Logback源码分析
在日常开发中经常通过打印日志记录程序执行的步骤或者排查问题,如下代码类似很多,但是,它是如何执行的呢?
package chapters;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
// 省略...
Logger logger = LoggerFactory.getLogger(LogbackTest.class);
logger.info(" {} is best player in world", "Greizmann");
本文以Logback日志框架来分析以上代码的实现。
slf4j
如今日志框架常用的有log4j、log4j2、jul(common-log)以及logback。假如项目中用的是jul,如今想改成用log4j,如果直接引用java.util.logging包中Logger,需要修改大量代码,为了解决这个麻烦的事情,Ceki Gülcü 大神开发了slf4j(Simple Logging Facade for Java) 。slf4j 是众多日志框架抽象的门面接口,有了slf4j 想要切换日志实现,只需要把对应日志jar替换和添加对应的适配器。
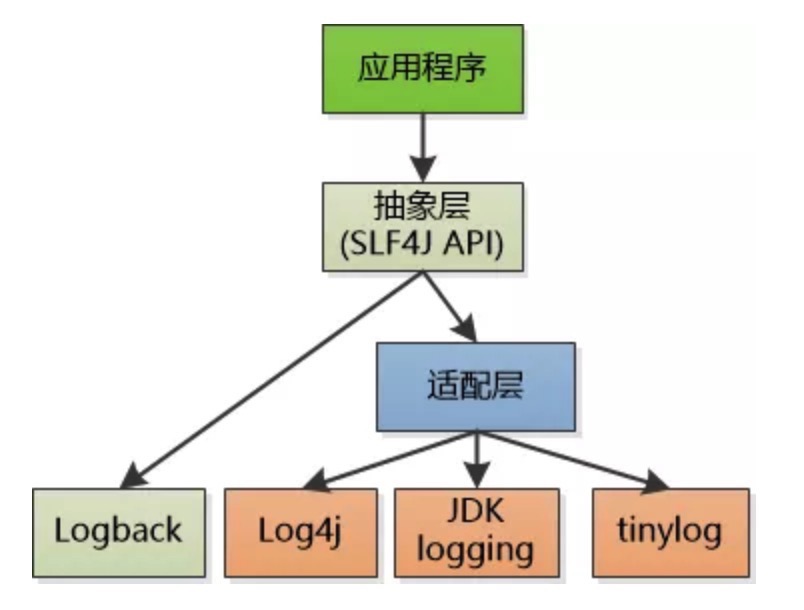
> 图片来源: [一个著名的日志系统是怎么设计出来的?](https://mp.weixin.qq.com/s/XiCky-Z8-n4vqItJVHjDIg)
从图中就可以知道我们开始的代码为什么引 slf4j 包。在阿里的开发手册上一条
强制:应用中不可直接使用日志系统(log4j、logback)中的 API ,而应依赖使用日志框架 SLF4J 中的 API 。使用门面模式的日志框架,有利于维护和各个类的日志处理方式的统一。
Logback 实现了 SLF4J ,少了中间适配层, Logback也是Ceki Gülcü 大神开发的。
Logger & Appender & Layouts
Logback 主要的三个类 logger,appender和layouts。这三个组件一起作用可以满足我们开发中根据消息的类型以及日志的级别打印日志到不同的地方。
Logger
ch.qos.logback.classic.Logger类结构:
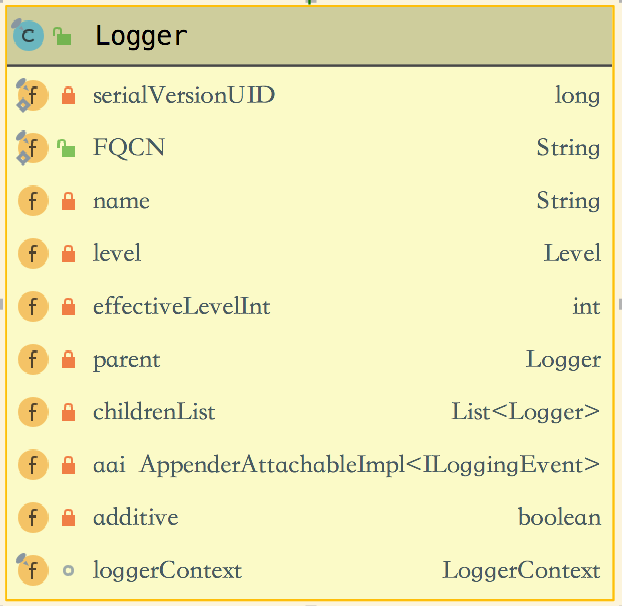
Logger 依附在LoggerContext上,LoggerContext负责生产Logger,通过一个树状的层次结构来进行管理。Logger 维护着当前节点的日志级别及level值。logger按 "." 分代(层级),日志级别有继承能力,如:名字为 chapters.LogbackTest 如果没有设置日志级别,会继承它的父类chapters 日志级别。所有日志的老祖宗都是ROOT名字的Logger,默认DEBUG级别。当前节点设置了日志级别不会考虑父类的日志级别。Logger 通过日志级别控制日志的启用和禁用。日志级别 TRACE < DEBUG < INFO < WARN < ERROR。
接下来我们结合配置文件看一下Logger属性对应的配置标签:
<configuration>
<turboFilter class="ch.qos.logback.classic.turbo.MDCFilter">
<MDCKey>username</MDCKey>
<Value>sebastien</Value>
<OnMatch>ACCEPT</OnMatch>
</turboFilter>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>/Users/wolf/study/logback/logback-examples/myApp.log</file>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<logger name="chapters.LogbackTest" level="DEBUG"></logger>
<root>
<appender-ref ref="FILE"/>
</root>
</configuration>
name:logger 标签中 name 属性值。
level:logger 标签中 level 属性值。
parent:封装了父类 "chapters",以及"chapters"的父类“ROOT”的logger对象。
aai:appender-ref 标签,及这里对应 FileAppender 的实现类对象。如果没有appender-ref标签该值为null。
loggerContext:维护着过滤器,如 turbo 过滤器等。
Appender
Appender 作用是控制日志输出的目的地。日志输出的目的地是多元化,你可以把日志输出到console、file、remote socket server、MySQL、PostgreSQL、Oracle 或者其它的数据库、JMS、remote UNIX Syslog daemons 中。一个日志可以输出到多个目的地。如
<configuration>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>/Users/wolf/study/logback/logback-examples/myApp.log</file>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<root>
<appender-ref ref="STDOUT" />
<appender-ref ref="FILE"/>
