Spark学习之路 (三)Spark之RDD[转]
RDD的概述
什么是RDD?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性
(1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
(5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
WordCount粗图解RDD
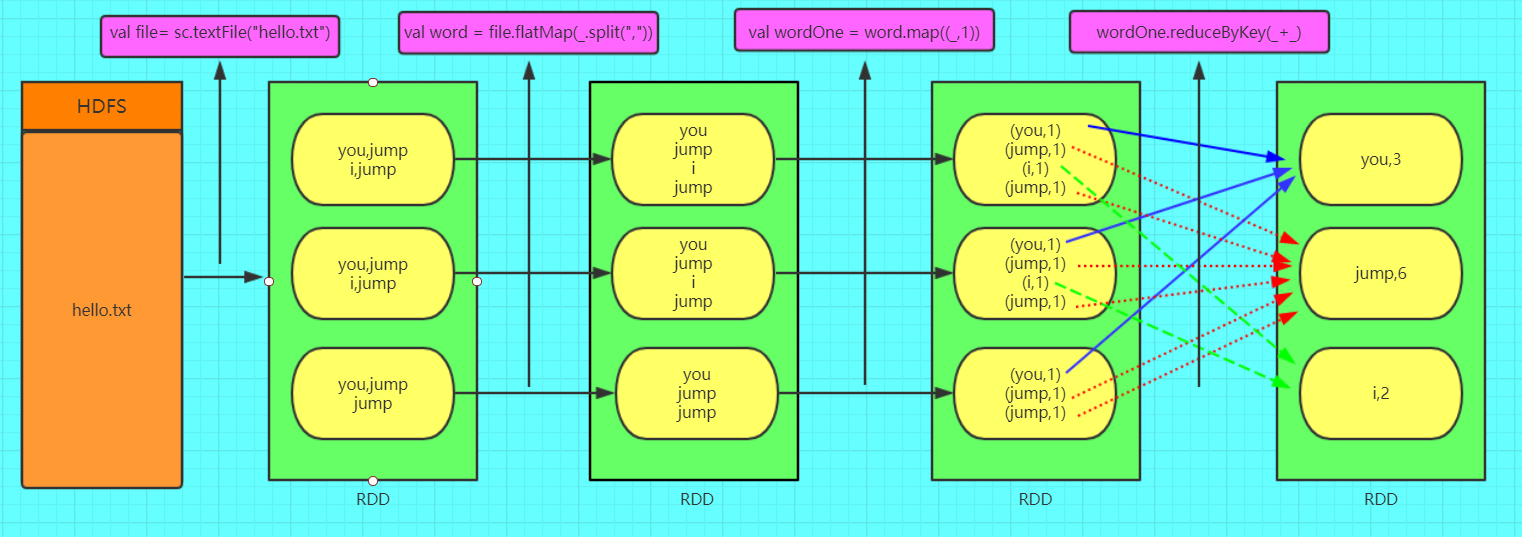
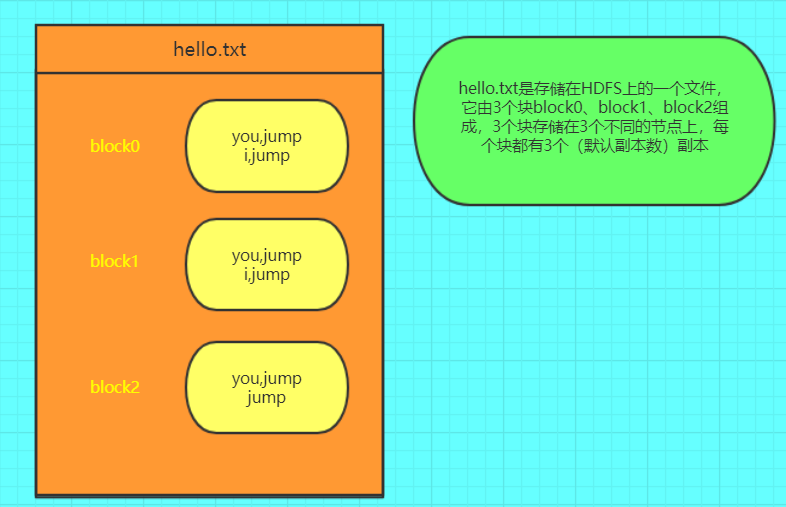
其中hello.txt
RDD的创建方式
通过读取文件生成的
由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
scala> val file = sc.textFile("/spark/hello.txt")
通过并行化的方式创建RDD
由一个已经存在的Scala集合创建。
scala> val array = Array(1,2,3,4,5)
array: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val rdd = sc.parallelize(array)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at parallelize at <console>:26
scala>
其他方式
读取数据库等等其他的操作。也可以生成RDD。
RDD可以通过其他的RDD转换而来的。
RDD编程API
Spark支持两个类型(算子)操作:Transformation和Action
Transformation
主要做的是就是将一个已有的RDD生成另外一个RDD。Transformation具有lazy特性(延迟加载)。Transformation算子的代码不会真正被执行。只有当我们的程序里面遇到一个action算子的时候,代码才会真正的被执行。这种设计让Spark更加有效率地运行。
常用的Transformation:
| 转换 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | 根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 先按分区聚合 再总的聚合 每次要跟初始值交流 例如:aggregateByKey(0)(+,+) 对k/y的RDD进行操作 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 第一个参数是根据什么排序 第二个是怎么排序 false倒序 第三个排序后分区数 默认与原RDD一样 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD 相当于内连接(求交集) |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD |
| cartesian(otherDataset) | 两个RDD的笛卡尔积 的成很多个K/V |
