processing data
获取有效数据
Scikit-learn will not accept categorical features by default
API里面不知使用默认的特征变量名,因此需要编码
这里我还是有疑问?
对于下载的数据集,一般的特征变量名,在进行分类的时候,机器是不能识别的,需要对特征名进行编码,因为计算机是二进制语言啊?Need to encode categorical features numerically
Convert to ‘dummy variables’
- 0: Observation was NOT that category
- 1: Observation was that category
Dealing with categorical features in Python
两种方式是一样的
- scikit-learn: OneHotEncoder()
- pandas: get_dummies()
pd.get_dummies
- 离散特征编码
- 可用来表示分类变量、非数量因素可能产生的影响
pandas加入虚拟变量的方式
get_dummies 是利用pandas实现one hot encode的方式。详细参数请查看官方文档
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)[source]
- data 要处理的DataFrame
- prefix 列名的前缀,在多个列有相同的离散项时候使用
- prefix_sep 前缀和离散值的分隔符,默认为下划线,默认即可
- dummy_na 是否把NA值,作为一个离散值进行处理,默认为不处理
- columns 要处理的列名,如果不指定该列,那么默认处理所有列
- drop_first 是否从备选项中删除第一个,建模的时候为避免共线性使用
Pandas中的get_dummy()函数是将拥有不同值的变量转换为0/1数值。
举例说明:一群样本的年龄分别为19,32,56,94岁,19岁用1表示,32岁用2表示,56岁用3表示,94岁用4表示。1,2,3,4这些数值的大小本身没有意义,只是用来区分年龄。因此在实际问题中,需要将1,2,3,4转化为0/1,即如果是19岁,则为0,若不是则为1,以此类推。
- 举个例子
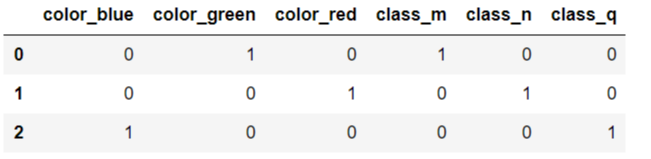
import pandas as pd
df = pd.DataFrame([
['green' , 'm'],
['red' , 'n'],
['blue' , 'q']])
df.columns = ['color', 'class']
pd.get_dummies(df)
# Create dummy variables: df_region
df_region = pd.get_dummies(df)
# Print the columns of df_region
print(df_region.columns)
# Drop 'Region_America' from df_region
df_region = pd.get_dummies(df, drop_first=True)
# Print the new columns of df_region
print(df_region)
处理缺失数据
Imputer()
- 填补缺失值:
sklearn.preprocessing.Imputer(missing_values=’NaN’, strategy=’mean’, axis=0, verbose=0, copy=True)
主要参数说明:
missing_values:缺失值,可以为整数或NaN(缺失值numpy.nan用字符串‘NaN’表示),默认为NaN
strategy:替换策略,字符串,默认用均值‘mean’替换
- 若为mean时,用特征列的均值替换
- 若为median时,用特征列的中位数替换
- 若为most_frequent时,用特征列的众数替换
axis:指定轴数,默认axis=0代表列,axis=1代表行
copy:设置为True代表不在原数据集上修改,设置为False时,就地修改,存在如下情况时,即使设置为False时,也不会就地修改
- X不是浮点值数组
- X是稀疏且missing_values=0
- axis=0且X为CRS矩阵
- axis=1且X为CSC矩阵
statistics_属性:axis设置为0时,每个特征的填充值数组,axis=1时,报没有该属性错误
参考
# Import the Imputer module
from sklearn.preprocessing import Imputer
from sklearn.svm import SVC
# Setup the Imputation transformer: imp
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
# Instantiate the SVC classifier: clf
clf = SVC()
# Setup the pipeline with the required steps: steps
steps = [('imputation', imp),
('SVM', clf)]
dropna()
直接删除缺失值
pipline
官方文档
连接多个转换器和预测器在一起,形成一个机器学习工作流,这句解释太官方了,因此我没懂
processing data的更多相关文章
- PatentTips - Data Plane Packet Processing Tool Chain
BACKGROUND The present disclosure relates generally to systems and methods for providing a data plan ...