</root>
</configuration>
该xml配置把日志输出到了myApp.log文件和console中。
Layouts/Encoder
有上面Logger和Appender两大组件,日志已经输出到目的地了,但是这样打印的日志对我们这种凡人不太友好,读起来费劲。凡人就要做到美观,那就用Layouts或Encoder美化一下日志输出格式吧。Encoder 在 logback 0.9.19 版本引进。在之前的版本中,大多数的 appender 依赖 layout 将日志事件转换为 string,然后再通过 java.io.Writer 写出。在之前的版本中,用户需要在 FileAppender 中内置一个 PatternLayout。在 0.9.19 之后的版本中,FileAppender 以及子类需要一个 encoder 而不是 layout。
源码
Logger创建
Logger logger = LoggerFactory.getLogger(LogbackTest.class);
接下来我们根据源码分析一下logger的初始化。分析源码之前还是按照老规矩来一张接口调用时序图吧。
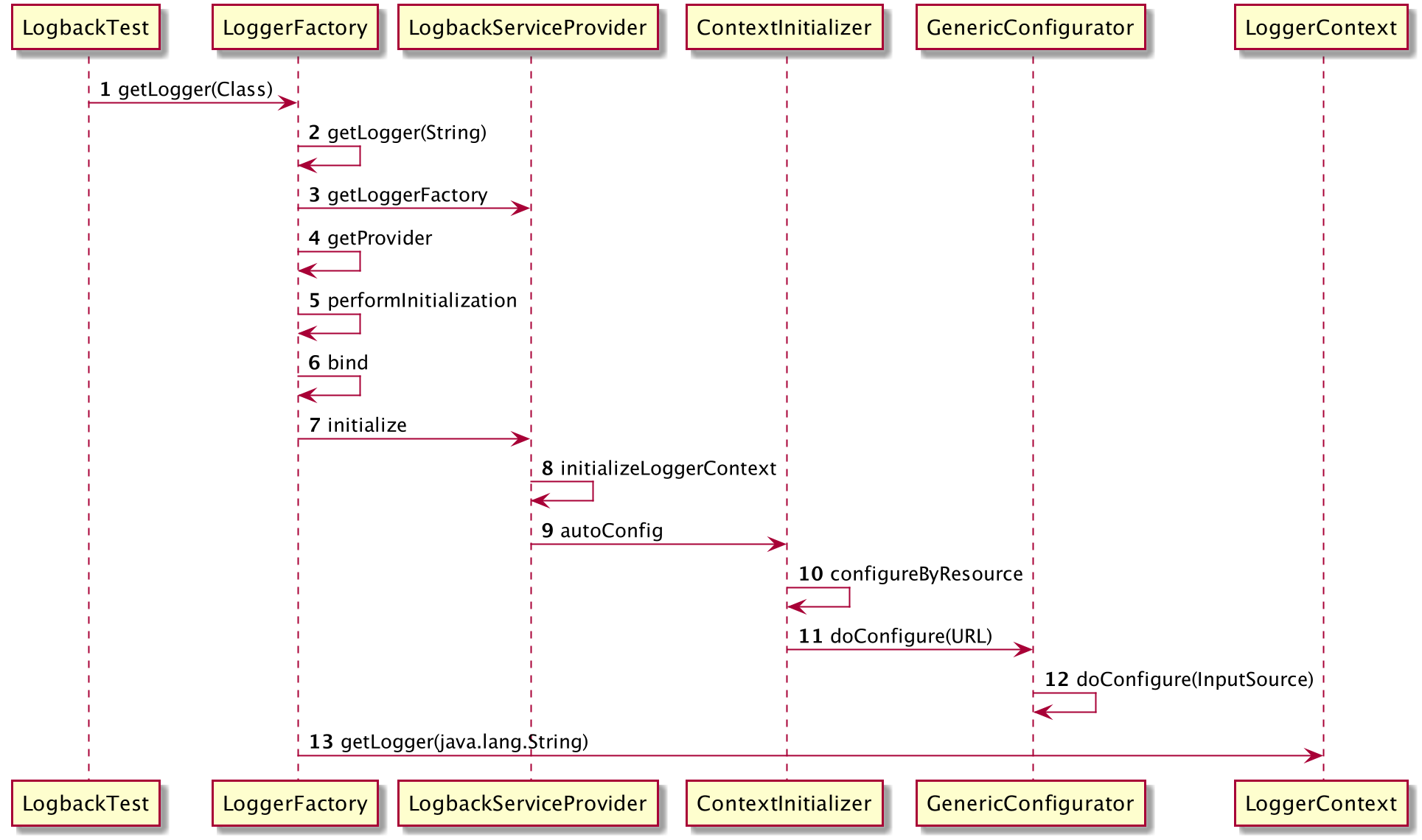
第步:org.slf4j.LoggerFactory#getLogger(java.lang.String)
public static Logger getLogger(String name) {
ILoggerFactory iLoggerFactory = getILoggerFactory();
return iLoggerFactory.getLogger(name);
}
获取一个ILoggerFactory,即LoggerContext。然后从其获取到Logger对象。
第3步:org.slf4j.LoggerFactory#getILoggerFactory
public static ILoggerFactory getILoggerFactory() {
return getProvider().getLoggerFactory();
}
第4步:org.slf4j.LoggerFactory#getProvider
static SLF4JServiceProvider getProvider() {
if (INITIALIZATION_STATE == UNINITIALIZED) {
synchronized (LoggerFactory.class) {
if (INITIALIZATION_STATE == UNINITIALIZED) {
INITIALIZATION_STATE = ONGOING_INITIALIZATION;
performInitialization();
}
}
}
switch (INITIALIZATION_STATE) {
case SUCCESSFUL_INITIALIZATION:
return PROVIDER;
case NOP_FALLBACK_INITIALIZATION:
return NOP_FALLBACK_FACTORY;
case FAILED_INITIALIZATION:
throw new IllegalStateException(UNSUCCESSFUL_INIT_MSG);
case ONGOING_INITIALIZATION:
return SUBST_PROVIDER;
}
throw new IllegalStateException("Unreachable code");
}
对SLF4JServiceProvider初始化,即LogbackServiceProvider对象。然后检查初始化状态,如果成功就返回PROVIDER。
第5步:org.slf4j.LoggerFactory#performInitialization
private final static void performInitialization() {
bind();
if (INITIALIZATION_STATE == SUCCESSFUL_INITIALIZATION) {
versionSanityCheck();
}
}
第6步:org.slf4j.LoggerFactory#bind
private final static void bind() {
try {
// 加载 SLF4JServiceProvider
List<SLF4JServiceProvider> providersList = findServiceProviders();
reportMultipleBindingAmbiguity(providersList);
if (providersList != null && !providersList.isEmpty()) {
PROVIDER = providersList.get(0);
// SLF4JServiceProvider.initialize()
PROVIDER.initialize();
INITIALIZATION_STATE = SUCCESSFUL_INITIALIZATION;
reportActualBinding(providersList);
fixSubstituteLoggers();
replayEvents();
SUBST_PROVIDER.getSubstituteLoggerFactory().clear();
} else {
// 省略代码。。。
}
} catch (Exception e) {
// 失败,设置状态值,上报