| pipe(command, [envVars]) | 调用外部程序 |
| coalesce(numPartitions) | 重新分区 第一个参数是要分多少区,第二个参数是否shuffle 默认false 少分区变多分区 true 多分区变少分区 false |
| repartition(numPartitions) | 重新分区 必须shuffle 参数是要分多少区 少变多 |
| repartitionAndSortWithinPartitions(partitioner) | 重新分区+排序 比先分区再排序效率高 对K/V的RDD进行操作 |
| foldByKey(zeroValue)(seqOp) | 该函数用于K/V做折叠,合并处理 ,与aggregate类似 第一个括号的参数应用于每个V值 第二括号函数是聚合例如:+ |
| combineByKey | 合并相同的key的值 rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) |
| partitionBy(partitioner) | 对RDD进行分区 partitioner是分区器 例如new HashPartition(2 |
| cache | RDD缓存,可以避免重复计算从而减少时间,区别:cache内部调用了persist算子,cache默认就一个缓存级别MEMORY-ONLY ,而persist则可以选择缓存级别 |
| persist | RDD缓存,可以避免重复计算从而减少时间,区别:cache内部调用了persist算子,cache默认就一个缓存级别MEMORY-ONLY ,而persist则可以选择缓存级别 |
| Subtract(rdd) | 返回前rdd元素不在后rdd的rdd |
| leftOuterJoin | leftOuterJoin类似于SQL中的左外关联left outer join,返回结果以前面的RDD为主,关联不上的记录为空。只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可。 |
| rightOuterJoin | rightOuterJoin类似于SQL中的有外关联right outer join,返回结果以参数中的RDD为主,关联不上的记录为空。只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可 |
| subtractByKey | substractByKey和基本转换操作中的subtract类似只不过这里是针对K的,返回在主RDD中出现,并且不在otherRDD中出现的元素 |
Action
触发代码的运行,我们一段spark代码里面至少需要有一个action操作。
常用的Action:
| 动作 | 含义 |
|---|---|
| reduce(func) | 通过func函数聚集RDD中的所有元素,这个功能必须是课交换且可并联的 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| takeSample(withReplacement,num, [seed]) | 返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
