forkjoin及其性能分析,是否比for循环快?
最近看了网上的某公开课,其中有讲到forkjoin框架。在这之前,我丝毫没听说过这个东西,很好奇是什么东东。于是,就顺道研究了一番。
总感觉这个东西,用的地方很少,也有可能是我才疏学浅。好吧,反正问了身边一堆猿,没有一个知道的。
因此,我也没有那么深入的去了解底层,只是大概的了解了其工作原理,并分析了下它和普通的for循环以及JDK8的stream流之间的性能对比(稍后会说明其中踩到的坑)。
一、forkjoin介绍
forkjoin是JDK7提供的并行执行任务的框架。 并行怎么理解呢,就是可以充分利用多核CPU的计算能力,让多个CPU同时进行任务的执行,从而使单位时间内执行的任务数尽量多,因此表现上就提高了执行效率。
它的主要思想就是,先把任务拆分成一个个小任务,然后再把所有任务汇总起来,简而言之就是分而治之。如果你了解过hadoop的MapReduce,就能理解这种思想了。不了解也没关系,下面画一张图,你就能明白了。
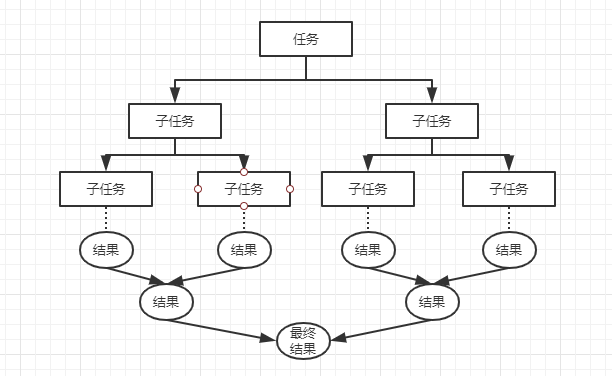
上边的任务拆分为多个子任务的过程就是fork,下边结果的归并操作就是join。(注意子任务和多线程不是一个概念,而是一个线程下会有多个子任务)
另外,forkjoin有一个工作窃取的概念。简单理解,就是一个工作线程下会维护一个包含多个子任务的双端队列。而对于每个工作线程来说,会从头部到尾部依次执行任务。这时,总会有一些线程执行的速度较快,很快就把所有任务消耗完了。那这个时候怎么办呢,总不能空等着吧,多浪费资源啊。
于是,先做完任务的工作线程会从其他未完成任务的线程尾部依次获取任务去执行。这样就可以充分利用CPU的资源。这个非常好理解,就比如有个妹子程序员做任务比较慢,那么其他猿就可以帮她分担一些任务,这简直是双赢的局面啊,妹子开心了,你也开心了。
二、实操测试性能
话不多说,先上代码,计算的是从0加到10亿的结果。
public class ForkJoinWork extends RecursiveTask<Long> {
private long start;
private long end;
//临界点
private static final long THRESHOLD = 1_0000L;
public ForkJoinWork(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long len = end - start;
//不大于临界值直接计算结果
if(len < THRESHOLD){
long sum = 0L;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
}else{
//大于临界值时,拆分为两个子任务
Long mid = (start + end) /2;
ForkJoinWork task1 = new ForkJoinWork(start,mid);
ForkJoinWork task2 = new ForkJoinWork(mid+1,end);
task1.fork();
task2.fork();
//合并计算
return task1.join() + task2.join();
}
}
}
public class ForkJoinTest {
public static void main(String[] args) throws Exception{
long start = 0L;
long end = 10_0000_0000L;
testSum(start,end);
testForkJoin(start,end);
testStream(start,end);
}
/**
* 普通for循环 - 1273ms
* @param start
* @param end
*/
public static void testSum(Long start,Long end){
long l = System.currentTimeMillis();
long sum = 0L;
for (long i = start; i <= end ; i++) {
sum += i;
}
long l1 = System.currentTimeMillis();
System.out.println("普通for循环结果:"+sum+",耗时:"+(l1-l));
}
/**
* forkjoin方式 - 917ms
* @param start
* @param end
* @throws Exception
*/
public static void testForkJoin(long start,long end) throws Exception{
long l = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinWork task = new ForkJoinWork(start,end);
long invoke = forkJoinPool.invoke(task);
long l1 = System.currentTimeMillis();
System.out.println("forkjoin结果:"+invoke+",耗时:"+(l1-l));
}
/**
* stream流 - 676ms
* @param start
* @param end
*/
public static void testStream(Long start,Long end){
long l = System.currentTimeMillis();
long reduce = LongStream.rangeClosed(start, end).parallel().reduce(0, (x, y) -> x + y);
long l1 = System.currentTimeMillis();
System.out.println("stream流结果:"+reduce+",耗时:"+(l1-l));
}
}
这里解释下,首先我们需要创建一个ForkJoinTask,自定义一个类来继承ForkJoinTask的子类RecursiveTask,这是为了拿到返回值。另外还有一个子类RecursiveAction是不带返回值的,这里我们暂时用不到。
然后,需要创建一个ForkJoinPool来执行task,最后调用invoke方法来获取最终执行的结果。它还有两种执行方式,execute和submit。这里不展开,感兴趣的可以自行查看源码。
铛铛,重点来了。
我测试了下比较传统的普通for循环,来对比forkjoin的执行速度。计算的是从0加到10亿,在我的win7电脑上确实是forkjoin计算速度快。这时,坑来了,同样的代码,没有任何改动,我搬到mac电脑上,计算结果却大大超出我的意外——forkjoin竟然比for循环慢了一倍,对的没错,执行时间是for循环的二倍。
这就让我特别头大了,这到底是什么原因呢。经过多次测试,终于搞明白了。forkjoin这个框架针对的是大任务执行,效率才会明显的看出来有提升,于是我把总数调大到20亿。
另外还有个关键点,通过设置不同的临界点值,会有不同的结果。逐渐的加大临界点值,效率会进一步提升。比如,我分别把THRESHOLD设置为1万,10万和100万,执行时间会逐步缩短,并且会比for循环时间短。感兴趣的,可自己手动操作一下,感受这个微妙的变化。
因此,最终修改为从0加到20亿,临界值设置为100万,就出现了以下结果:
普通for循环结果:2000000001000000000,耗时:1273
forkjoin结果:2000000001000000000,耗时:917
stream流结果:2000000001000000000,耗时:676
可以明显看出来,forkjoin确实是比for循环快的。当然,逐步的再加大总数到100亿或者更大,然后调整合适的临界值,这种对比会更加明显。(就是心疼电脑会冒烟,不敢这样测试)
最后,说下JDK8提供的Stream流计算,可以看到,这个计算速度是三种方式中最快的。奈你forkjoin再牛逼,通常还是比不过Stream的,从这个方法parallel的名字就看出来,也是并行计算。所以,这也是我感觉forkjoin好像没什么存在感的原因,Stream不香吗。(当然,也有可能是forkjoin还有更牛逼的功能待我去发掘。)
forkjoin及其性能分析,是否比for循环快?的更多相关文章
- Java 性能分析工具 , 第 1 部分: 操作系统工具
引言 性能分析的前提是将应用程序内部的运行状况以及应用运行环境的状况以一种可视化的方式更加直接的展现出来,如何来达到这种可视化的展示呢?我们需要配合使用操作系统中集成的程序监控工具和 Java 中内置 ...
