假期学习【十一】Python切词,以及从百度爬取词典
今天主要对从CSDN爬取的标题利用jieba(结巴)进行分词,但在分词过程中发现,如大数据被分成了大/数据,云计算被分隔成了云/计算。
后来又从百度百科---》信息领域爬取了相关词语作为词典,预计今天晚上完成切词任务。
其中分割代码如下:
import jieba
import io #对句子进行分词
def cut():
f=open("E://luntan.txt","r+",encoding="utf-8")
for line in f:
seg_list=jieba.cut(line)
#print(' '.join(seg_list))
for i in seg_list:
print(i)
write(i+" ")
#write(' '.join(seg_list)) #分词后写入
def write(contents):
f=open("E://luntan_cut.txt","a+",encoding="utf-8")
f.write(contents)
print("写入成功!")
f.close() #创建停用词
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords # 对句子进行去除停用词
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('E://stop.txt') # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr #循环去除
def cut_all():
inputs = open('E://luntan_cut.txt', 'r', encoding='utf-8')
outputs = open('E//luntan_stop', 'w')
for line in inputs:
line_seg = seg_sentence(line) # 这里的返回值是字符串
outputs.write(line_seg + '\n')
outputs.close()
inputs.close() if __name__=="__main__":
cut()
分割后的文本
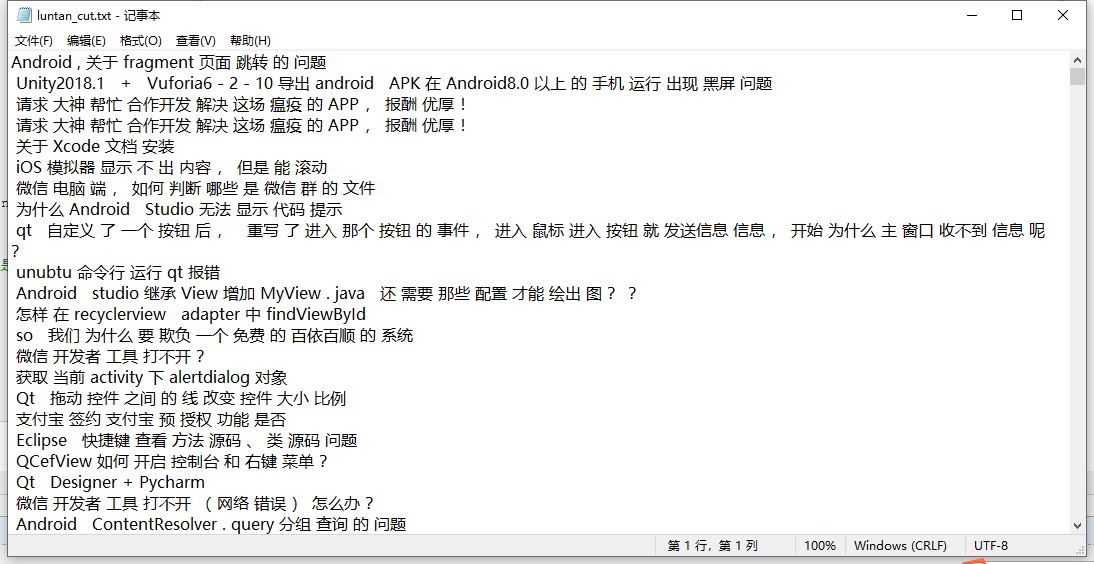
从百度爬取词典要把百度页面 地址:https://baike.baidu.com/wikitag/taglist?tagId=76607
该页拉到最下,并存为本地mhtml格式,在浏览器打开然后右击查看源代码,源代码保存为txt格式文件,
代码如下:
import io
import re patton=re.compile(r'title=".*"')
def read():
f=open("E://mhtml.txt","r+",encoding="utf-8")
for line in f:
line=line.rstrip("\n")
m=patton.findall(line)
#print(line)
if len(m)!=0:
print(m)
write(str(m).lstrip("['title=\"").rstrip("\"']")+"\r") def write(contents):
f=open("E://xinxi.txt","a+",encoding="utf-8")
f.write(contents)
print("写入成功!")
