Spark学习之路 (六)Spark Transformation和Action[转]
Transformation算子
基本的初始化
(1)java
static SparkConf conf = null;
static JavaSparkContext sc = null;
static {
conf = new SparkConf();
conf.setMaster("local").setAppName("TestTransformation");
sc = new JavaSparkContext(conf);
}(2)scala
private val conf: SparkConf = new SparkConf().setAppName("TestTransformation").setMaster("local")
private val sparkContext = new SparkContext(conf)map、flatMap、mapParations、mapPartitionsWithIndex
map
jdk7
map十分容易理解,他是将源JavaRDD的一个一个元素的传入call方法,并经过算法后一个一个的返回从而生成一个新的JavaRDD。
public static void map(){
//String[] names = {"张无忌","赵敏","周芷若"};
List<String> list = Arrays.asList("张无忌","赵敏","周芷若");
System.out.println(list.size());
JavaRDD<String> listRDD = sc.parallelize(list);
JavaRDD<String> nameRDD = listRDD.map(new Function<String, String>() {
@Override
public String call(String name) throws Exception {
return "Hello " + name;
}
});
nameRDD.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});
}jdk8
public static void map(){
String[] names = {"张无忌","赵敏","周芷若"};
List<String> list = Arrays.asList(names);
JavaRDD<String> listRDD = sc.parallelize(list);
JavaRDD<String> nameRDD = listRDD.map(name -> {
return "Hello " + name;
});
nameRDD.foreach(name -> System.out.println(name));
}scala
def map(): Unit ={
val list = List("张无忌", "赵敏", "周芷若")
val listRDD = sc.parallelize(list)
val nameRDD = listRDD.map(name => "Hello " + name)
nameRDD.foreach(name => println(name))
}运行结果

总结
可以看出,对于map算子,源JavaRDD的每个元素都会进行计算,由于是依次进行传参,所以他是有序的,新RDD的元素顺序与源RDD是相同的。而由有序又引出接下来的
flatMap。
jdk7
flatMap与map一样,是将RDD中的元素依次的传入call方法,他比map多的功能是能在任何一个传入call方法的元素后面添加任意多元素,而能达到这一点,正是因为其进行传参是依次进行的。
public static void flatMap(){
List<String> list = Arrays.asList("张无忌 赵敏","宋青书 周芷若");
JavaRDD<String> listRDD = sc.parallelize(list);
JavaRDD<String> nameRDD = listRDD
.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
})
.map(new Function<String, String>() {
@Override
public String call(String name) throws Exception {
return "Hello " + name;
}
});
nameRDD.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});
}jdk8
public static void flatMap(){
List<String> list = Arrays.asList("张无忌 赵敏","宋青书 周芷若");
JavaRDD<String> listRDD = sc.parallelize(list);
JavaRDD<String> nameRDD = listRDD.flatMap(line -> Arrays.asList(line.split(" ")).iterator())
.map(name -> "Hello " + name);
nameRDD.foreach(name -> System.out.println(name));
}scala
def flatMap(): Unit ={
val list = List("张无忌 赵敏","宋青书 周芷若")
val listRDD = sc.parallelize(list)
val nameRDD = listRDD.flatMap(line => line.split(" ")).map(name => "Hello " + name)
nameRDD.foreach(name => println(name))
}运行结果

总结
flatMap的特性决定了这个算子在对需要随时增加元素的时候十分好用,比如在对源RDD查漏补缺时。
map和flatMap都是依次进行参数传递的,但有时候需要RDD中的两个元素进行相应操作时(例如:算存款所得时,下一个月所得的利息是要原本金加上上一个月所得的本金的),这两个算子便无法达到目的了,这是便需要mapPartitions算子,他传参的方式是将整个RDD传入,然后将一个迭代器传出生成一个新的RDD,由于整个RDD都传入了,所以便能完成前面说的业务。
mapPartitions
jdk7
/**
* map:
* 一条数据一条数据的处理(文件系统,数据库等等)
* mapPartitions:
* 一次获取的是一个分区的数据(hdfs)
* 正常情况下,mapPartitions 是一个高性能的算子
* 因为每次处理的是一个分区的数据,减少了去获取数据的次数。
*
* 但是如果我们的分区如果设置得不合理,有可能导致每个分区里面的数据量过大。
*/
public static void mapPartitions(){
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);
//参数二代表这个rdd里面有两个分区
JavaRDD<Integer> listRDD = sc.parallelize(list,2);
listRDD.mapPartitions(new FlatMapFunction<Iterator<Integer>, String>() {
@Override
public Iterator<String> call(Iterator<Integer> iterator) throws Exception {
ArrayList<String> array = new ArrayList<>();
while (iterator.hasNext()){
array.add("hello " + iterator.next());
}
return array.iterator();
}
}).foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});
}jdk8
public static void mapParations(){
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);
JavaRDD<Integer> listRDD = sc.parallelize(list, 2);
listRDD.mapPartitions(iterator -> {
ArrayList<String> array = new ArrayList<>();
while (iterator.hasNext()){
array.add("hello " + iterator.next());
}
return array.iterator();
}).foreach(name -> System.out.println(name));
}scala
def mapParations(): Unit ={
val list = List(1,2,3,4,5,6)
val listRDD = sc.parallelize(list,2)
listRDD.mapPartitions(iterator => {
val newList: ListBuffer[String] = ListBuffer()
while (iterator.hasNext){
newList.append("hello " + iterator.next())
}
newList.toIterator
}).foreach(name => println(name))
}运行结果
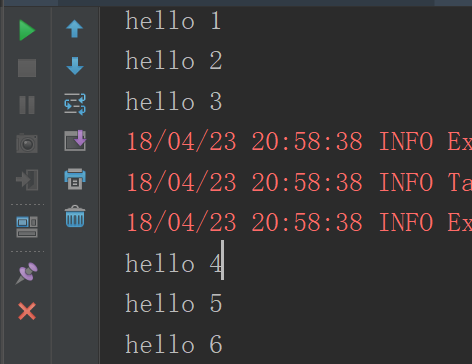
mapPartitionsWithIndex
每次获取和处理的就是一个分区的数据,并且知道处理的分区的分区号是啥?