failedBinding(e);
throw new IllegalStateException("Unexpected initialization failure", e);
}
}
通过ServiceLoader加载LogbackServiceProvider,然后进行初始化相关字段。初始化成功后把初始化状态设置成功状态值。
第7步:ch.qos.logback.classic.spi.LogbackServiceProvider#initialize
public void initialize() {
// 初始化默认的loggerContext
defaultLoggerContext = new LoggerContext();
defaultLoggerContext.setName(CoreConstants.DEFAULT_CONTEXT_NAME);
initializeLoggerContext();
markerFactory = new BasicMarkerFactory();
mdcAdapter = new LogbackMDCAdapter();
}
创建名字为default的LoggerContext对象,并初始化一些字段默认值。
ch.qos.logback.classic.LoggerContext#LoggerContext
public LoggerContext() {
super();
this.loggerCache = new ConcurrentHashMap<String, Logger>();
this.loggerContextRemoteView = new LoggerContextVO(this);
this.root = new Logger(Logger.ROOT_LOGGER_NAME, null, this);
this.root.setLevel(Level.DEBUG);
loggerCache.put(Logger.ROOT_LOGGER_NAME, root);
initEvaluatorMap();
size = 1;
this.frameworkPackages = new ArrayList<String>();
}
初始化LoggerContext时设置了ROOT的Logger,日志级别为DEBUG。
第8步:ch.qos.logback.classic.spi.LogbackServiceProvider#initializeLoggerContext
private void initializeLoggerContext() {
try {
try {
new ContextInitializer(defaultLoggerContext).autoConfig();
} catch (JoranException je) {
Util.report("Failed to auto configure default logger context", je);
}
// 省略代码。。。
} catch (Exception t) { // see LOGBACK-1159
Util.report("Failed to instantiate [" + LoggerContext.class.getName() + "]", t);
}
}
把第7步初始化好的LoggerContext当做参数传入ContextInitializer,构建其对象。然后解析配置文件。
第9步:ch.qos.logback.classic.util.ContextInitializer#autoConfig
public void autoConfig() throws JoranException {
StatusListenerConfigHelper.installIfAsked(loggerContext);
// (1) 从指定路径获取
URL url = findURLOfDefaultConfigurationFile(true);
if (url != null) {
configureByResource(url);
} else {
// (2) 从运行环境中获取
Configurator c = EnvUtil.loadFromServiceLoader(Configurator.class);
if (c != null) {
// 省略代码。。。
} else {
// (3)设置默认的
BasicConfigurator basicConfigurator = new BasicConfigurator();
basicConfigurator.setContext(loggerContext);
basicConfigurator.configure(loggerContext);
}
}
}
首先从指定的路径获取资源URL,如果存在就进行解析;如果不存在再从运行环境中获取配置;如果以上都没有最后会构建一个BasicConfigurator当作默认的。
ch.qos.logback.classic.util.ContextInitializer#findURLOfDefaultConfigurationFile
public URL findURLOfDefaultConfigurationFile(boolean updateStatus) {
ClassLoader myClassLoader = Loader.getClassLoaderOfObject(this);
// 启动参数中获取
URL url = findConfigFileURLFromSystemProperties(myClassLoader, updateStatus);