- 性能分析工具-PerfView
Roslyn的PM(程序经理) Bill Chiles,Roslyn使用纯托管代码开发,但性能超过之前使用C++编写的原生实现,这有什么秘诀呢?他最近写了一篇文章叫做<Essential Per ...
- Android性能分析之TraceView的使用
TraceView简介 TraceView是AndroidSDK里面自带的工具,用于对Android的应用程序以及Framework层的代码进行性能分析. TraceView是图形化的工具,最终它会产 ...
- Linux性能分析工具的安装和使用
转自:http://blog.chinaunix.net/uid-26488891-id-3118279.html Normal 0 7.8 磅 0 2 false false false EN-US ...
- JS几种数组遍历方式以及性能分析对比
前言 这一篇与上一篇 JS几种变量交换方式以及性能分析对比 属于同一个系列,本文继续分析JS中几种常用的数组遍历方式以及各自的性能对比 起由 在上一次分析了JS几种常用变量交换方式以及各自性能后,觉得 ...
- OProfile 性能分析工具
OProfile 性能分析工具 官方网站:http://oprofile.sourceforge.net/news/ oprofile.ko模块本文主要介绍Oprofile工具,适用系统的CPU性能分 ...
- 高性能Linux服务器 第10章 基于Linux服务器的性能分析与优化
高性能Linux服务器 第10章 基于Linux服务器的性能分析与优化 作为一名Linux系统管理员,最主要的工作是优化系统配置,使应用在系统上以最优的状态运行.但硬件问题.软件问题.网络环境等 ...
- SQL查询性能分析
http://blog.csdn.net/dba_huangzj/article/details/8300784 SQL查询性能的好坏直接影响到整个数据库的价值,对此,必须郑重对待. SQL Serv ...
- PHP 性能分析与实验(二)——PHP 性能的微观分析
[编者按]此前,阅读过了很多关于 PHP 性能分析的文章,不过写的都是一条一条的规则,而且,这些规则并没有上下文,也没有明确的实验来体现出这些规则的优势,同时讨论的也侧重于一些语法要点.本文就改变 P ...
随机推荐
- nano使用说明
Main nano help text The nano editor is designed to emulate 仿真.模拟 the functionality and ease-of-use o ...
- 漏洞: RHSA-2017:3075: wget security update
该网址有解决方案 http://www.stumblingblock.cn/3102.html
- springboot+thymeleaf 纯后台渲染偷懒版分页
分页的样式就是这样的 cotroller这里这么写,传给view总页数,现在的页数,下一页,上一页的信息 private String homeInfo(Model model) { Page< ...
- java声明异常(throws)
在可能出现异常的方法上声明抛出可能出现异常的类型: 声明的时候尽可能声明具体的异常,方便更好的处理. 当前方法不知道如何处理这种异常,可将该异常交给上一级调用者来处理(非RuntimeExceptio ...
- springboot2.0.2+redis+spring-session 解决session共享的问题
准备工作 新建两个springboot2.0.2版本的服务,配置文件添加: #在默认设置下,Eureka服务注册中心也会将自己作为客户端来尝试注册它自己,所以我们需要禁用它的客户端注册行为 eurek ...
- H3C 子网划分方法
- SpringBoot 上传文件到linux服务器 异常java.io.FileNotFoundException: /tmp/tomcat.50898……解决方案
SpringBoot 上传文件到linux服务器报错java.io.FileNotFoundException: /tmp/tomcat.50898-- 报错原因: 解决方法 java.io.IOEx ...
- PHP性能监控
使用xhprof进行线上PHP性能追踪及分析 日志未经声明,均为AlloVince原创.版权采用『 知识共享署名-非商业性使用 2.5 许可协议』进行许可. 之前一直使用基于Xdebug进行PHP的性 ...
- jquery ajax请求步骤
$.ajax({ type: "GET", url: "/alink-hq/checkCode", data: { "mobile": ph ...
- 【Repo】repo sync:error.GitError: cannot initialize work tree
1.Error Fetching projects: 100% (725/725), done. Checking out files: 100% (4605/4605), done.out file ...