- Becoming a Data Scientist – Curriculum via Metromap
From: http://nirvacana.com/thoughts/becoming-a-data-scientist/ Data Science, Machine Learning, Big D ...
- Monitoring and Tuning the Linux Networking Stack: Receiving Data
http://blog.packagecloud.io/eng/2016/06/22/monitoring-tuning-linux-networking-stack-receiving-data/ ...
- 基于Processing的数据可视化
虽然数据可视化领域有很多成熟.界面友好.功能强大的软件产品(例如Tableau.VIDI.NodeXL等),但是借助Processing我们可以基于Java语言框架进行丰富多元的可视化编程,熟悉了Pr ...
- Awesome Big Data List
https://github.com/onurakpolat/awesome-bigdata A curated list of awesome big data frameworks, resour ...
- IAB303 Data Analytics Assessment Task
Assessment TaskIAB303 Data Analyticsfor Business InsightSemester I 2019Assessment 2 – Data Analytics ...
- Python - 2. Built-in Collection Data Types
From: http://interactivepython.org/courselib/static/pythonds/Introduction/GettingStartedwithData.htm ...
- Stream processing with Apache Flink and Minio
转自:https://blog.minio.io/stream-processing-with-apache-flink-and-minio-10da85590787 Modern technolog ...
- [Windows Azure] Data Management and Business Analytics
http://www.windowsazure.com/en-us/develop/net/fundamentals/cloud-storage/ Managing and analyzing dat ...
随机推荐
- 蓝桥杯2015年省赛C/C++大学B组
1. 奖券数目 有些人很迷信数字,比如带“4”的数字,认为和“死”谐音,就觉得不吉利.虽然这些说法纯属无稽之谈,但有时还要迎合大众的需求.某抽奖活动的奖券号码是5位数(10000-99999),要求其 ...
- JAVA ReentrantLock的使用
源码如下 对比synchronized,synchronized使用时会显示的指定一个对象(方法为调用对象,代码块会需要对象作为参数),来获取一个对象的独占锁 而ReentrantLock可能就是使用 ...
- js - 面向对象 - 小案例:轮播图、随机点名、选项卡、鼠标拖拽
面向对象 对象 : (黑盒子)不了解内部结构, 知道表面的各种操作. 面向对象 : 不了解原理的情况下 会使用功能 . 面向对象是一种通用思想,并非编程中能用,任何事情都能用. 编程语言的面向对象的特 ...
- FastDFS 配置文件 client.conf storage_ids.conf
client.conf : # connect timeout in seconds # default value is 30s connect_timeout=30 连接 ...
- css架构技巧
1. 写一个reset.css 用于清除浏览器标签默认样式并定义全局样式,这样就不会因为浏览器默认样式出现问题,因为不同浏览器的默认样式还是不一样的
- Idea生成代码段
使用快捷键(ctrl+alt+s)找到:从idea的菜单File->Settings->Editor->Live Templates 先添加Template Group,然后添加Li ...
- Pch文件预编译
因为项目用到Pch文件链接宏变量,因而稍作研究怎样使用,define宏变量其实并不合适 ,static const才最适合 Pch文件听说是上古世纪存在的文件,主要是用来全局预编译文件统一在一个出口, ...
- 【转】Redis内部数据结构详解 -- skiplist
本文是<Redis内部数据结构详解>系列的第六篇.在本文中,我们围绕一个Redis的内部数据结构--skiplist展开讨论. Redis里面使用skiplist是为了实现sorted s ...
- Redis入门(介绍、搭建)——Windows、Centos环境
一.介绍 Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cac ...
- WPF 原生绑定和命令功能使用指南
WPF 原生绑定和命令功能使用指南 魏刘宏 2020 年 2 月 21 日 如今,当谈到 WPF 时,我们言必称 MVVM.框架(如 Prism)等,似乎已经忘了不用这些的话该怎么使用 WPF 了.当 ...