jdk7
public static void mapPartitionsWithIndex(){
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8);
JavaRDD<Integer> listRDD = sc.parallelize(list, 2);
listRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<Integer>, Iterator<String>>() {
@Override
public Iterator<String> call(Integer index, Iterator<Integer> iterator) throws Exception {
ArrayList<String> list1 = new ArrayList<>();
while (iterator.hasNext()){
list1.add(index+"_"+iterator.next());
}
return list1.iterator();
}
},true)
.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});
}jdk8
public static void mapPartitionsWithIndex() {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8);
JavaRDD<Integer> listRDD = sc.parallelize(list, 2);
listRDD.mapPartitionsWithIndex((index,iterator) -> {
ArrayList<String> list1 = new ArrayList<>();
while (iterator.hasNext()){
list1.add(index+"_"+iterator.next());
}
return list1.iterator();
},true)
.foreach(str -> System.out.println(str));
}scala
def mapPartitionsWithIndex(): Unit ={
val list = List(1,2,3,4,5,6,7,8)
sc.parallelize(list).mapPartitionsWithIndex((index,iterator) => {
val listBuffer:ListBuffer[String] = new ListBuffer
while (iterator.hasNext){
listBuffer.append(index+"_"+iterator.next())
}
listBuffer.iterator
},true)
.foreach(println(_))
}运行结果
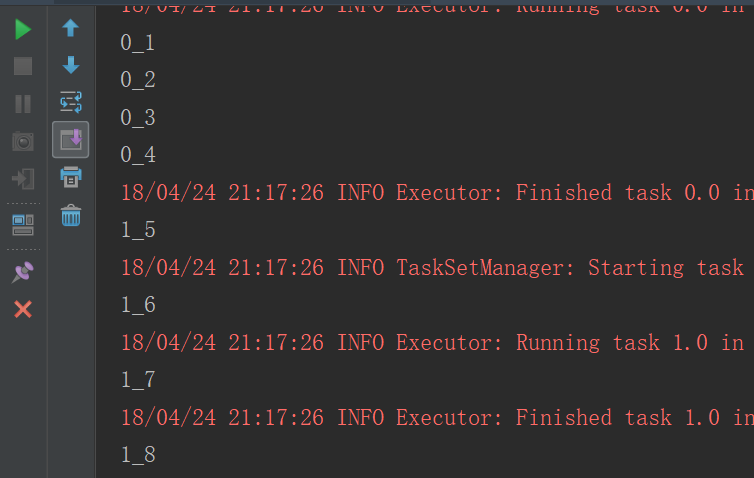
reduce、reduceByKey
reduce
reduce其实是讲RDD中的所有元素进行合并,当运行call方法时,会传入两个参数,在call方法中将两个参数合并后返回,而这个返回值回合一个新的RDD中的元素再次传入call方法中,继续合并,直到合并到只剩下一个元素时。
jdk7
public static void reduce(){
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);
JavaRDD<Integer> listRDD = sc.parallelize(list);
Integer result = listRDD.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
System.out.println(result);
}jdk8
public static void reduce(){
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);
JavaRDD<Integer> listRDD = sc.parallelize(list);
Integer result = listRDD.reduce((x, y) -> x + y);
System.out.println(result);
}scala
def reduce(): Unit ={
val list = List(1,2,3,4,5,6)
val listRDD = sc.parallelize(list)
val result = listRDD.reduce((x,y) => x+y)
println(result)
}运行结果
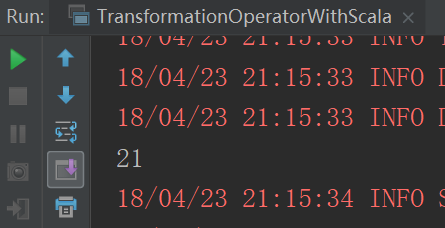
reduceByKey
reduceByKey仅将RDD中所有K,V对中K值相同的V进行合并。
jdk7
public static void reduceByKey(){
List<Tuple2<String, Integer>> list = Arrays.asList(
new Tuple2<String, Integer>("武当", 99),
new Tuple2<String, Integer>("少林", 97),
new Tuple2<String, Integer>("武当", 89),
new Tuple2<String, Integer>("少林", 77)
);
JavaPairRDD<String, Integer> listRDD = sc.parallelizePairs(list);
//运行reduceByKey时,会将key值相同的组合在一起做call方法中的操作
JavaPairRDD<String, Integer> result = listRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
result.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tuple) throws Exception {
System.out.println("门派: " + tuple._1 + "->" + tuple._2);
}
});
}jdk8
public static void reduceByKey(){
List<Tuple2<String, Integer>> list = Arrays.asList(
new Tuple2<String, Integer>("武当", 99),
new Tuple2<String, Integer>("少林", 97),
new Tuple2<String, Integer>("武当", 89),
new Tuple2<String, Integer>("少林", 77)
);
JavaPairRDD<String, Integer> listRDD = sc.parallelizePairs(list);
JavaPairRDD<String, Integer> resultRDD = listRDD.reduceByKey((x, y) -> x + y);
resultRDD.foreach(tuple -> System.out.println("门派: " + tuple._1 + "->" + tuple._2));
}scala
def reduceByKey(): Unit ={
val list = List(("武当", 99), ("少林", 97), ("武当", 89), ("少林", 77))
val mapRDD = sc.parallelize(list)
val resultRDD = mapRDD.reduceByKey(_+_)
resultRDD.foreach(tuple => println("门派: " + tuple._1 + "->" + tuple._2))
}运行结果
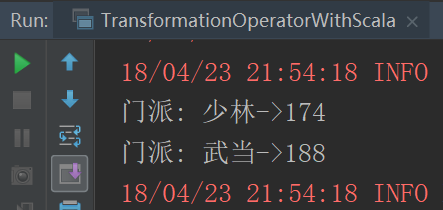
union,join和groupByKey
