TensorFlow文本与序列的深度模型
TensorFlow深度学习笔记 文本与序列的深度模型
Deep Models for Text and Sequence
转载请注明作者:梦里风林
Github工程地址:https://github.com/ahangchen/GDLnotes
欢迎star,有问题可以到Issue区讨论
官方教程地址
视频/字幕下载
Rare Event
与其他机器学习不同,在文本分析里,陌生的东西(rare event)往往是最重要的,而最常见的东西往往是最不重要的。
语法多义性
- 一个东西可能有多个名字,对这种related文本能够做参数共享是最好的
- 需要识别单词,还要识别其关系,就需要过量label数据
无监督学习
- 不用label进行训练,训练文本是非常多的,关键是要找到训练的内容
- 遵循这样一个思想:相似的词汇出现在相似的场景中
- 不需要知道一个词真实的含义,词的含义由它所处的历史环境决定
Embeddings
- 将单词映射到一个向量(Word2Vec),越相似的单词的向量会越接近
- 新的词可以由语境得到共享参数
Word2Vec
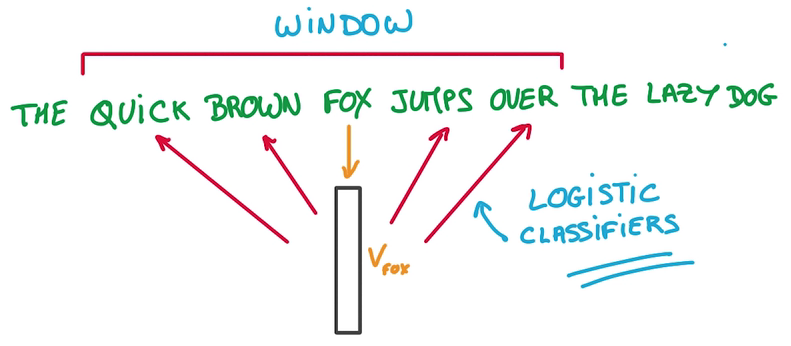
- 将每个词映射到一个Vector列表(就是一个Embeddings)里,一开始随机,用这个Embedding进行预测
- Context即Vector列表里的邻居
- 目标是让Window里相近的词放在相邻的位置,即预测一个词的邻居
用来预测这些相邻位置单词的模型只是一个Logistics Regression, just a simple Linear model
Comparing embeddings
比较两个vector之间的夹角大小来判断接近程度,用cos值而非L2计算,因为vector的长度和分类是不相关的:
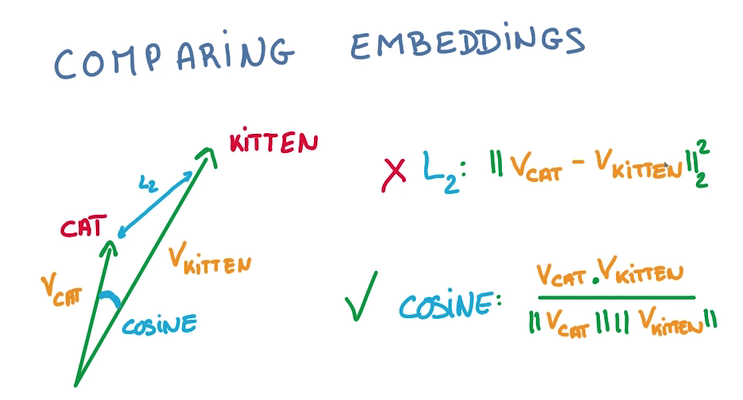
- 最好将要计算的vector都归一化
Predict Words
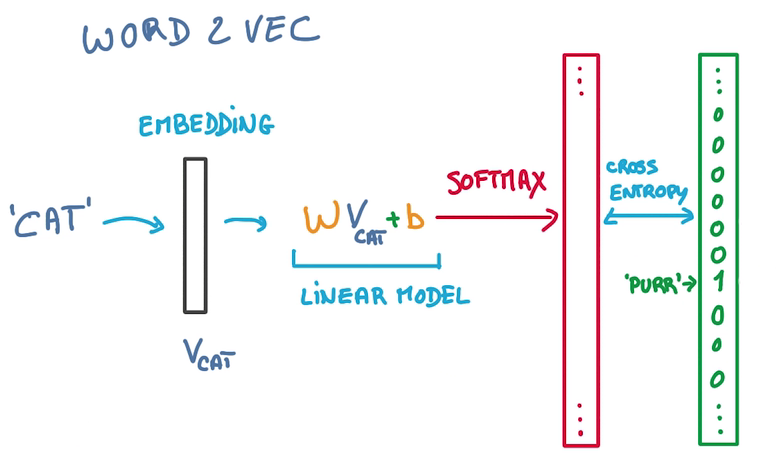
- 单词经过embedding变成一个vector
- 然后输入一个WX+b,做一个线性模型
- 输出的label概率为输入文本中的词汇
- 问题在于WX+b输出时,label太多了,计算这种softmax很低效
- 解决方法是,筛掉不可能是目标的label,只计算某个label在某个局部的概率,sample softmax
t-SNE
- 查看某个词在embedding里的最近邻居可以看到单词间的语义接近关系
- 将vector构成的空间降维,可以更高效地查找最近单词,但降维过程中要保持邻居关系(原来接近的降维后还要接近)
- t-SNE就是这样一种有效的方法
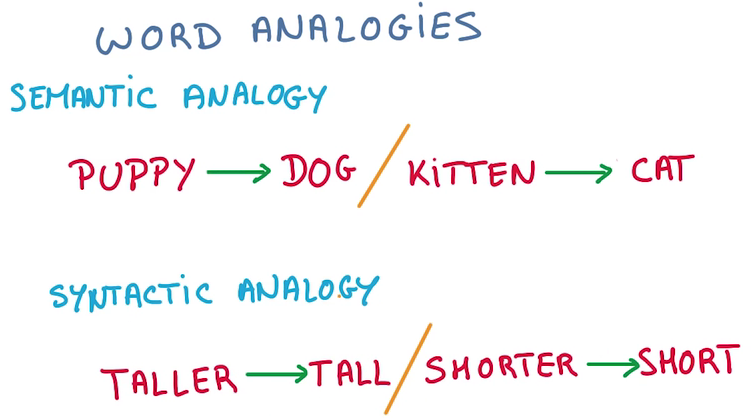
类比
- 实际上我们能得到的不仅是单词的邻接关系,由于将单词向量化,可以对单词进行计算
- 可以通过计算进行语义加减,语法加减

Sequence
文本(Text)是单词(word)的序列,一个关键特点是长度可变,就不能直接变为vector
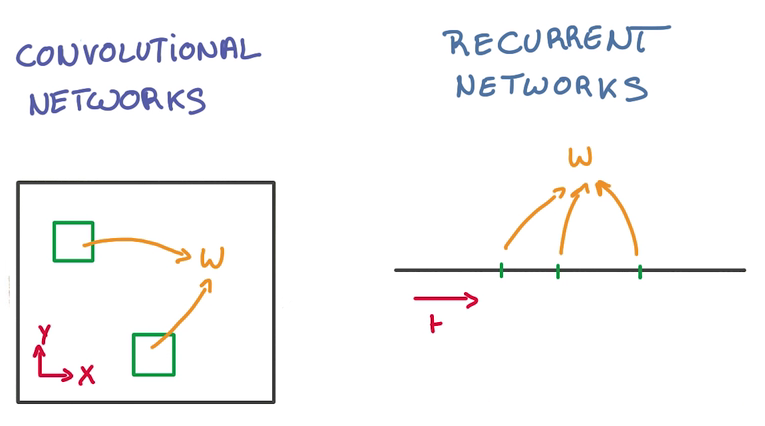
CNN and RNN
CNN 在空间上共享参数,RNN在时间上(顺序上)共享参数
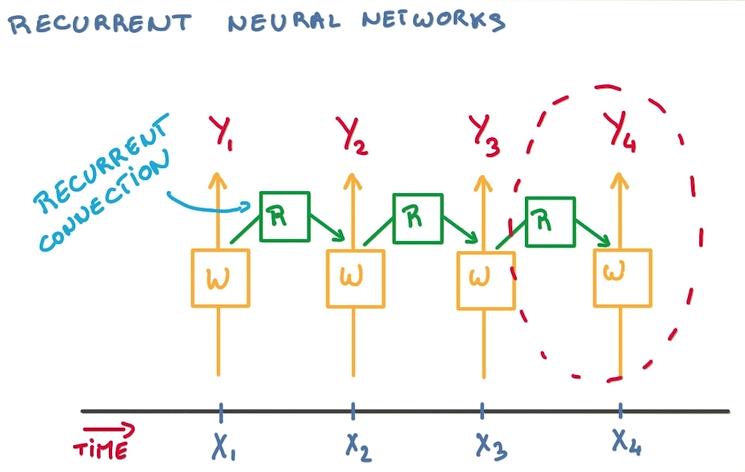
- 在每轮训练中,需要判断至今为之发生了什么,过去输入的所有数据都对当下的分类造成影响
- 一种思路是记忆之前的分类器的状态,在这个基础上训练新的分类器,从而结合历史影响
- 这样需要大量历史分类器
- 重用分类器,只用一个分类器总结状态,其他分类器接受对应时间的训练,然后传递状态