| takeOrdered(n, [ordering]) | |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) | |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) | 在数据集的每一个元素上,运行函数func进行更新。 |
| aggregate | 先对分区进行操作,在总体操作 |
| reduceByKeyLocally | |
| lookup | |
| top | |
| fold | |
| foreachPartition |
Spark WordCount代码编写
使用maven进行项目构建
(1)使用scala进行编写
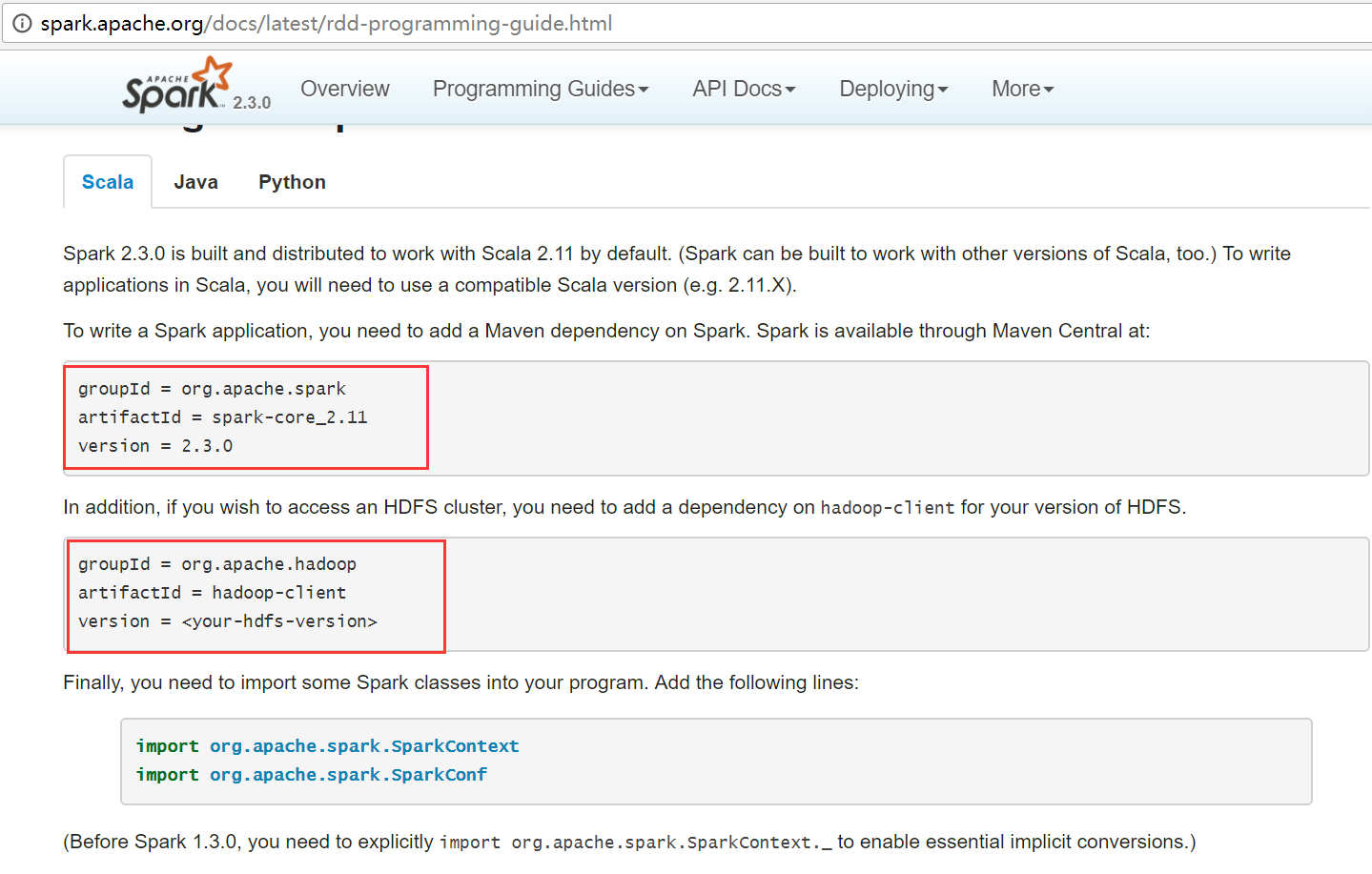
查看官方网站,需要导入2个依赖包
详细代码
SparkWordCountWithScala.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCountWithScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
/**
* 如果这个参数不设置,默认认为你运行的是集群模式
* 如果设置成local代表运行的是local模式
*/
conf.setMaster("local")
//设置任务名
conf.setAppName("WordCount")
//创建SparkCore的程序入口
val sc = new SparkContext(conf)
//读取文件 生成RDD
val file: RDD[String] = sc.textFile("E:\\hello.txt")
//把每一行数据按照,分割
val word: RDD[String] = file.flatMap(_.split(","))
//让每一个单词都出现一次
val wordOne: RDD[(String, Int)] = word.map((_,1))
//单词计数
val wordCount: RDD[(String, Int)] = wordOne.reduceByKey(_+_)
//按照单词出现的次数 降序排序
val sortRdd: RDD[(String, Int)] = wordCount.sortBy(tuple => tuple._2,false)
//将最终的结果进行保存
sortRdd.saveAsTextFile("E:\\result")
sc.stop()
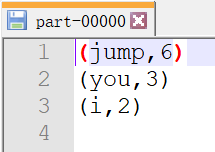
}运行结果
(2)使用java jdk7进行编写
SparkWordCountWithJava7.java