if (url != null) {
return url;
}
// logback-test.xml
url = getResource(TEST_AUTOCONFIG_FILE, myClassLoader, updateStatus);
if (url != null) {
return url;
}
//logback.groovy
url = getResource(GROOVY_AUTOCONFIG_FILE, myClassLoader, updateStatus);
if (url != null) {
return url;
}
// logback.xml
return getResource(AUTOCONFIG_FILE, myClassLoader, updateStatus);
}
先从启动参数中查找logback.configurationFile参数值,如果没有再从classpath中一次查找logback-test.xml -> logback.groovy -> logback.xml 。由此可知文件的优先级是 启动参数 -> logback-test.xml -> logback.groovy -> logback.xml
第10步:ch.qos.logback.classic.util.ContextInitializer#configureByResource
public void configureByResource(URL url) throws JoranException {
if (url == null) {
throw new IllegalArgumentException("URL argument cannot be null");
}
final String urlString = url.toString();
if (urlString.endsWith("groovy")) {
// 省略代码。。。
} else if (urlString.endsWith("xml")) {
JoranConfigurator configurator = new JoranConfigurator();
configurator.setContext(loggerContext);
configurator.doConfigure(url);
} else {
// 省略代码。。。
}
}
根据文件后缀判断是 groovy或者xml,然后交给不同的配置解析器处理。这里也是把第7步中的LoggerContext传进去,继续封装它的字段值。
第12步:ch.qos.logback.core.joran.GenericConfigurator#doConfigure(org.xml.sax.InputSource)
public final void doConfigure(final InputSource inputSource) throws JoranException {
long threshold = System.currentTimeMillis();
SaxEventRecorder recorder = new SaxEventRecorder(context);
recorder.recordEvents(inputSource);
// 处理配置文件,封装到 LoggerContext 中
playEventsAndProcessModel(recorder.saxEventList);
StatusUtil statusUtil = new StatusUtil(context);
if (statusUtil.noXMLParsingErrorsOccurred(threshold)) {
registerSafeConfiguration(recorder.saxEventList);
}
}
真正解析配置文件的逻辑在playEventsAndProcessModel方法中,这里就不展开分析了。到这一步LoggerContext基本初始化完成了。
第13步:ch.qos.logback.classic.LoggerContext#getLogger(java.lang.String)
@Override
public Logger getLogger(final String name) {
// 省略代码。。。
if (Logger.ROOT_LOGGER_NAME.equalsIgnoreCase(name)) {
return root;
}
int i = 0;
Logger logger = root;
// 从缓存中获取, 有直接返回
Logger childLogger = (Logger) loggerCache.get(name);
if (childLogger != null) {
return childLogger;
}
// if the desired logger does not exist, them create all the loggers
// in between as well (if they don't already exist)
String childName;
while (true) {
int h = LoggerNameUtil.getSeparatorIndexOf(name, i);
if (h == -1) {
childName = name;
} else {
childName = name.substring(0, h);
}
// move i left of the last point