RNN Derivatives
- BackPropagation Through time
- 对同一个weight参数,会有许多求导操作同时更新之
- 对SGD不友好,因为SGD是用许多不相关的求导更新参数,以保证训练的稳定性
- 由于梯度之间的相关性,导致梯度爆炸或者梯度消失
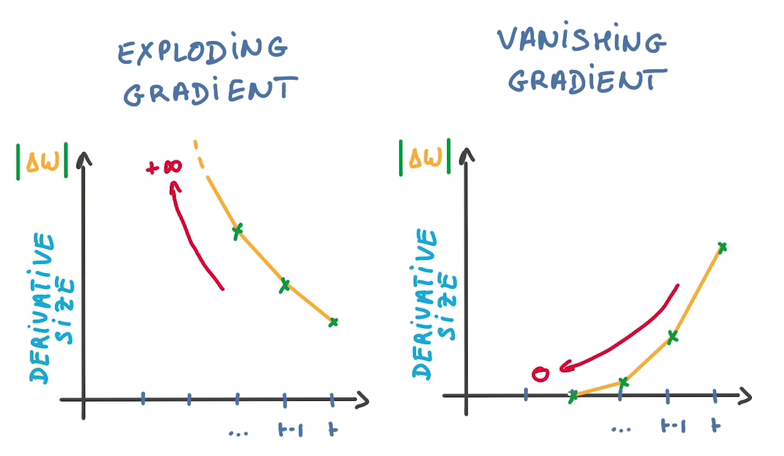
- 使得训练时找不到优化方向,训练失败
Clip Gradient
计算到梯度爆炸的时候,使用一个比值来代替△W(梯度是回流计算的,横坐标从右往左看)
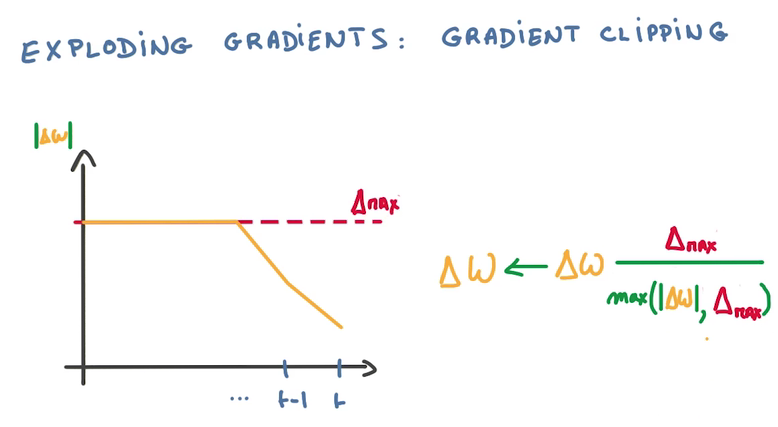
- Hack but cheap and effective
LSTM(Long Short-Term Memory)
梯度消失会导致分类器只对最近的消息的变化有反应,淡化以前训练的参数,也不能用比值的方法来解决
- 一个RNN的model包含两个输入,一个是过去状态,一个是新的数据,两个输出,一个是预测,一个是将来状态
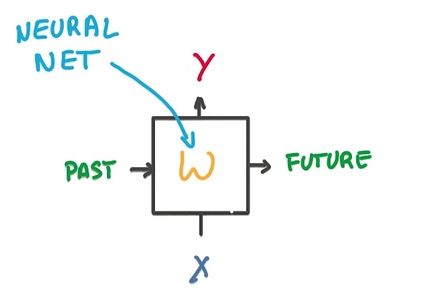
- 中间是一个简单的神经网络
- 将中间的部分换成LSTM-cell就能解决梯度消失问题
- 我们的目的是提高RNN的记忆能力
- Memory Cell

三个门,决定是否写/读/遗忘/写回
- 在每个门上,不单纯做yes/no的判断,而是使用一个权重,决定对输入的接收程度
- 这个权重是一个连续的函数,可以求导,也就可以进行训练,这是LSTM的核心

- 用一个逻辑回归训练这些门,在输出进行归一化
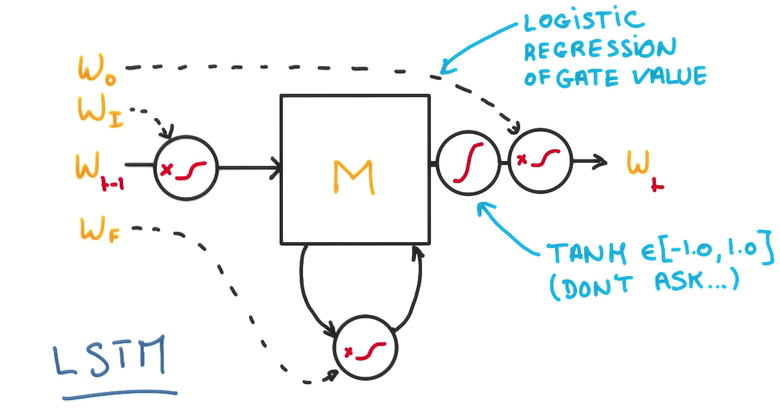
- 这样的模型能让整个cell更好地记忆与遗忘
- 由于整个模型都是线性的,所以可以方便地求导和训练
LSTM Regularization