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class SparkWordCountWithJava7 {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("WordCount");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> fileRdd = sc.textFile("E:\\hello.txt");
JavaRDD<String> wordRDD = fileRdd.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(",")).iterator();
}
});
JavaPairRDD<String, Integer> wordOneRDD = wordRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<>(word, 1);
}
});
JavaPairRDD<String, Integer> wordCountRDD = wordOneRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
JavaPairRDD<Integer, String> count2WordRDD = wordCountRDD.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple) throws Exception {
return new Tuple2<>(tuple._2, tuple._1);
}
});
JavaPairRDD<Integer, String> sortRDD = count2WordRDD.sortByKey(false);
JavaPairRDD<String, Integer> resultRDD = sortRDD.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tuple) throws Exception {
return new Tuple2<>(tuple._2, tuple._1);
}
});
resultRDD.saveAsTextFile("E:\\result7");
}
}(3)使用java jdk8进行编写
lambda表达式
SparkWordCountWithJava8.java
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class SparkWordCountWithJava8 {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("WortCount");
conf.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> fileRDD = sc.textFile("E:\\hello.txt");
JavaRDD<String> wordRdd = fileRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
JavaPairRDD<String, Integer> wordOneRDD = wordRdd.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> wordCountRDD = wordOneRDD.reduceByKey((x, y) -> x + y);
JavaPairRDD<Integer, String> count2WordRDD = wordCountRDD.mapToPair(tuple -> new Tuple2<>(tuple._2, tuple._1));
JavaPairRDD<Integer, String> sortRDD = count2WordRDD.sortByKey(false);
JavaPairRDD<String, Integer> resultRDD = sortRDD.mapToPair(tuple -> new Tuple2<>(tuple._2, tuple._1));
resultRDD.saveAsTextFile("E:\\result8");
}WordCount执行过程图
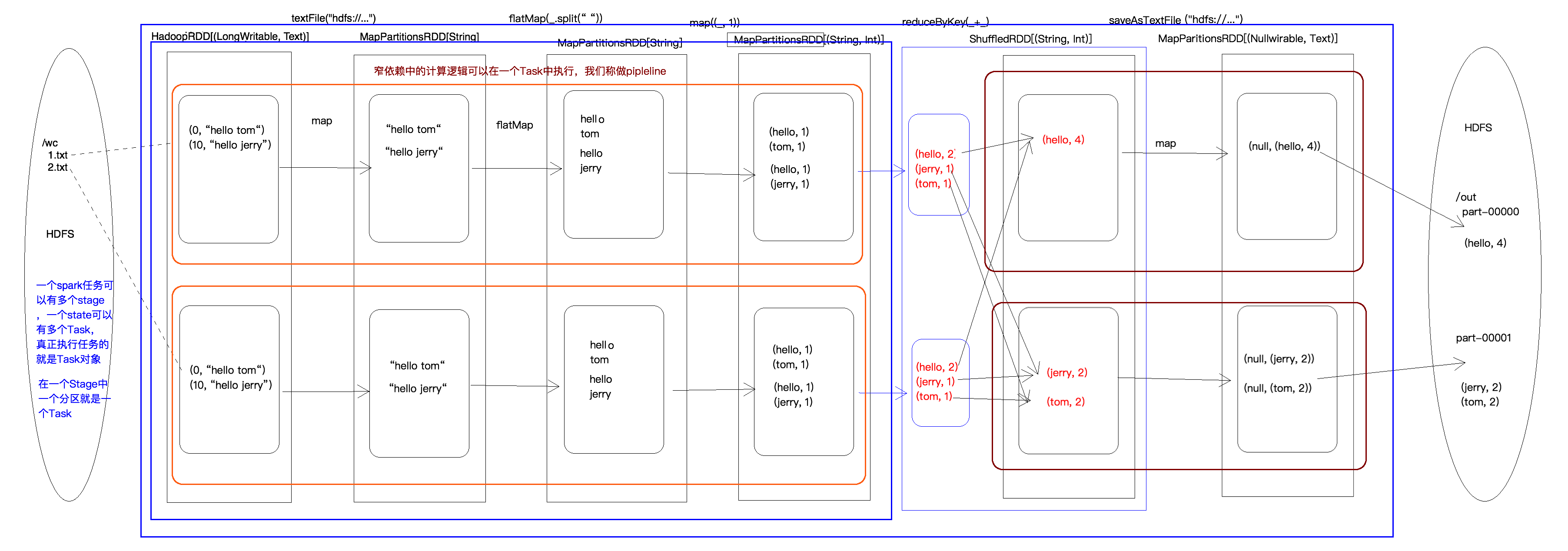
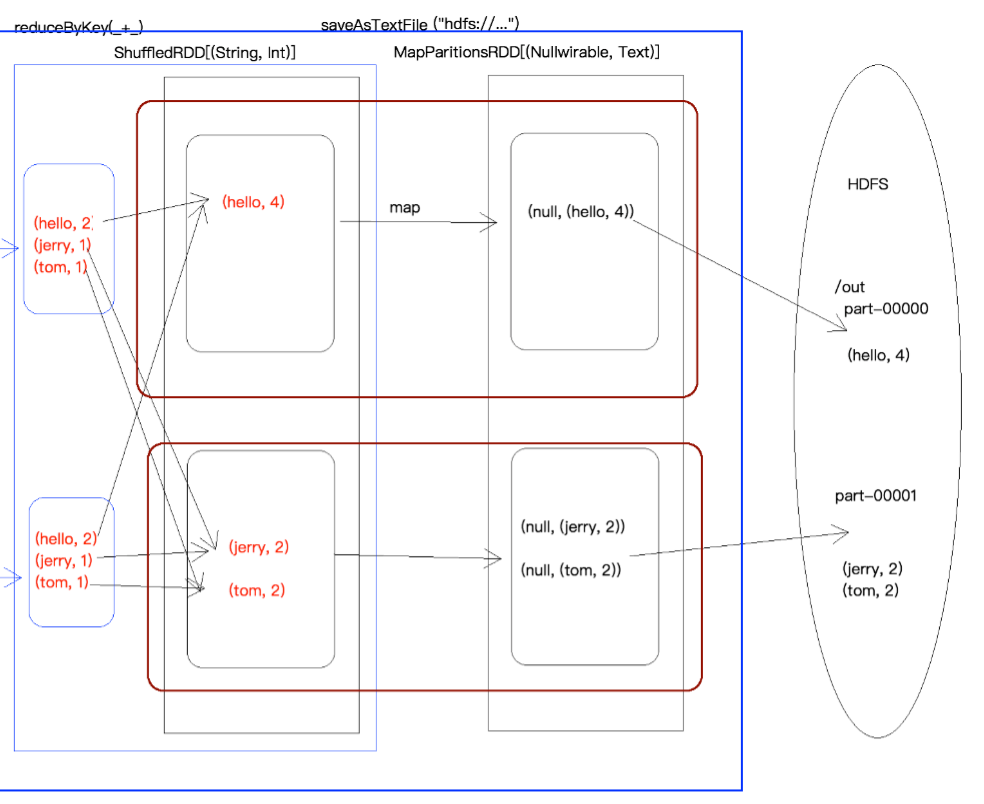
RDD的宽依赖和窄依赖
RDD依赖关系的本质内幕
由于RDD是粗粒度的操作数据集,每个Transformation操作都会生成一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系;RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。如图所示显示了RDD之间的依赖关系。
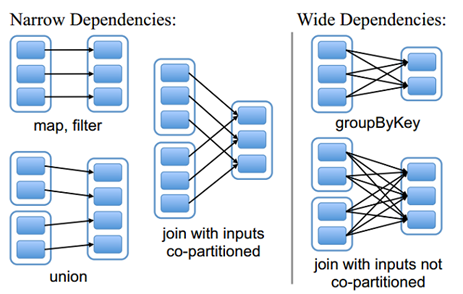
从图中可知:
窄依赖:是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;(独生子女)
宽依赖:是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;(超生)
需要特别说明的是对join操作有两种情况:
(1)图中左半部分join:如果两个RDD在进行join操作时,一个RDD的partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖,例如图1中左半部分的join操作(join with inputs co-partitioned);
(2)图中右半部分join:其它情况的join操作就是宽依赖,例如图1中右半部分的join操作(join with inputs not co-partitioned),由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。
总结:
在这里我们是从父RDD的partition被使用的个数来定义窄依赖和宽依赖,因此可以用一句话概括下:如果父RDD的一个Partition被子RDD的一个Partition所使用就是窄依赖,否则的话就是宽依赖。因为是确定的partition数量的依赖关系,所以RDD之间的依赖关系就是窄依赖;由此我们可以得出一个推论:即窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖。