i = h + 1;
synchronized (logger) {
childLogger = logger.getChildByName(childName);
if (childLogger == null) {
childLogger = logger.createChildByName(childName);
loggerCache.put(childName, childLogger);
incSize();
}
}
logger = childLogger;
if (h == -1) {
return childLogger;
}
}
}
经过前面漫长的对LoggerContext进行初始化工作,这一步就是从LoggerContext获取Logger对象。如果缓存中直接返回。否则通过“.”分代构建层次结构。
日志执行步骤
上一节Logger创建完成,接下来分析一下打日志的流程。
logger.info(" {} is best player in world", "Greizmann");

第1步:ch.qos.logback.classic.Logger#info(java.lang.String, java.lang.Object)
public void info(String format, Object arg) {
filterAndLog_1(FQCN, null, Level.INFO, format, arg, null);
}
把接口的日志级别(Level.INFO)传到下一个方法。
第2步:ch.qos.logback.classic.Logger#filterAndLog_1
private void filterAndLog_1(final String localFQCN, final Marker marker, final Level level, final String msg, final Object param, final Throwable t) {
// 先通过turboFilter过滤
final FilterReply decision = loggerContext.getTurboFilterChainDecision_1(marker, this, level, msg, param, t);
// 判断日志级别
if (decision == FilterReply.NEUTRAL) {
if (effectiveLevelInt > level.levelInt) {
return;
}
} else if (decision == FilterReply.DENY) {
return;
}
buildLoggingEventAndAppend(localFQCN, marker, level, msg, new Object[] { param }, t);
}
如果TurboFilter过滤器存在就会执行相关操作,并返回FilterReply。如果结果是FilterReply.DENY本条日志消息直接丢弃;如果是FilterReply.NEUTRAL会继续判断日志级别是否在该方法级别之上;如果是FilterReply.ACCEPT直接跳到下一步。
第3步:ch.qos.logback.classic.Logger#buildLoggingEventAndAppend
private void buildLoggingEventAndAppend(final String localFQCN, final Marker marker, final Level level, final String msg, final Object[] params, final Throwable t) {
LoggingEvent le = new LoggingEvent(localFQCN, this, level, msg, t, params);
le.setMarker(marker);
callAppenders(le);
}
创建了LoggingEvent对象,该对象包含日志请求所有相关的参数,请求的 logger,日志请求的级别,日志信息,与日志一同传递的异常信息,当前时间,当前线程,以及当前类的各种信息和 MDC。其实打印日志就是一个事件,所以这个对象是相关重要,下面全部是在操作该对象。
第4步:ch.qos.logback.classic.Logger#callAppenders
public void callAppenders(ILoggingEvent event) {
int writes = 0;
// 从自己往父辈查找满足
for (Logger l = this; l != null; l = l.parent) {
// 写文件
writes += l.appendLoopOnAppenders(event);
if (!l.additive) {
break;
}
}
// No appenders in hierarchy
if (writes == 0) {
loggerContext.noAppenderDefinedWarning(this);
}
}
第5步:ch.qos.logback.classic.Logger#appendLoopOnAppenders
private int appendLoopOnAppenders(ILoggingEvent event) {
if (aai != null) {
return aai.appendLoopOnAppenders(event);
} else {
return 0;
}
}
从当前Logger到父节点遍历,直到AppenderAttachableImpl不为空(有appender-ref 标签)。