- L2, works
- Dropout on the input or output of data, works
Beam Search
有了上面的模型之后,我们可以根据上文来推测下文,甚至创造下文,预测,筛选最大概率的词,喂回,继续预测……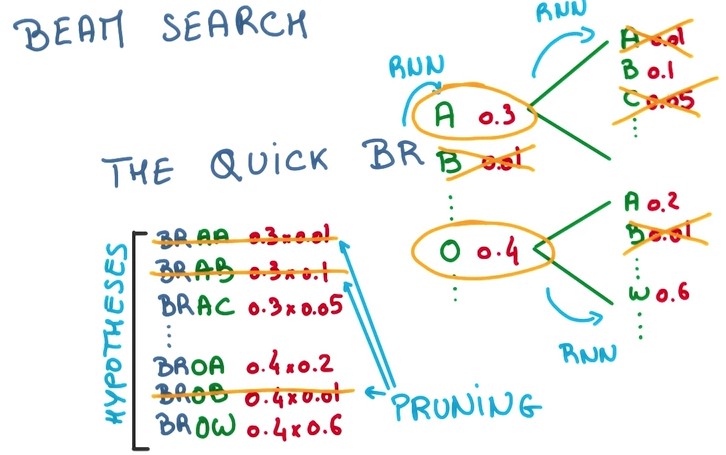
- 我们可以每次只预测一个字母,but this is greedy,每次都挑最好的那个
- 也可以每次多预测几步,然后挑整体概率较高的那个,以减少偶然因素的影响
- 但这样需要生成的sequence会指数增长
- 因此我们在多预测几步的时候,只为概率比较高的几个候选项做预测,that's beam search.
翻译与识图
RNN将variable length sequence问题变成了fixed length vector问题,同时因为实际上我们能利用vector进行预测,我们也可以将vector变成sequence
- 我们可以利用这一点,输入一个序列,到一个RNN里,将输出输入到另一个逆RNN序列,形成另一种序列,比如,语言翻译
如果我们将CNN的输出接到一个RNN,就可以做一种识图系统
循环神经网络实践
TensorFlow文本与序列的深度模型的更多相关文章
- TensorFlow深度学习笔记 文本与序列的深度模型
Deep Models for Text and Sequence 转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎st ...
- TensorFlow文本情感分析实现
TensorFlow文本情感分析实现 前面介绍了如何将卷积网络应用于图像.本文将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句子或文档表示为矩阵,则该矩阵与其中每个单元 ...
