dictionary again proves faster than ConcurrentDictionary; and when actually modifying the collection by removing items, the traditional method of building a list of items to remove and then doing so after the foreach is complete proves to be fastest.
Does this mean that you should never use one of the new concurrent collections in this way?
That’s a design decision that you’ll have to make based on your particular application. Keeping in mind that the concurrent collections are still in CTP and will likely improve dramatically in performance by the time .Net 4 is released – but also that the very nature of making them threadsafe and, consequently, able to be modified while enumerating will likely mean that they’re always going to be somewhat less performant than their counterparts.
There may be instances, though, where making the decision to sacrifice performance for this capability is the best solution. For instance, what if the results of processing one item in the collection result in a need to remove an item (or items) that haven’t been processed yet?
In that case, simply removing the item at the point the decision’s made, rather than maintaining a list of items not to be processed, might be the simplest, most maintainable solution and sacrificing a bit of performance might be worth it. Like so many things in software development, the answer is simple …
It depends.
Added 04/03/09: One thing I should probably stress more is that these numbers are reflective the use (or misuse[?]) of the concurrent collection in a single-threaded environment. The premise is “what’s the price I pay for being able to modify the collection while enumerating”. As such, this post is really about the performance hit of doing a couple things you maybe shouldn’t be doing in the first place: i.e. using a concurrent collection in a single-thread or parallelizing a million-iteration loop with one line of code in it (!).
As Josh Phillips points out in the Comments, an optimized version of the collection, used for what it’s intended, has much better numbers – but a post on those has to wait until the betas or RCs are available and I can play with the newer bits. Boy … sure would like some newer bits to play with … wonder who could get me those … <insert subtle raise of eyebrows here>
;)
C#主要字典集合性能对比[转]的更多相关文章
- Java 集合 ArrayList和LinkedList的几种循环遍历方式及性能对比分析 [ 转载 ]
Java 集合 ArrayList和LinkedList的几种循环遍历方式及性能对比分析 @author Trinea 原文链接:http://www.trinea.cn/android/arrayl ...
- 2019-11-29-C#-字典-Dictionary-的-TryGetValue-与先判断-ContainsKey-然后-Get-的性能对比
原文:2019-11-29-C#-字典-Dictionary-的-TryGetValue-与先判断-ContainsKey-然后-Get-的性能对比 title author date CreateT ...
- 2019-8-31-C#-字典-Dictionary-的-TryGetValue-与先判断-ContainsKey-然后-Get-的性能对比
title author date CreateTime categories C# 字典 Dictionary 的 TryGetValue 与先判断 ContainsKey 然后 Get 的性能对比 ...
- C# 字典 Dictionary 的 TryGetValue 与先判断 ContainsKey 然后 Get 的性能对比
本文使用 benchmarkdotnet 测试字典的性能,在使用字典获取一个可能存在的值的时候可以使用两个不同的写法,于是本文分析两个写法的性能. 判断值存在,如果值存在就获取值,可以使用下面两个不同 ...
- ArrayList和LinkedList的几种循环遍历方式及性能对比分析(转)
主要介绍ArrayList和LinkedList这两种list的五种循环遍历方式,各种方式的性能测试对比,根据ArrayList和LinkedList的源码实现分析性能结果,总结结论. 通过本文你可以 ...
- ArrayList和LinkedList的几种循环遍历方式及性能对比分析
最新最准确内容建议直接访问原文:ArrayList和LinkedList的几种循环遍历方式及性能对比分析 主要介绍ArrayList和LinkedList这两种list的五种循环遍历方式,各种方式的性 ...
- ArrayList和LinkedList的几种循环遍历方式及性能对比分析(转载)
原文地址: http://www.trinea.cn/android/arraylist-linkedlist-loop-performance/ 原文地址: http://www.trinea.cn ...
- HashMap循环遍历方式及其性能对比(zhuan)
http://www.trinea.cn/android/hashmap-loop-performance/ ********************************************* ...
- ArrayList和LinkedList遍历方式及性能对比分析
ArrayList和LinkedList的几种循环遍历方式及性能对比分析 主要介绍ArrayList和LinkedList这两种list的五种循环遍历方式,各种方式的性能测试对比,根据ArrayLis ...
随机推荐
- 面向切面编程(AOP)的理解
在传统的编写业务逻辑处理代码时,我们通常会习惯性地做几件事情:日志记录.事务控制及权限控制等,然后才是编写核心的业务逻辑处理代码.当代码编写完成回头再看时,不禁发现,扬扬洒洒上百行代码中,真正用于核心 ...
- 利用PHPExcel转Excel柱形图
这在附还有一个转柱形图的效果及代码. 原PHP报表效果: 转成Excel后的效果: 附上代码: <? php /** * PHPExcel * * Copyright (C) 2006 - 20 ...
- [HeadFirst-HTMLCSS入门][第十章div,span]
新元素 <div>逻辑容器 能进行分组,等于用一个大的盒子进行包装 <span> 内联字符的逻辑分组 text-align 改变所有内联元素位置. 属性 center 居中 行 ...
- 图片轮播插件 Slides-SlidesJS-3
图片轮播插件 Slides-SlidesJS-3 demo document 地址: http://slidesjs.com/
- 多个Activity和Intent(转)
根据www.mars-droid.com:Andriod开发视频教学,先跳过书本<Beginning Android 2>的几个章,我是这两个资源一起看,需要进行一下同步.先初步了解一下应 ...
- 提示框的优化之自定义Toast组件之(一)Toast组件的布局实现
开发步骤: 在res下layout下创建一个Toast的布局资源文件toast_customer.xml 在最外层布局组件中为该布局添加android:id属性 //toast_custo ...
- Web系统如何做到读取客户电脑MAC等硬件信息且兼容非IE浏览器
我们在实际Web应用中,可能会遇到“需要限定特定的电脑或用户才能使用系统”的问题. 对于一般情况来说,我们用得最多的可能是使用ActiveX控件的方法来实现,但此方案只适用于IE浏览器.为了能兼容不同 ...
- 写个点击input框 下方弹出月份时间等
<input type="text" name="test" id="test" value="" "& ...
- Java中的IO学习总结
今天刚刚看完java的io流操作,把主要的脉络看了一遍,不能保证以后使用时都能得心应手,但是最起码用到时知道有这么一个功能可以实现,下面对学习进行一下简单的总结: IO流主要用于硬盘.内存.键盘等处理 ...
- PHP内置函数getimagesize()的漏洞
今天程序想压缩一些图片,想获取图片的宽高,在网上查了一下哪些函数可以使用,然后看到getimagesize()这个函数.但是当同事看到这个函数,提醒我说这个函数,运营同事禁止使用.心里就很奇怪,就在网 ...