一文读懂MapReduce 附流量解析实例
1.MapReduce是什么
Hadoop MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。这个定义里面有着这些关键词,
一是软件框架,二是并行处理,三是可靠且容错,四是大规模集群,五是海量数据集。
2 MapReduce做什么
MapReduce擅长处理大数据,它为什么具有这种能力呢?这可由MapReduce的设计思想发觉。MapReduce的思想就是“分而治之”。
(1)Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:
一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
(2)Reducer负责对map阶段的结果进行汇总。至于需要多少个Reducer,用户可以根据具体问题,通过在mapred-site.xml配置文件里设置参数mapred.reduce.tasks的值,缺省值为1。
一个比较形象的语言解释MapReduce:
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。 现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
MapReduce流程
- inputFormat 先通过inputFormat 读进来
- InputSplit 然后通过split进行分片
- RecordReaders 简称RR 通过 recordReader读取切片
- map map处理 输出个临时结果
- Combiner 本机先做一次reduce 减少io 提升作业执行性能,但是也有缺点,如果做全局平均数 等就不准了
- shuffing - partitioner shuffing分发
- shuffing - sort shuffing排序
- reduce
- OutputFormat 最终输出
MapReduce的输入输出
MapReduce框架运转在<key,value>键值对上,也就是说,框架把作业的输入看成是一组<key,value>键值对,同样也产生一组<key,value>键值对作为作业的输出,这两组键值对有可能是不同的。
一个MapReduce作业的输入和输出类型如下图所示:可以看出在整个流程中,会有三组<key,value>键值对类型的存在。
MapReduce的处理流程
这里以WordCount单词计数为例,介绍map和reduce两个阶段需要进行哪些处理。单词计数主要完成的功能是:统计一系列文本文件中每个单词出现的次数,如图所示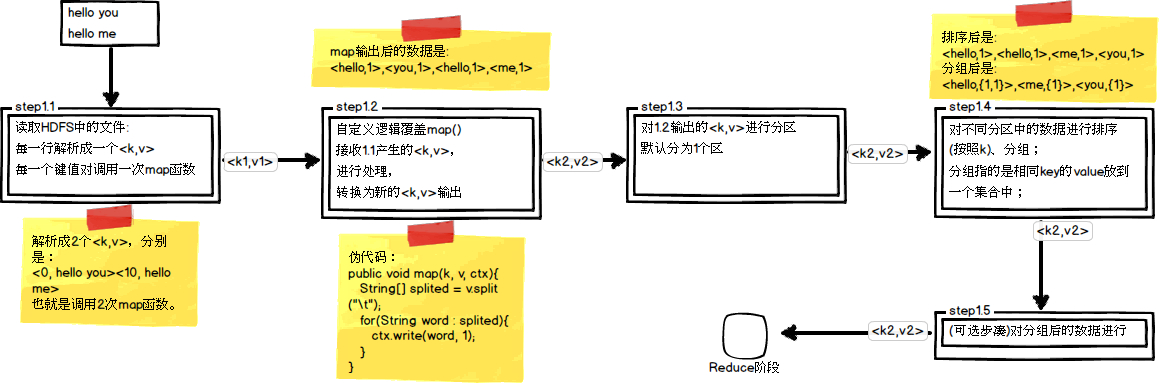
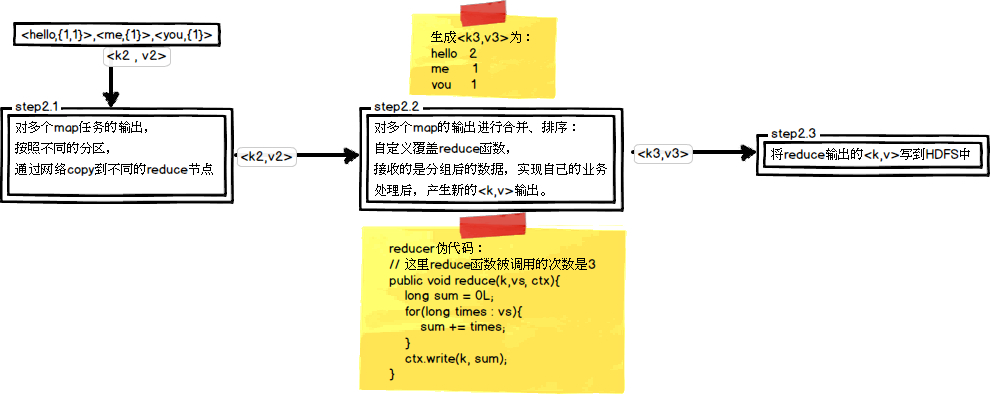
编写一个简单的 WordCount mapReduce 脚本
编写map脚本
- //继承mapper类
- /**
- * KEYIN, Map任务读数据的key类型,offset,是每行数据起始位置的偏移量 Long
- * VALUEIN, Map任务读取数据的 value类型 就是一行行字符串 String
- * KEYOUT, map方法自定义实现输出key类型
- * VALUEOUT map方法自定义实现输出value类型
- *
- * hello world welcome
- * hello welcome
- * keyout String valueout int
- * (world,1)
- * hadoop 会有自定义类型 支持序列化和反序列化
- */
- public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
- //自定义map 把自己需要的数据截取出来 然后交给后续步骤来做
- @Override
- protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- //多个单词用 空格拆开
- String[] words = value.toString().split("-");
- for(String word:words) {
- context.write(new Text(word),new IntWritable(1));
- }
- }
- }
编写Reduce
- /**
- * Reduce 的输入是map的输出
- * KEYIN, VALUEIN, KEYOUT, VALUEOUT 输入是 word,1 输出是 word,3 都是 string,int
- */
- public class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
- /**
- *
- * @param key 对应的单词
- * @param values 可以迭代的value 相同的key都会分发到一个reduce上面去 类似于 (hello,<1,1,1,1>)
- * @param context
- * @throws IOException
- * @throws InterruptedException
- */
- @Override
- protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
- int count = 0;
- Iterator<IntWritable> iterator = values.iterator();
- while(iterator.hasNext()) {
- IntWritable value = iterator.next();
- //累加
- count += value.get();
- }
- context.write(key,new IntWritable(count));
- }
- }
创建Job 运行
- //windows需要设置 hadoop.home.dir
- System.setProperty("hadoop.home.dir", "D:\\javaroot\\soft\\hadoop-2.6.0-cdh5.15.1");
- //设置hadoop帐号
- System.setProperty("HADOOP_USER_NAME","hadoop");