一对固定个数的窄依赖的理解:即子RDD的partition对父RDD依赖的Partition的数量不会随着RDD数据规模的改变而改变;换句话说,无论是有100T的数据量还是1P的数据量,在窄依赖中,子RDD所依赖的父RDD的partition的个数是确定的,而宽依赖是shuffle级别的,数据量越大,那么子RDD所依赖的父RDD的个数就越多,从而子RDD所依赖的父RDD的partition的个数也会变得越来越多。
依赖关系下的数据流视图
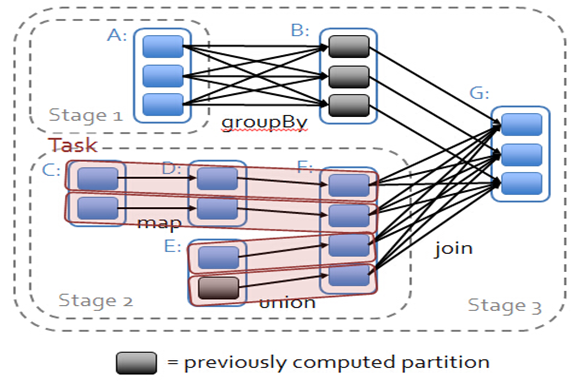
在spark中,会根据RDD之间的依赖关系将DAG图(有向无环图)划分为不同的阶段,对于窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,窄依赖就被spark划分到同一个stage中,而对于宽依赖,只能等父RDD shuffle处理完成后,下一个stage才能开始接下来的计算。
因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。因此在图2中RDD C,RDD D,RDD E,RDDF被构建在一个stage中,RDD A被构建在一个单独的Stage中,而RDD B和RDD G又被构建在同一个stage中。
在spark中,Task的类型分为2种:ShuffleMapTask和ResultTask;
简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中;也就是说上图中的stage1和stage2相当于mapreduce中的Mapper,而ResultTask所代表的stage3就相当于mapreduce中的reducer。
在之前动手操作了一个wordcount程序,因此可知,Hadoop中MapReduce操作中的Mapper和Reducer在spark中的基本等量算子是map和reduceByKey;不过区别在于:Hadoop中的MapReduce天生就是排序的;而reduceByKey只是根据Key进行reduce,但spark除了这两个算子还有其他的算子;因此从这个意义上来说,Spark比Hadoop的计算算子更为丰富。
Spark学习之路 (三)Spark之RDD[转]的更多相关文章
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- 学习之路三十九:新手学习 - Windows API
来到了新公司,一开始就要做个程序去获取另外一个程序里的数据,哇,挑战性很大. 经过两周的学习,终于搞定,主要还是对Windows API有了更多的了解. 文中所有的消息常量,API,结构体都整理出来了 ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark学习之路(三)—— 弹性式数据集RDDs
弹性式数据集RDDs 一.RDD简介 RDD全称为Resilient Distributed Datasets,是Spark最基本的数据抽象,它是只读的.分区记录的集合,支持并行操作,可以由外部数据集 ...