union
当要将两个RDD合并时,便要用到union和join,其中union只是简单的将两个RDD累加起来,可以看做List的addAll方法。就想List中一样,当使用union及join时,必须保证两个RDD的泛型是一致的。
jdk7
public static void union(){
final List<Integer> list1 = Arrays.asList(1, 2, 3, 4);
final List<Integer> list2 = Arrays.asList(3, 4, 5, 6);
final JavaRDD<Integer> rdd1 = sc.parallelize(list1);
final JavaRDD<Integer> rdd2 = sc.parallelize(list2);
rdd1.union(rdd2)
.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer number) throws Exception {
System.out.println(number + "");
}
});
}jdk8
public static void union(){
final List<Integer> list1 = Arrays.asList(1, 2, 3, 4);
final List<Integer> list2 = Arrays.asList(3, 4, 5, 6);
final JavaRDD<Integer> rdd1 = sc.parallelize(list1);
final JavaRDD<Integer> rdd2 = sc.parallelize(list2);
rdd1.union(rdd2).foreach(num -> System.out.println(num));
}scala
def union(): Unit ={
val list1 = List(1,2,3,4)
val list2 = List(3,4,5,6)
val rdd1 = sc.parallelize(list1)
val rdd2 = sc.parallelize(list2)
rdd1.union(rdd2).foreach(println(_))
}运行结果
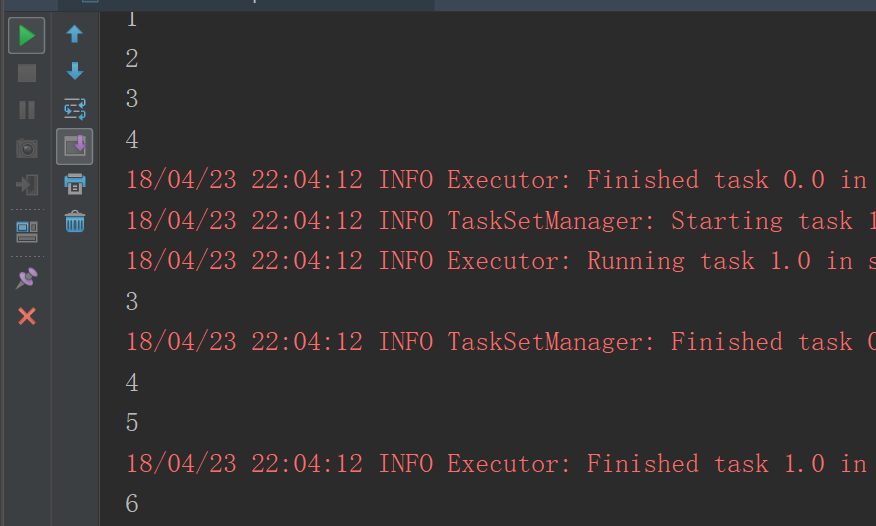
groupByKey
jdk7
union只是将两个RDD简单的累加在一起,而join则不一样,join类似于hadoop中的combin操作,只是少了排序这一段,再说join之前说说groupByKey,因为join可以理解为union与groupByKey的结合:groupBy是将RDD中的元素进行分组,组名是call方法中的返回值,而顾名思义groupByKey是将PairRDD中拥有相同key值得元素归为一组。即:
public static void groupByKey(){
List<Tuple2<String,String>> list = Arrays.asList(
new Tuple2("武当", "张三丰"),
new Tuple2("峨眉", "灭绝师太"),
new Tuple2("武当", "宋青书"),
new Tuple2("峨眉", "周芷若")
);
JavaPairRDD<String, String> listRDD = sc.parallelizePairs(list);
JavaPairRDD<String, Iterable<String>> groupByKeyRDD = listRDD.groupByKey();
groupByKeyRDD.foreach(new VoidFunction<Tuple2<String, Iterable<String>>>() {
@Override
public void call(Tuple2<String, Iterable<String>> tuple) throws Exception {
String menpai = tuple._1;
Iterator<String> iterator = tuple._2.iterator();
String people = "";
while (iterator.hasNext()){
people = people + iterator.next()+" ";
}
System.out.println("门派:"+menpai + "人员:"+people);
}
});
}jdk8
public static void groupByKey(){
List<Tuple2<String,String>> list = Arrays.asList(
new Tuple2("武当", "张三丰"),
new Tuple2("峨眉", "灭绝师太"),
new Tuple2("武当", "宋青书"),
new Tuple2("峨眉", "周芷若")
);
JavaPairRDD<String, String> listRDD = sc.parallelizePairs(list);
JavaPairRDD<String, Iterable<String>> groupByKeyRDD = listRDD.groupByKey();
groupByKeyRDD.foreach(tuple -> {
String menpai = tuple._1;
Iterator<String> iterator = tuple._2.iterator();
String people = "";
while (iterator.hasNext()){
people = people + iterator.next()+" ";
}
System.out.println("门派:"+menpai + "人员:"+people);
});
}scala
def groupByKey(): Unit ={
val list = List(("武当", "张三丰"), ("峨眉", "灭绝师太"), ("武当", "宋青书"), ("峨眉", "周芷若"))
val listRDD = sc.parallelize(list)
val groupByKeyRDD = listRDD.groupByKey()
groupByKeyRDD.foreach(t => {
val menpai = t._1
val iterator = t._2.iterator
var people = ""
while (iterator.hasNext) people = people + iterator.next + " "
println("门派:" + menpai + "人员:" + people)
})
}运行结果

join
jdk7
join是将两个PairRDD合并,并将有相同key的元素分为一组,可以理解为groupByKey和Union的结合
public static void join(){
final List<Tuple2<Integer, String>> names = Arrays.asList(
new Tuple2<Integer, String>(1, "东方不败"),
new Tuple2<Integer, String>(2, "令狐冲"),
new Tuple2<Integer, String>(3, "林平之")
);
final List<Tuple2<Integer, Integer>> scores = Arrays.asList(
new Tuple2<Integer, Integer>(1, 99),
new Tuple2<Integer, Integer>(2, 98),
new Tuple2<Integer, Integer>(3, 97)
);
final JavaPairRDD<Integer, String> nemesrdd = sc.parallelizePairs(names);
final JavaPairRDD<Integer, Integer> scoresrdd = sc.parallelizePairs(scores);
/**