- Configuration configuration = new Configuration();
- configuration.set("fs.defaultFS","hdfs://192.168.1.100:8020");
- //提交个作业
- Job job = Job.getInstance(configuration);
- //设置job对应的主类
- job.setJarByClass(App.class);
- //添加 Combiner
- job.setCombinerClass(WordCountReduce.class);
- //设置自定义的mapper类型
- job.setMapperClass(WordCountMapper.class);
- job.setReducerClass(WordCountReduce.class);
- //设置输出类型
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- //设置reduce输出
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- //设置输入和输出的路径
- FileInputFormat.setInputPaths(job, new Path("/demo/wordcount/input"));
- FileOutputFormat.setOutputPath(job,new Path("/demo/wordcount/output"));
- //提交job
- boolean res = job.waitForCompletion(true);
- System.exit(res ? 0 :1);
实例:解析流量日志 算出每个手机号 上行和下行的流量和总流量
数据log
- 1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
- 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
- 1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
- 1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
- 1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
- 1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200
- 1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
- 1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200
- 1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200
- 1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200
- 1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200
- 1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200
- 1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200
- 1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200
- 1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash2-http.qq.com 综合门户 15 12 1938 2910 200
- 1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200
- 1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200
- 1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200
- 1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200
- 1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200
- 1363157985066 13726238888 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
- 1363157993055 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
- 1363157985066 13726238888 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 10000 20000 200
代码实现
- //map类
- public class AccessMapper extends Mapper<LongWritable,Text,Text,Access> {
- //把日志按切分 找到需要的三个字段
- @Override
- protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- String[] lines = value.toString().split("\t");
- String phone = lines[1];
- long up = Long.parseLong(lines[lines.length - 3]);
- long down = Long.parseLong(lines[lines.length - 2]);
- context.write(new Text(phone),new Access(phone,up,down,(up+down)));
- }
- }
- //reduce 类
- public class AccessReduce extends Reducer<Text,Access,NullWritable,Access> {