第6步:ch.qos.logback.core.spi.AppenderAttachableImpl#appendLoopOnAppenders
public int appendLoopOnAppenders(E e) {
int size = 0;
final Appender<E>[] appenderArray = appenderList.asTypedArray();
final int len = appenderArray.length;
for (int i = 0; i < len; i++) {
appenderArray[i].doAppend(e);
size++;
}
return size;
}
如果设置了多个日志输出目的地,这里就是循环调用对应的Appender进行输出。
第7步:ch.qos.logback.core.UnsynchronizedAppenderBase#doAppend
public void doAppend(E eventObject) {
if (Boolean.TRUE.equals(guard.get())) {
return;
}
try {
guard.set(Boolean.TRUE);
if (!this.started) {
if (statusRepeatCount++ < ALLOWED_REPEATS) {
addStatus(new WarnStatus("Attempted to append to non started appender [" + name + "].", this));
}
return;
}
if (getFilterChainDecision(eventObject) == FilterReply.DENY) {
return;
}
this.append(eventObject);
} catch (Exception e) {
if (exceptionCount++ < ALLOWED_REPEATS) {
addError("Appender [" + name + "] failed to append.", e);
}
} finally {
guard.set(Boolean.FALSE);
}
}
通过ThreadLocal控制递归导致的重复提交
第8步:ch.qos.logback.core.OutputStreamAppender#append
protected void append(E eventObject) {
if (!isStarted()) {
return;
}
subAppend(eventObject);
}
第9步:ch.qos.logback.core.OutputStreamAppender#subAppend
protected void subAppend(E event) {
if (!isStarted()) {
return;
}
try {
if (event instanceof DeferredProcessingAware) {
// 拼接日志信息(填充占位符),设置当前线程以及MDC等信息
((DeferredProcessingAware) event).prepareForDeferredProcessing();
}
byte[] byteArray = this.encoder.encode(event);
writeBytes(byteArray);
} catch (IOException ioe) {
this.started = false;
addStatus(new ErrorStatus("IO failure in appender", this, ioe));
}
}
Encoder在这里惨淡登场,返回byte数组。
第10步:ch.qos.logback.core.encoder.LayoutWrappingEncoder#encode
public byte[] encode(E event) {
String txt = layout.doLayout(event);
return convertToBytes(txt);
}
Encoder先把LoggerEvent交给Layout,Layout组装日志信息,在每条信息后加上换行符。
第11步:ch.qos.logback.core.OutputStreamAppender#writeBytes
private void writeBytes(byte[] byteArray) throws IOException {
if(byteArray == null || byteArray.length == 0)
return;
lock.lock();
try {
this.outputStream.write(byteArray);
if (immediateFlush) {
this.outputStream.flush();
}
} finally {
lock.unlock();
}
}
使用AQS锁控制并发问题。这也是Logback性能不如 Log4j2的原因。后面有时间分析一下Log4j2。
本文到此结束了,还有两天就要放假了,祝大家新年快乐。
Logback源码分析的更多相关文章
- Spring Security 源码分析(四):Spring Social实现微信社交登录
社交登录又称作社会化登录(Social Login),是指网站的用户可以使用腾讯QQ.人人网.开心网.新浪微博.搜狐微博.腾讯微博.淘宝.豆瓣.MSN.Google等社会化媒体账号登录该网站. 前言 ...