* <Integer, 学号
* Tuple2<String, 名字
* Integer>> 分数
*/
final JavaPairRDD<Integer, Tuple2<String, Integer>> joinRDD = nemesrdd.join(scoresrdd);
// final JavaPairRDD<Integer, Tuple2<Integer, String>> join = scoresrdd.join(nemesrdd);
joinRDD.foreach(new VoidFunction<Tuple2<Integer, Tuple2<String, Integer>>>() {
@Override
public void call(Tuple2<Integer, Tuple2<String, Integer>> tuple) throws Exception {
System.out.println("学号:" + tuple._1 + " 名字:"+tuple._2._1 + " 分数:"+tuple._2._2);
}
});
}jdk8
public static void join(){
final List<Tuple2<Integer, String>> names = Arrays.asList(
new Tuple2<Integer, String>(1, "东方不败"),
new Tuple2<Integer, String>(2, "令狐冲"),
new Tuple2<Integer, String>(3, "林平之")
);
final List<Tuple2<Integer, Integer>> scores = Arrays.asList(
new Tuple2<Integer, Integer>(1, 99),
new Tuple2<Integer, Integer>(2, 98),
new Tuple2<Integer, Integer>(3, 97)
);
final JavaPairRDD<Integer, String> nemesrdd = sc.parallelizePairs(names);
final JavaPairRDD<Integer, Integer> scoresrdd = sc.parallelizePairs(scores);
final JavaPairRDD<Integer, Tuple2<String, Integer>> joinRDD = nemesrdd.join(scoresrdd);
joinRDD.foreach(tuple -> System.out.println("学号:"+tuple._1+" 姓名:"+tuple._2._1+" 成绩:"+tuple._2._2));
}scala
def join(): Unit = {
val list1 = List((1, "东方不败"), (2, "令狐冲"), (3, "林平之"))
val list2 = List((1, 99), (2, 98), (3, 97))
val list1RDD = sc.parallelize(list1)
val list2RDD = sc.parallelize(list2)
val joinRDD = list1RDD.join(list2RDD)
joinRDD.foreach(t => println("学号:" + t._1 + " 姓名:" + t._2._1 + " 成绩:" + t._2._2))
}运行结果
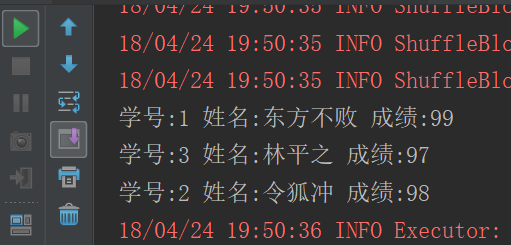
sample、cartesian
sample
jdk7
public static void sample(){
ArrayList<Integer> list = new ArrayList<>();
for(int i=1;i<=100;i++){
list.add(i);
}
JavaRDD<Integer> listRDD = sc.parallelize(list);
/**
* sample用来从RDD中抽取样本。他有三个参数
* withReplacement: Boolean,
* true: 有放回的抽样
* false: 无放回抽象
* fraction: Double:
* 抽取样本的比例
* seed: Long:
* 随机种子
*/
JavaRDD<Integer> sampleRDD = listRDD.sample(false, 0.1,0);
sampleRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer num) throws Exception {
System.out.print(num+" ");
}
});
}jdk8
public static void sample(){
ArrayList<Integer> list = new ArrayList<>();
for(int i=1;i<=100;i++){
list.add(i);
}
JavaRDD<Integer> listRDD = sc.parallelize(list);
JavaRDD<Integer> sampleRDD = listRDD.sample(false, 0.1, 0);
sampleRDD.foreach(num -> System.out.print(num + " "));
}scala
def sample(): Unit ={
val list = 1 to 100
val listRDD = sc.parallelize(list)
listRDD.sample(false,0.1,0).foreach(num => print(num + " "))
}运行结果
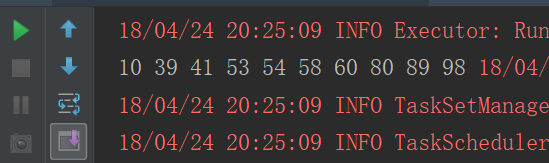
cartesian
cartesian是用于求笛卡尔积的
jdk7
public static void cartesian(){
List<String> list1 = Arrays.asList("A", "B");
List<Integer> list2 = Arrays.asList(1, 2, 3);
JavaRDD<String> list1RDD = sc.parallelize(list1);
JavaRDD<Integer> list2RDD = sc.parallelize(list2);
list1RDD.cartesian(list2RDD).foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tuple) throws Exception {
System.out.println(tuple._1 + "->" + tuple._2);
}
});
}jdk8
public static void cartesian(){
List<String> list1 = Arrays.asList("A", "B");
List<Integer> list2 = Arrays.asList(1, 2, 3);
JavaRDD<String> list1RDD = sc.parallelize(list1);
JavaRDD<Integer> list2RDD = sc.parallelize(list2);
list1RDD.cartesian(list2RDD).foreach(tuple -> System.out.print(tuple._1 + "->" + tuple._2));
}scala
def cartesian(): Unit ={
val list1 = List("A","B")
val list2 = List(1,2,3)
val list1RDD = sc.parallelize(list1)
val list2RDD = sc.parallelize(list2)
list1RDD.cartesian(list2RDD).foreach(t => println(t._1 +"->"+t._2))
}运行结果
