Hive集成HBase详解

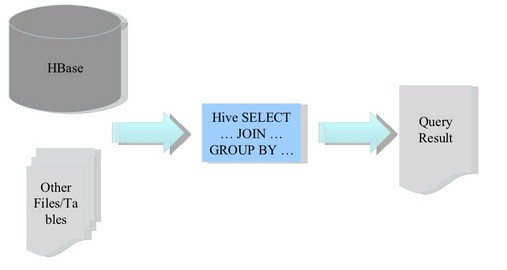
- 使用HQL语句创建一个指向HBase的Hive表
CREATE TABLE hbase_table_1(key int, value string) //Hive中的表名hbase_table_1
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' //指定存储处理器
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") //声明列族,列名
TBLPROPERTIES ("hbase.table.name" = "xyz", "hbase.mapred.output.outputtable" = "xyz");
//hbase.table.name声明HBase表名,为可选属性默认与Hive的表名相同,
//hbase.mapred.output.outputtable指定插入数据时写入的表,如果以后需要往该表插入数据就需要指定该值
- 通过HBase shell可以查看刚刚创建的HBase表的属性
$ hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Version: 0.20.3, r902334, Mon Jan 25 13:13:08 PST 2010
hbase(main):001:0> list
xyz
1 row(s) in 0.0530 seconds
hbase(main):002:0> describe "xyz"
DESCRIPTION ENABLED
{NAME => 'xyz', FAMILIES => [{NAME => 'cf1', COMPRESSION => 'NONE', VE true
RSIONS => '3', TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY =>
'false', BLOCKCACHE => 'true'}]}
1 row(s) in 0.0220 seconds
hbase(main):003:0> scan "xyz"
ROW COLUMN+CELL
0 row(s) in 0.0060 seconds
- 使用HQL向HBase表中插入数据
INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes WHERE foo=98;
- 在HBase端查看插入的数据
hbase(main):009:0> scan "xyz"
ROW COLUMN+CELL
98 column=cf1:val, timestamp=1267737987733, value=val_98
1 row(s) in 0.0110 seconds
- 创建一个指向已经存在的HBase表的Hive表
CREATE EXTERNAL TABLE hbase_table_2(key int, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = "cf1:val")
TBLPROPERTIES("hbase.table.name" = "some_existing_table", "hbase.mapred.output.outputtable" = "some_existing_table");
- 建表或映射表的时候如果没有指定:key则第一个列默认就是行键
- HBase对应的Hive表中没有时间戳概念,默认返回的就是最新版本的值
- 由于HBase中没有数据类型信息,所以在存储数据的时候都转化为String类型
CREATE TABLE hbase_table_1(key int, value1 string, value2 int, value3 int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,a:b,a:c,d:e"
);
INSERT OVERWRITE TABLE hbase_table_1 SELECT foo, bar, foo+1, foo+2
FROM pokes WHERE foo=98 OR foo=100;
CREATE TABLE hbase_table_1(value map<string,int>, row_key int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = "cf:,:key"
);
INSERT OVERWRITE TABLE hbase_table_1 SELECT map(bar, foo), foo FROM pokes
WHERE foo=98 OR foo=100;
- 在HBase下查看数据
hbase(main):012:0> scan "hbase_table_1"
ROW COLUMN+CELL
100 column=cf:val_100, timestamp=1267739509194, value=100
98 column=cf:val_98, timestamp=1267739509194, value=98
2 row(s) in 0.0080 seconds
- 在Hive下查看数据
hive> select * from hbase_table_1;
Total MapReduce jobs = 1
Launching Job 1 out of 1
...