- java 日志体系(四)log4j 源码分析
java 日志体系(四)log4j 源码分析 logback.log4j2.jul 都是在 log4j 的基础上扩展的,其实现的逻辑都差不多,下面以 log4j 为例剖析一下日志框架的基本组件. 一. ...
- supervisor启动worker源码分析-worker.clj
supervisor通过调用sync-processes函数来启动worker,关于sync-processes函数的详细分析请参见"storm启动supervisor源码分析-superv ...
- commons-logging + log4j源码分析
分析之前先理清楚几个概念 Log4J = Log For Java SLF4J = Simple Logging Facade for Java 看到Facade首先想到的就是设计模式中的门面(Fac ...
- DolphinScheduler1.2.1源码分析
DolphinScheduler在2020年2月24日发布了新版本1.2.1,从版本号就可以看出,这是一个小版本.主要涉及BUG修复.功能增强.新特性三个方面,我们会根据其发布内容,做简要的源码分析. ...
- DolphinScheduler源码分析之任务日志
DolphinScheduler源码分析之任务日志 任务日志打印在调度系统中算是一个比较重要的功能,下面就简要分析一下其打印的逻辑和前端页面查询的流程. AbstractTask 所有的任务都会继承A ...
- 【Spring源码分析】预备篇
前言 最新想学习一下Spring源码,开篇博客记录下学习过程,欢迎一块交流学习. 作为预备篇,主要演示搭建一个最简单的Spring项目样例,对Spring进行最基本梳理. 构建一个最简单的spring ...
- 精尽Spring Boot源码分析 - 日志系统
该系列文章是笔者在学习 Spring Boot 过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring Boot 源码分析 GitHub 地址 进行阅读 Sprin ...
- 精尽Spring Boot源码分析 - @ConfigurationProperties 注解的实现
该系列文章是笔者在学习 Spring Boot 过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring Boot 源码分析 GitHub 地址 进行阅读 Sprin ...
随机推荐
- 安装scipy失败提示lapack not found
从python库网站下载numpy+mkl合集包通过pip安装在下载scipy安装包通过pip安装即可
- H3C RIP可选配置
- vue组件中data是个函数
当我们const vm = new Vue({ el : '#app', data : { msg:‘hello World’ } })用习惯了,data是一个对象,可到了vue组件 Vue.co ...
- tf.train.match_filenames_once()
文件匹配之用 官方解释: 调用样例: https://bbs.csdn.net/topics/392271556 返回值样例:
- P1066 汪老师玩卡片
题目描述 汪老师得到了一些卡片,这些卡片上标有数字0或5.现在他可以选择其中一些卡片排成一列,使得排出的一列数字组成的数最大,且满足被90整除这个条件.同时这个数不能含有前导0,即0不能作为这串数的首 ...
- JS的防抖与节流学习笔记
防抖(debounce):当持续触发事件时,在一定的时间段内,只有最后一次触发的事件才会执行. 例: function debounce(fn, wait) { var timer = null; r ...
- VMware下配置Linux IP,解决Linux ping不通
因为安装好VMware8.0后,把VMware服务都设成手动的了,导致有些功能不好使,费了半天劲, 如果安装Linux时选择DHCP自动分配IP,需要启动服务: VMware DHCP service ...
- Sending Packets LightOJ - 1321 (期望计算)
题面: Alice and Bob are trying to communicate through the internet. Just assume that there are N route ...
- 2018-2-13-win10-uwp-判断文件存在
title author date CreateTime categories win10 uwp 判断文件存在 lindexi 2018-2-13 17:23:3 +0800 2018-2-13 1 ...
- codeforces 1136E 线段树
codeforces 1136E: 题意:给你一个长度为n的序列a和长度为n-1的序列k,序列a在任何时候都满足如下性质,a[i+1]>=ai+ki,如果更新后a[i+1]<ai+ki了, ...