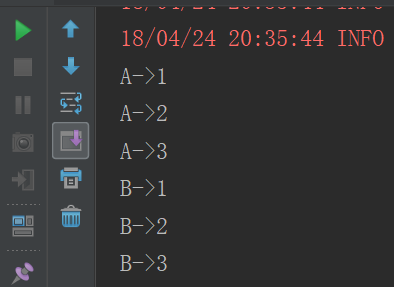
filter、distinct、intersection
filter
jdk7
过滤出偶数
public static void filter(){
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD<Integer> listRDD = sc.parallelize(list);
JavaRDD<Integer> filterRDD = listRDD.filter(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer num) throws Exception {
return num % 2 == 0;
}
});
filterRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer num) throws Exception {
System.out.print(num + " ");
}
});
}jdk8
public static void filter(){
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD<Integer> listRDD = sc.parallelize(list);
JavaRDD<Integer> filterRDD = listRDD.filter(num -> num % 2 ==0);
filterRDD.foreach(num -> System.out.print(num + " "));
}scala
def filter(): Unit ={
val list = List(1,2,3,4,5,6,7,8,9,10)
val listRDD = sc.parallelize(list)
listRDD.filter(num => num % 2 ==0).foreach(print(_))
}运行结果
distinct
jdk7
public static void distinct(){
List<Integer> list = Arrays.asList(1, 1, 2, 2, 3, 3, 4, 5);
JavaRDD<Integer> listRDD = (JavaRDD<Integer>) sc.parallelize(list);
JavaRDD<Integer> distinctRDD = listRDD.distinct();
distinctRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer num) throws Exception {
System.out.println(num);
}
});
}jdk8
public static void distinct(){
List<Integer> list = Arrays.asList(1, 1, 2, 2, 3, 3, 4, 5);
JavaRDD<Integer> listRDD = (JavaRDD<Integer>) sc.parallelize(list);
listRDD.distinct().foreach(num -> System.out.println(num));
}scala
def distinct(): Unit ={
val list = List(1,1,2,2,3,3,4,5)
sc.parallelize(list).distinct().foreach(println(_))
}运行结果
intersection
jdk7
public static void intersection(){
List<Integer> list1 = Arrays.asList(1, 2, 3, 4);
List<Integer> list2 = Arrays.asList(3, 4, 5, 6);
JavaRDD<Integer> list1RDD = sc.parallelize(list1);
JavaRDD<Integer> list2RDD = sc.parallelize(list2);
list1RDD.intersection(list2RDD).foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer num) throws Exception {
System.out.println(num);
}
});
}jdk8
public static void intersection() {
List<Integer> list1 = Arrays.asList(1, 2, 3, 4);
List<Integer> list2 = Arrays.asList(3, 4, 5, 6);
JavaRDD<Integer> list1RDD = sc.parallelize(list1);
JavaRDD<Integer> list2RDD = sc.parallelize(list2);
list1RDD.intersection(list2RDD).foreach(num ->System.out.println(num));
}scala
def intersection(): Unit ={
val list1 = List(1,2,3,4)
val list2 = List(3,4,5,6)
val list1RDD = sc.parallelize(list1)
val list2RDD = sc.parallelize(list2)
list1RDD.intersection(list2RDD).foreach(println(_))
}运行结果
coalesce、repartition、repartitionAndSortWithinPartitions
coalesce
分区数由多 -》 变少
jdk7
public static void coalesce(){
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
JavaRDD<Integer> listRDD = sc.parallelize(list, 3);
listRDD.coalesce(1).foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer num) throws Exception {
System.out.print(num);
}
});
}jdk8
public static void coalesce() {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
JavaRDD<Integer> listRDD = sc.parallelize(list, 3);
listRDD.coalesce(1).foreach(num -> System.out.println(num));
}scala
def coalesce(): Unit = {
val list = List(1,2,3,4,5,6,7,8,9)
sc.parallelize(list,3).coalesce(1).foreach(println(_))
}运行结果
replication
进行重分区,解决的问题:本来分区数少 -》 增加分区数
jdk7
public static void replication(){
List<Integer> list = Arrays.asList(1, 2, 3, 4);
JavaRDD<Integer> listRDD = sc.parallelize(list, 1);
listRDD.repartition(2).foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer num) throws Exception {
System.out.println(num);
}
});
}jdk8
public static void replication(){