- /**
- * @param key 手机号
- * @param values Access
- * @param context
- * @throws IOException
- * @throws InterruptedException
- */
- @Override
- protected void reduce(Text key, Iterable<Access> values, Context context) throws IOException, InterruptedException {
- long ups = 0;
- long downs = 0;
- for (Access access:values) {
- ups += access.getUp();
- downs += access.getDown();
- }
- context.write(NullWritable.get(),new Access(key.toString(),ups,downs,(ups+downs)));
- }
- }
- //job 执行
- public static void main(String[] args) throws Exception {
- //windows需要设置 hadoop.home.dir
- System.setProperty("hadoop.home.dir", "D:\\javaroot\\soft\\hadoop-2.6.0-cdh5.15.1");
- //设置hadoop帐号
- // System.setProperty("HADOOP_USER_NAME","hadoop");
- Configuration configuration = new Configuration();
- //configuration.set("fs.defaultFS","hdfs://192.168.1.100:8020");
- Job job = Job.getInstance(configuration);
- job.setJarByClass(App.class);
- job.setMapperClass(AccessMapper.class);
- job.setReducerClass(AccessReduce.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(Access.class);
- job.setOutputKeyClass(NullWritable.class);
- job.setOutputValueClass(Access.class);
- //设置输入和输出的路径
- FileInputFormat.setInputPaths(job, new Path("input"));
- FileOutputFormat.setOutputPath(job,new Path("output"));
- //提交job
- boolean res = job.waitForCompletion(true);
- System.exit(res ? 0 :1);
- }
最后执行结果
- phone='13480253104', up=180, down=180, sum=360
- phone='13502468823', up=7335, down=110349, sum=117684
- phone='13560436666', up=1116, down=954, sum=2070
- phone='13560439658', up=2034, down=5892, sum=7926
- phone='13602846565', up=1938, down=2910, sum=4848
- phone='13660577991', up=6960, down=690, sum=7650
- phone='13719199419', up=240, down=0, sum=240
- phone='13726230503', up=2481, down=24681, sum=27162
- phone='13726238888', up=12481, down=44681, sum=57162
- phone='13760778710', up=120, down=120, sum=240
- phone='13826544101', up=264, down=0, sum=264
- phone='13922314466', up=3008, down=3720, sum=6728
- phone='13925057413', up=11058, down=48243, sum=59301
- phone='13926251106', up=240, down=0, sum=240
- phone='13926435656', up=132, down=1512, sum=1644
- phone='15013685858', up=3659, down=3538, sum=7197
- phone='15920133257', up=3156, down=2936, sum=6092
- phone='15989002119', up=1938, down=180, sum=2118
- phone='18211575961', up=1527, down=2106, sum=3633
- phone='18320173382', up=9531, down=2412, sum=11943
- phone='84138413', up=4116, down=1432, sum=5548
一文读懂MapReduce 附流量解析实例的更多相关文章
- 一文读懂MapReduce
Hadoop解决大规模数据分布式计算的方案是MapReduce.MapReduce既是一个编程模型,又是一个计算框架.也就是说,开发人员必须基于MapReduce编程模型进行编程开发,然后将程序通过M ...
- [转帖]MerkleDAG全面解析 一文读懂什么是默克尔有向无环图
MerkleDAG全面解析 一文读懂什么是默克尔有向无环图 2018-08-16 15:58区块链/技术 MerkleDAG作为IPFS的核心数据结构,它融合了Merkle Tree和DAG的优点,今 ...