f.close() if __name__=="__main__":
read()
效果:
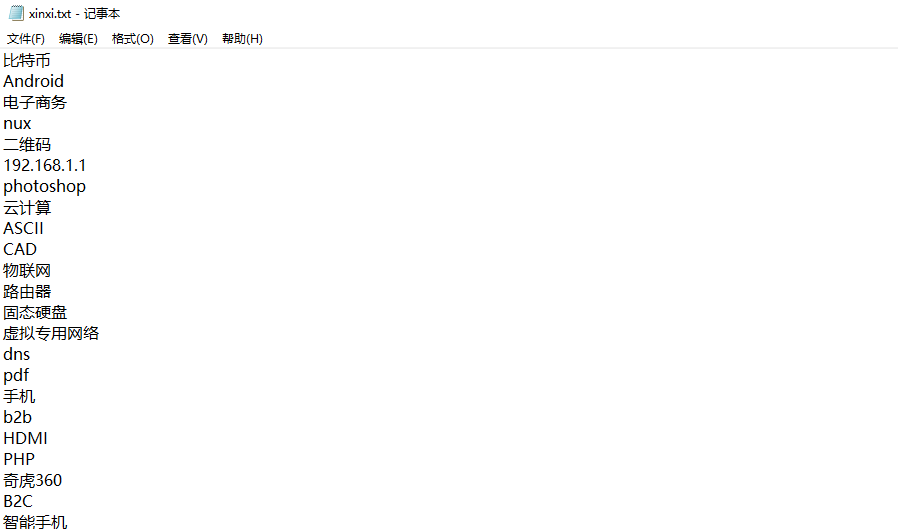
假期学习【十一】Python切词,以及从百度爬取词典的更多相关文章
- 【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
[学习笔记]Python 3.6模拟输入并爬取百度前10页密切相关链接 问题描述 通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接. me ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
随机推荐
- vue自带的实例属性和方法($打头)
Vue 实例内置了一些有用的实例属性与方法.它们都有前缀 $,以便与用户定义的属性区分开来.例如: var data = { a: 1 } var vm = new Vue({ el: '#examp ...
- 智和网管平台SugarNMS 2019年度IT综合监控突破性成果概览
一元复始,万象更新,欢辞旧岁,喜迎新年. 智和信通,精益求精,携手并进,迎战鼠年! 2020年1月10日,北京智和信通技术有限公司(以下简称“智和信通”)以“2020携手并进”为主题的年度庆典暨201 ...
- Leetcode:96. 不同的二叉搜索树
Leetcode:96. 不同的二叉搜索树 Leetcode:96. 不同的二叉搜索树 题目在链接中,点进去看看吧! 先介绍一个名词:卡特兰数 卡特兰数 卡特兰数Cn满足以下递推关系: \[ C_{n ...
- 搞定 ElasticSearch系列一 下载安装
一.安装jdk 二.安装ElasticSearch 1.ElasticSearch下载地址: 2: 配置ElasticSearch 3:启动ElasticSearch 4: 安装ElasticSear ...
- java设计模式学习笔记——里氏替换原则
oo中的继承性的思考和说明 1.继承包含这样一层含义:父类中凡是已经实现好的方法,实际上是在设定规范和契约,虽然它不强制要求所有的子类必须遵循这些七月,但是如果子类对这些已经实现的方法任意修改,就会对 ...
- Chrome的插件扩展程序安装目录
地址栏输入chrome:version回车 个人资料路径下的Extensions文件夹即默认的扩展安装路径
- python基础入门之一 —— 变量与运算符
1.标识符 由数字,字母,下划线组成 不能由数字开头 不能使用内置关键字 严格区分大小 2.数据类型 数值:int (整型) float(浮点型) 布尔型:True(真) False(假) str ( ...
- 1.Android网络编程-HTML介绍
1.HTML介绍 超文本标记语言(HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言. 在Eclipse下则可以使用自带的浏览器浏览html: 2.H ...
- Vue之计算属性Computed和属性监听Watch,Computed和Watch的区别
一. 计算属性(computed) 1.计算属性是为了模板中的表达式简洁,易维护,符合用于简单运算的设计初衷. 例如: <div id="app"> {{ myname ...
- Node.js文档-os
获取操作系统相关信息 引用 const os = require('os') os.cpus() 获取当前机器的CPU信息 console.log(os.cpus()) 打印结果: [ { model ...