List<Integer> list = Arrays.asList(1, 2, 3, 4);
JavaRDD<Integer> listRDD = sc.parallelize(list, 1);
listRDD.repartition(2).foreach(num -> System.out.println(num));
}scala
def replication(): Unit ={
val list = List(1,2,3,4)
val listRDD = sc.parallelize(list,1)
listRDD.repartition(2).foreach(println(_))
}运行结果
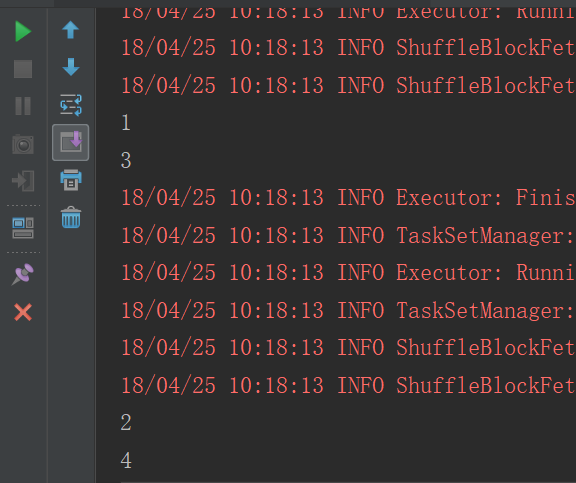
repartitionAndSortWithinPartitions
repartitionAndSortWithinPartitions函数是repartition函数的变种,与repartition函数不同的是,repartitionAndSortWithinPartitions在给定的partitioner内部进行排序,性能比repartition要高。
jdk7
public static void repartitionAndSortWithinPartitions(){
List<Integer> list = Arrays.asList(1, 3, 55, 77, 33, 5, 23);
JavaRDD<Integer> listRDD = sc.parallelize(list, 1);
JavaPairRDD<Integer, Integer> pairRDD = listRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer num) throws Exception {
return new Tuple2<>(num, num);
}
});
JavaPairRDD<Integer, Integer> parationRDD = pairRDD.repartitionAndSortWithinPartitions(new Partitioner() {
@Override
public int getPartition(Object key) {
Integer index = Integer.valueOf(key.toString());
if (index % 2 == 0) {
return 0;
} else {
return 1;
}
}
@Override
public int numPartitions() {
return 2;
}
});
parationRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<Tuple2<Integer, Integer>>, Iterator<String>>() {
@Override
public Iterator<String> call(Integer index, Iterator<Tuple2<Integer, Integer>> iterator) throws Exception {
final ArrayList<String> list1 = new ArrayList<>();
while (iterator.hasNext()){
list1.add(index+"_"+iterator.next());
}
return list1.iterator();
}
},false).foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});
}jdk8
public static void repartitionAndSortWithinPartitions(){
List<Integer> list = Arrays.asList(1, 4, 55, 66, 33, 48, 23);
JavaRDD<Integer> listRDD = sc.parallelize(list, 1);
JavaPairRDD<Integer, Integer> pairRDD = listRDD.mapToPair(num -> new Tuple2<>(num, num));
pairRDD.repartitionAndSortWithinPartitions(new HashPartitioner(2))
.mapPartitionsWithIndex((index,iterator) -> {
ArrayList<String> list1 = new ArrayList<>();
while (iterator.hasNext()){
list1.add(index+"_"+iterator.next());
}
return list1.iterator();
},false)
.foreach(str -> System.out.println(str));
}scala
def repartitionAndSortWithinPartitions(): Unit ={
val list = List(1, 4, 55, 66, 33, 48, 23)
val listRDD = sc.parallelize(list,1)
listRDD.map(num => (num,num))
.repartitionAndSortWithinPartitions(new HashPartitioner(2))
.mapPartitionsWithIndex((index,iterator) => {
val listBuffer: ListBuffer[String] = new ListBuffer
while (iterator.hasNext) {
listBuffer.append(index + "_" + iterator.next())
}
listBuffer.iterator
},false)
.foreach(println(_))
}运行结果
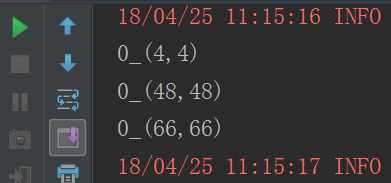
cogroup、sortBykey、aggregateByKey
cogroup
对两个RDD中的KV元素,每个RDD中相同key中的元素分别聚合成一个集合。与reduceByKey不同的是针对两个RDD中相同的key的元素进行合并。
jdk7
public static void cogroup(){
List<Tuple2<Integer, String>> list1 = Arrays.asList(
new Tuple2<Integer, String>(1, "www"),
new Tuple2<Integer, String>(2, "bbs")
);
List<Tuple2<Integer, String>> list2 = Arrays.asList(
new Tuple2<Integer, String>(1, "cnblog"),
new Tuple2<Integer, String>(2, "cnblog"),
new Tuple2<Integer, String>(3, "very")
);
List<Tuple2<Integer, String>> list3 = Arrays.asList(
new Tuple2<Integer, String>(1, "com"),
new Tuple2<Integer, String>(2, "com"),
new Tuple2<Integer, String>(3, "good")
);
JavaPairRDD<Integer, String> list1RDD = sc.parallelizePairs(list1);
JavaPairRDD<Integer, String> list2RDD = sc.parallelizePairs(list2);
JavaPairRDD<Integer, String> list3RDD = sc.parallelizePairs(list3);