- 代码详解:TensorFlow Core带你探索深度神经网络“黑匣子”
来源商业新知网,原标题:代码详解:TensorFlow Core带你探索深度神经网络“黑匣子” 想学TensorFlow?先从低阶API开始吧~某种程度而言,它能够帮助我们更好地理解Tensorflo ...
- [重磅]Deep Forest,非神经网络的深度模型,周志华老师最新之作,三十分钟理解!
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 深度学习最大的贡献,个人认为就是表征 ...
- 从TensorFlow 到 Caffe2:盘点深度学习框架
机器之心报道 本文首先介绍GitHub中最受欢迎的开源深度学习框架排名,然后再对其进行系统地对比 下图总结了在GitHub中最受欢迎的开源深度学习框架排名,该排名是基于各大框架在GitHub里的收藏数 ...
- NNs(Neural Networks,神经网络)和Polynomial Regression(多项式回归)等价性之思考,以及深度模型可解释性原理研究与案例
1. Main Point 0x1:行文框架 第二章:我们会分别介绍NNs神经网络和PR多项式回归各自的定义和应用场景. 第三章:讨论NNs和PR在数学公式上的等价性,NNs和PR是两个等价的理论方法 ...
- NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码)
NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码) 七月,酷暑难耐,认识的几位同学参加知乎看山杯,均取得不错的排名.当时天池AI医疗大赛初赛结束,官方正在为复赛进行平台调 ...
- 三分钟快速上手TensorFlow 2.0 (下)——模型的部署 、大规模训练、加速
前文:三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署 TensorFlow 模型导出 使用 SavedModel 完整导出模型 不仅包含参数的权值,还包含计算的流程(即计算 ...
- hadoop文本转换为序列文件
在以前使用hadoop的时候因为mahout里面很多都要求输入文件时序列文件,所以涉及到把文本文件转换为序列文件或者序列文件转为文本文件(因为当时要分析mahout的源码,所以就要看到它的输入文件是什 ...
随机推荐
- 一,PHP 语法
基本的 PHP 语法 PHP 的脚本块以 <?php 开始,以 ?> 结束.您可以把 PHP 的脚本块放置在文档中的任何位置. 当然,在支持简写的服务器上,您可以使用 <? 和 ?& ...
- include file和include virtual的区别
1.#include file 包含文件的相对路径,#include virtual包含文件的虚拟路径. 2.在同一个虚拟目录内,<!--#include file="file.asp ...
- java.lang.VerifyError: Inconsistent stackmap frames at branch target
-XX:-UseSplitVerifier解决. 附带网址:http://stackoverflow.com/questions/12774672/java-7-inconsistent-stackm ...
- C#使用系统的“显示桌面”功能(Shell.Application)
原文 C#使用系统的“显示桌面”功能(Shell.Application) 在 Windows 系统的 任务栏 上的 快速启动栏 里,通常有一个图标 ,点击这个图标,就会切换到桌面.这个图标实际是一 ...
- HDU 2227 Find the nondecreasing subsequences
题目大意:给定一个序列,求出其所有的上升子序列. 题解:一开始我以为是动态规划,后来发现离散后树状数组很好做,首先,c保存的是第i位上升子系列有几个,那么树状数组的sum就直接是现在的答案了,不过更新 ...
- HDU 1997 汉诺塔VII
题解参考博客: http://blog.csdn.net/hjd_love_zzt/article/details/9897281 #include <cstdio> ],yes; int ...
- HDU 2527
题目描述 HDU 2527 分析 霍夫曼编码的应用. 本题没有必要构造一棵完整的霍夫曼树.只需利用霍夫曼编码的原理,每次挑选频率最低的两个元素进行合并 ...
- Android项目导入时,出现的Could not write file 。。。。。。.classpath错误解决办法
导入到Eclipse中后选择了相应的API后,红叉的项目错误没有了. 工程列表也无任何错误了.但出现了这样的提示框错误 说明的是.classpath这个环境文件不能写.随后,查看工程文件主目录下的.c ...
- LNMP一键安装结果
============================== Check install ============================== Checking ... Nginx: OK M ...
- web测试 结果存储类型为“Database”,但尚未指定结果储存库连接字符串
vs2010 Ultimate版带有web测试功能,可以对网站的性能以及负载进行测试. 在进行负载测试时提示“异常 LoadTestConnectStringMissingException 1 Lo ...