OK
{"val_100":100} 100
{"val_98":98} 98
Time taken: 3.808 seconds
CREATE TABLE hbase_table_1(key int, value map<int,int>)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,cf:"
);
CREATE TABLE hbase_table_1(key int, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,cf:"
);
CREATE EXTERNAL TABLE delimited_example(key struct<f1:string, f2:string>, value string)
ROW FORMAT DELIMITED
COLLECTION ITEMS TERMINATED BY '~'
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
'hbase.columns.mapping'=':key,f:c1');
- 对HBase表进行预分区,增大其MapReduce作业的并行度
- 合理的设计rowkey使其尽可能的分布在预先分区好的Region上
- 通过set hbase.client.scanner.caching设置合理的扫描缓存
参考资料:
Hive集成HBase详解的更多相关文章
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- Hive集成HBase;安装pig
Hive集成HBase 配置 将hive的lib/中的HBase.jar包用实际安装的Hbase的jar包替换掉 cd /opt/hive/lib/ ls hbase-0.94.2* rm -rf ...
- [转帖]HBase详解(很全面)
HBase详解(很全面) very long story 简单看了一遍 很多不明白的地方.. 2018-06-08 16:12:32 卢子墨 阅读数 34857更多 分类专栏: HBase [转自 ...
- 安卓集成发布详解(二)gradle
转自:http://frank-zhu.github.io/android/2015/06/15/android-release_app_build_gradle/ 安卓集成发布详解(二) 15 Ju ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- 最佳实战Docker持续集成图文详解
最佳实战Docker持续集成图文详解 这是一种真正的容器级的实现,这个带来的好处,不仅仅是效率的提升,更是一种变革:开发人员第一次真正为自己的代码负责——终于可以跳过运维和测试部门,自主维护运行环境( ...
- Hive的配置详解和日常维护
Hive的配置详解和日常维护 一.Hive的参数配置详解 1>.mapred.reduce.tasks 默认为-1.指定Hive作业的reduce task个数,如果保留默认值,则Hive 自 ...
随机推荐
- 在Centos 5.6下安装 redis
先引用redis官方(http://redis.io/) 的介绍: Redis is an open source, advanced key-value store.<br>It is ...
- javascript中的原型理解总结
经过几天研究查找资料,对原型终于有点理解了,今天就做下总结,不对之处,希望各位能够提出. 1.每一个Javascript对象(null除外)都和另一个对象相关联,“另一个”对象就是我们今天所要总结的原 ...
- http发送post请求
package com.j1.soa.resource.member.oracle.service; import java.io.BufferedReader; import java.io.IOE ...
- openfire spark 二次 开发 服务插件
==================== 废话 begin ============================ 最近老大让我为研发平台增加即时通讯功能.告诉我用comet 在web端实现即 ...
- git 笔记记录
分布式版本控制系统Git 是一套内容寻址文件系统,从核心上来看不过是简单地存储键值对.一: git 本地clone 一个仓库 1. 直接clone一个仓库: $: git clon ...
- HC-05蓝牙模块基本使用
1.进入AT模式 EN输入高电平+按住按键不放,然后上电,进入AT模式,不过AT指令只能输入一次,下次再输入AT需要重新进入 2.串口波特率设为38400,进行AT模式下的指令操作 3.基本AT指令 ...
- jquery的鼠标移入移出事件hover、mouseenter、mouseleave、mouseover、mouseout
hover:鼠标进入元素的子元素时不会触发‘鼠标移开’的事件: mouseenter.mouseleave:效果与hover相同: mouseover: 鼠标进入元素和进入它的子元素时都会触发‘mou ...
- action找不到
错误: {"name":"Not Found","message":"Unable to resolve the request: ...
- C语言---return(我的工程笔记本)
迷惑了一天 函数就是输出有问题,进入函数设置密码的时候,当我保存密码准备返回,问题就在此时诞生了,界面是主界面,但功能函数还是没反应,设置序列号初始值的原来按键却还是有反应,莫名其妙,莫名其妙... ...
- iOS开发之常用第三方框架(下载地址,使用方法,总结)
iOS开发之常用第三方框架(下载地址,使用方法,总结) 说句实话,自学了这么久iOS,如果说我不知道的但是又基本上都摸遍了iOS相关知识,但是每次做项目的时候,遇到难一点的地方或者没试过的东西就闷了. ...