- [转帖]一文读懂 HTTP/2
一文读懂 HTTP/2 http://support.upyun.com/hc/kb/article/1048799/ 又小拍 • 发表于:2017年05月18日 15:34:45 • 更新于:201 ...
- 一文读懂HTTP/2及HTTP/3特性
摘要: 学习 HTTP/2 与 HTTP/3. 前言 HTTP/2 相比于 HTTP/1,可以说是大幅度提高了网页的性能,只需要升级到该协议就可以减少很多之前需要做的性能优化工作,当然兼容问题以及如何 ...
- 从HTTP/0.9到HTTP/2:一文读懂HTTP协议的历史演变和设计思路
本文原作者阮一峰,作者博客:ruanyifeng.com. 1.引言 HTTP 协议是最重要的互联网基础协议之一,它从最初的仅为浏览网页的目的进化到现在,已经是短连接通信的事实工业标准,最新版本 HT ...
- [转帖]从HTTP/0.9到HTTP/2:一文读懂HTTP协议的历史演变和设计思路
从HTTP/0.9到HTTP/2:一文读懂HTTP协议的历史演变和设计思路 http://www.52im.net/thread-1709-1-2.html 本文原作者阮一峰,作者博客:r ...
- kubernetes基础——一文读懂k8s
容器 容器与虚拟机对比图(左边为容器.右边为虚拟机) 容器技术是虚拟化技术的一种,以Docker为例,Docker利用Linux的LXC(LinuX Containers)技术.CGroup(Co ...
- 一文读懂神经网络训练中的Batch Size,Epoch,Iteration
一文读懂神经网络训练中的Batch Size,Epoch,Iteration 作为在各种神经网络训练时都无法避免的几个名词,本文将全面解析他们的含义和关系. 1. Batch Size 释义:批大小, ...
- 一文读懂AI简史:当年各国烧钱许下的愿,有些至今仍未实现
一文读懂AI简史:当年各国烧钱许下的愿,有些至今仍未实现 导读:近日,马云.马化腾.李彦宏等互联网大佬纷纷亮相2018世界人工智能大会,并登台演讲.关于人工智能的现状与未来,他们提出了各自的观点,也引 ...
随机推荐
- vue用法父组件调用子组件方法--->$refs
vue下载excel模板(放入弹框独立出来)后再导入表格 子组件 <el-dialog title="导入" :visible.sync="dialogVisibl ...
- win2d 画出好看的图形
本文告诉大家,win2d 不需要从零开始做,以前做出来的很多库其实只需要做很小修改就可以做出好看的效果,而且用在 UWP 上.本文修改原先 大神写的 GDI 图形到 win2d 上,而且可以运行起来 ...
- 1471 - Defense Lines
After the last war devastated your country, you - as the king of the land of Ardenia - decided it wa ...
- zeppelin开启多个
conf/zeppelin-env.sh 添加行: export ZEPPELIN_PID_DIR=/xx/zeppelin/run_2
- liunx printk 函数消息是如何记录的
printk 函数将消息写入一个 LOG_BUF_LEN 字节长的环形缓存, 长度值从 4 KB 到 1 MB, 由配置内核时选择. 这个函数接着唤醒任何在等待消息的进程, 就是说, 任何在系统 ...
- 【codeforces 749A】Bachgold Problem
time limit per test1 second memory limit per test256 megabytes inputstandard input outputstandard ou ...
- H3C网络监测工具命令
1.Debugging 2.Display debugging 3.Display diagnostic-information display diagnostic-information 命令用来 ...
- 【11.61%】【codeforces 670F】Restore a Number
time limit per test2 seconds memory limit per test256 megabytes inputstandard input outputstandard o ...
- BGP团体属性的应用案例
XRV1 ===================================================================== version 15.5service times ...
- 【k8s】kubeadm快速部署Kubernetes
1.Kubernetes 架构图 kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具. 这个工具能通过两条指令完成一个kubernetes集群的部署: # 创建一个 Mast ...