list1RDD.cogroup(list2RDD,list3RDD).foreach(new VoidFunction<Tuple2<Integer, Tuple3<Iterable<String>, Iterable<String>, Iterable<String>>>>() {
@Override
public void call(Tuple2<Integer, Tuple3<Iterable<String>, Iterable<String>, Iterable<String>>> tuple) throws Exception {
System.out.println(tuple._1+" " +tuple._2._1() +" "+tuple._2._2()+" "+tuple._2._3());
}
});
}jdk8
public static void cogroup(){
List<Tuple2<Integer, String>> list1 = Arrays.asList(
new Tuple2<Integer, String>(1, "www"),
new Tuple2<Integer, String>(2, "bbs")
);
List<Tuple2<Integer, String>> list2 = Arrays.asList(
new Tuple2<Integer, String>(1, "cnblog"),
new Tuple2<Integer, String>(2, "cnblog"),
new Tuple2<Integer, String>(3, "very")
);
List<Tuple2<Integer, String>> list3 = Arrays.asList(
new Tuple2<Integer, String>(1, "com"),
new Tuple2<Integer, String>(2, "com"),
new Tuple2<Integer, String>(3, "good")
);
JavaPairRDD<Integer, String> list1RDD = sc.parallelizePairs(list1);
JavaPairRDD<Integer, String> list2RDD = sc.parallelizePairs(list2);
JavaPairRDD<Integer, String> list3RDD = sc.parallelizePairs(list3);
list1RDD.cogroup(list2RDD,list3RDD).foreach(tuple ->
System.out.println(tuple._1+" " +tuple._2._1() +" "+tuple._2._2()+" "+tuple._2._3()));
}scala
def cogroup(): Unit ={
val list1 = List((1, "www"), (2, "bbs"))
val list2 = List((1, "cnblog"), (2, "cnblog"), (3, "very"))
val list3 = List((1, "com"), (2, "com"), (3, "good"))
val list1RDD = sc.parallelize(list1)
val list2RDD = sc.parallelize(list2)
val list3RDD = sc.parallelize(list3)
list1RDD.cogroup(list2RDD,list3RDD).foreach(tuple =>
println(tuple._1 + " " + tuple._2._1 + " " + tuple._2._2 + " " + tuple._2._3))
}运行结果

sortBykey
sortByKey函数作用于Key-Value形式的RDD,并对Key进行排序。它是在org.apache.spark.rdd.OrderedRDDFunctions中实现的,实现如下
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.size)
: RDD[(K, V)] =
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}从函数的实现可以看出,它主要接受两个函数,含义和sortBy一样,这里就不进行解释了。该函数返回的RDD一定是ShuffledRDD类型的,因为对源RDD进行排序,必须进行Shuffle操作,而Shuffle操作的结果RDD就是ShuffledRDD。其实这个函数的实现很优雅,里面用到了RangePartitioner,它可以使得相应的范围Key数据分到同一个partition中,然后内部用到了mapPartitions对每个partition中的数据进行排序,而每个partition中数据的排序用到了标准的sort机制,避免了大量数据的shuffle。下面对sortByKey的使用进行说明:
jdk7
public static void sortByKey(){
List<Tuple2<Integer, String>> list = Arrays.asList(
new Tuple2<>(99, "张三丰"),
new Tuple2<>(96, "东方不败"),
new Tuple2<>(66, "林平之"),
new Tuple2<>(98, "聂风")
);
JavaPairRDD<Integer, String> listRDD = sc.parallelizePairs(list);
listRDD.sortByKey(false).foreach(new VoidFunction<Tuple2<Integer, String>>() {
@Override
public void call(Tuple2<Integer, String> tuple) throws Exception {
System.out.println(tuple._2+"->"+tuple._1);
}
});
}jdk8
public static void sortByKey(){
List<Tuple2<Integer, String>> list = Arrays.asList(
new Tuple2<>(99, "张三丰"),
new Tuple2<>(96, "东方不败"),
new Tuple2<>(66, "林平之"),
new Tuple2<>(98, "聂风")
);
JavaPairRDD<Integer, String> listRDD = sc.parallelizePairs(list);
listRDD.sortByKey(false).foreach(tuple ->System.out.println(tuple._2+"->"+tuple._1));
}scala
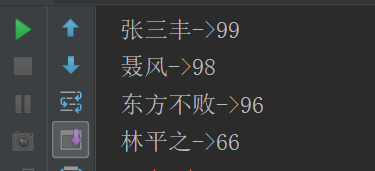
def sortByKey(): Unit ={
val list = List((99, "张三丰"), (96, "东方不败"), (66, "林平之"), (98, "聂风"))
sc.parallelize(list).sortByKey(false).foreach(tuple => println(tuple._2 + "->" + tuple._1))
}运行结果
aggregateByKey
aggregateByKey函数对PairRDD中相同Key的值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。和aggregate函数类似,aggregateByKey返回值的类型不需要和RDD中value的类型一致。因为aggregateByKey是对相同Key中的值进行聚合操作,所以aggregateByKey函数最终返回的类型还是Pair RDD,对应的结果是Key和聚合好的值;而aggregate函数直接是返回非RDD的结果,这点需要注意。在实现过程中,定义了三个aggregateByKey函数原型,但最终调用的aggregateByKey函数都一致。
jdk7
public static void aggregateByKey(){