- Spark学习之路 (一)Spark初识
目录 一.官网介绍 1.什么是Spark 二.Spark的四大特性 1.高效性 2.易用性 3.通用性 4.兼容性 三.Spark的组成 四.应用场景 正文 回到顶部 一.官网介绍 1.什么是Spar ...
- Spark学习之路 (二十三)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark学习之路 (九)SparkCore的调优之数据倾斜调优
摘抄自:https://tech.meituan.com/spark-tuning-pro.html 数据倾斜调优 调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Sp ...
随机推荐
- 【算法总结】图论/dp-动态规划 大总结
写于一只蹲在角落的蒟蒻-Z__X... 2020.2.7,图论和 \(dp\) 终于告一段落.蓦然回首,好似已走过许多...不曾细细品味,太多太多又绵延不断地向我涌来... 谨以此纪念 逝去 的图论和 ...
- C++泛化动态数组
泛化动态数组 动态数组的核心思想是在存储数据时动态的管理数组元素占用的内存,通过调用动态数组的类方法来对数组中的数据进行增删改查操作.最初我们为数组申请10个元素的空间,放我们不断向数组中添加数据时, ...
- C#后台异步消息队列实现
简介 基于生产者消费者模式,我们可以开发出线程安全的异步消息队列. 知识储备 什么是生产者消费者模式? 为了方便理解,我们暂时将它理解为垃圾的产生到结束的过程. 简单来说,多住户产生垃圾(生产者)将垃 ...
- 多线程笔记 - provider-consumer
通过多线程实现一个简单的生产者-消费者案例(笔记). 首先定义一个要生产消费的数据类 : public class Data { private String id; private String n ...
- python学习------文件的读与写
f=open("yesterday","r",encoding="utf-8") #文件句柄 data=f.read() data2=f.r ...
- Webpack实战(七):简单搞懂PostCSS的用法及与一些插件的用法
不知不觉地春节要来临了,今天已经是放假的第二天,想想回老家之后所有的时间就不是自己的了,要陪孩子玩,走亲戚等等,我还是趁着在郑州的这两天,把几天后春节要发布的文章给提前整整.在此,提前祝大家春节快乐! ...
- Android 有关在ListView RecycleView 中使用EditText Checkbox的坑
这是一篇文字超多的博客,哈哈哈,废话自行过滤··· 遇到问题 在开发中我们常会在ListView , RecycleView 列表中添加EditText输入框,或者checkbox复选框. 复选框 ...
- powersploit的两个信息收集的脚本
0x00 简介 powersploit是基于powershell的渗透工具包,里面都是powershell的脚本工具文件.工具包地址:https://github.com/PowerShellMafi ...
- Android实战项目——家庭记账本(七)
今天主要实现了登录注册功能的客户端和服务端,但由于短信接口调用出现问题,导致注册功能还不完整. 截止到今天,APP的功能已经基本完成,后续还会陆陆续续的完善各功能模块与服务端的交互,因为需要和云端关联 ...
- MQ日常命令
假设队列管理器为QMgrName,以下所有使用QMgrName的地方您都可以替换成您维护的mq队列管理器名称. 一.MQ的启动与停止 用root用户启/停需要root用户包含在mqm组中. 1.MQ的 ...