List<String> list = Arrays.asList("you,jump", "i,jump");
JavaRDD<String> listRDD = sc.parallelize(list);
listRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(",")).iterator();
}
}).mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<>(word,1);
}
}).aggregateByKey(0, new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
}, new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1+i2;
}
}).foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tuple) throws Exception {
System.out.println(tuple._1+"->"+tuple._2);
}
});
}jdk8
public static void aggregateByKey() {
List<String> list = Arrays.asList("you,jump", "i,jump");
JavaRDD<String> listRDD = sc.parallelize(list);
listRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator())
.mapToPair(word -> new Tuple2<>(word,1))
.aggregateByKey(0,(x,y)-> x+y,(m,n) -> m+n)
.foreach(tuple -> System.out.println(tuple._1+"->"+tuple._2));
}scala
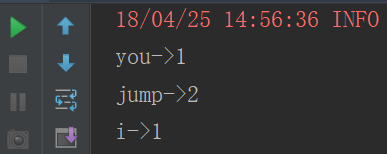
def aggregateByKey(): Unit ={
val list = List("you,jump", "i,jump")
sc.parallelize(list)
.flatMap(_.split(","))
.map((_, 1))
.aggregateByKey(0)(_+_,_+_)
.foreach(tuple =>println(tuple._1+"->"+tuple._2))
}运行结果
Spark学习之路 (六)Spark Transformation和Action[转]的更多相关文章
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习之路(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark针对Kafka的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8和spark-streaming-kafka-0-10,其主要区别如下: s ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
- Spark学习之路 (七)Spark 运行流程
一.Spark中的基本概念 (1)Application:表示你的应用程序 (2)Driver:表示main()函数,创建SparkContext.由SparkContext负责与ClusterMan ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark学习之路 (二)Spark2.3 HA集群的分布式安装
一.下载Spark安装包 1.从官网下载 http://spark.apache.org/downloads.html 2.从微软的镜像站下载 http://mirrors.hust.edu.cn/a ...
- Spark学习之路 (二十二)SparkStreaming的官方文档
官网地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html 一.简介 1.1 概述 Spark Streamin ...
- Spark学习之路(十四)—— Spark Streaming 基本操作
一.案例引入 这里先引入一个基本的案例来演示流的创建:获取指定端口上的数据并进行词频统计.项目依赖和代码实现如下: <dependency> <groupId>org.apac ...
- Spark学习之路 (八)SparkCore的调优之开发调优[转]
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
随机推荐
- TensorFlow中使用GPU
TensorFlow默认会占用设备上所有的GPU以及每个GPU的所有显存:如果指定了某块GPU,也会默认一次性占用该GPU的所有显存.可以通过以下方式解决: 1 Python代码中设置环境变量,指定G ...
- 2018icpc南京现场赛-I Magic Potion(最大流)
题意: n个英雄,m个怪兽,第i个英雄可以打第i个集合里的怪兽,一个怪兽可以在多个集合里 有k瓶药水,每个英雄最多喝一次,可以多打一只怪兽,求最多打多少只 n,m,k<=500 思路: 最大流, ...
- 版本控制工具-svn
两个疑问: 1.什么是版本控制? 2.为什么要用版本控制工具? 银联卡的特征: 1.受保护的 2.受约束的 如何与银联卡对应? 1.个人的代码--口袋里的钱 2.版本控制工具中的代码--银联卡里的钱 ...
- Go语言实现:【剑指offer】连续子数组的最大和
该题目来源于牛客网<剑指offer>专题. HZ偶尔会拿些专业问题来忽悠那些非计算机专业的同学.今天测试组开完会后,他又发话了:在古老的一维模式识别中,常常需要计算连续子向量的最大和,当向 ...
- MSSqlServer访问远程数据库
--第一部分(要点)--永久访问方式(需对访问远程数据库进行经常性操作)时设置链接数据库Exec sp_addlinkedserver 'MyLinkServer','','SQLOLEDB','远程 ...
- Unable to update index for nexus-publish | http://ip:port/repository/maven-public/
问题描述:Unable to update index for nexus-publish | http://ip:port/repository/maven-public/ 解决方案:进入工作空间. ...
- 杭电-------2041超级楼梯(c语言写)
/* 当未走的楼梯大于1时,可以选择走一步或者走两步,每次所做的选择相似, 符合分治法的特性,因此选择分治法,又测试用例有多组,为了避免多组 用例的重复计算,可用一个数组将已经知道的剩下的楼梯可以走的 ...
- 论文翻译:Speech Enhancement Based on the General Transfer Function GSC and Postfiltering
论文地址:基于通用传递函数GSC和后置滤波的语音增强 博客作者:凌逆战 博客地址:https://www.cnblogs.com/LXP-Never/p/12232341.html 摘要 在语音增强应 ...
- Leetcode:面试题 04.03. 特定深度节点链表
Leetcode:面试题 04.03. 特定深度节点链表 Leetcode:面试题 04.03. 特定深度节点链表 先贴一下自己写过一个模板,按层数遍历: https://www.cnblogs.co ...
- flyway使用简介
官网 https://flywaydb.org/ 背景 Flyway是独立于数据库的应用.管理并跟踪数据库变更的数据库版本管理工具.用通俗的话讲,Flyway可以像Git管理不同人的代码那样,管理不同 ...